论文链接:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123460205.pdf
Transformer之前在NLP领域大放异彩,但是在CV界平平无奇。自从ECCV20这篇基于transformer的目标检测模型DETR发表以后,transformer在CV中应用的探索越来越广泛,今天先粗浅的解读一下这篇论文,剩下的慢慢学习。
在目标检测领域,Faster RCNN无疑是最经典的模型之一。但他需要很多anchor,proposal,以及非常复杂的后处理NMS过程,这些操作是比较冗余且耗时的。于是作者提出了一个simple的pipeline来实现目标检测,这个pipeline即文中的DETR。
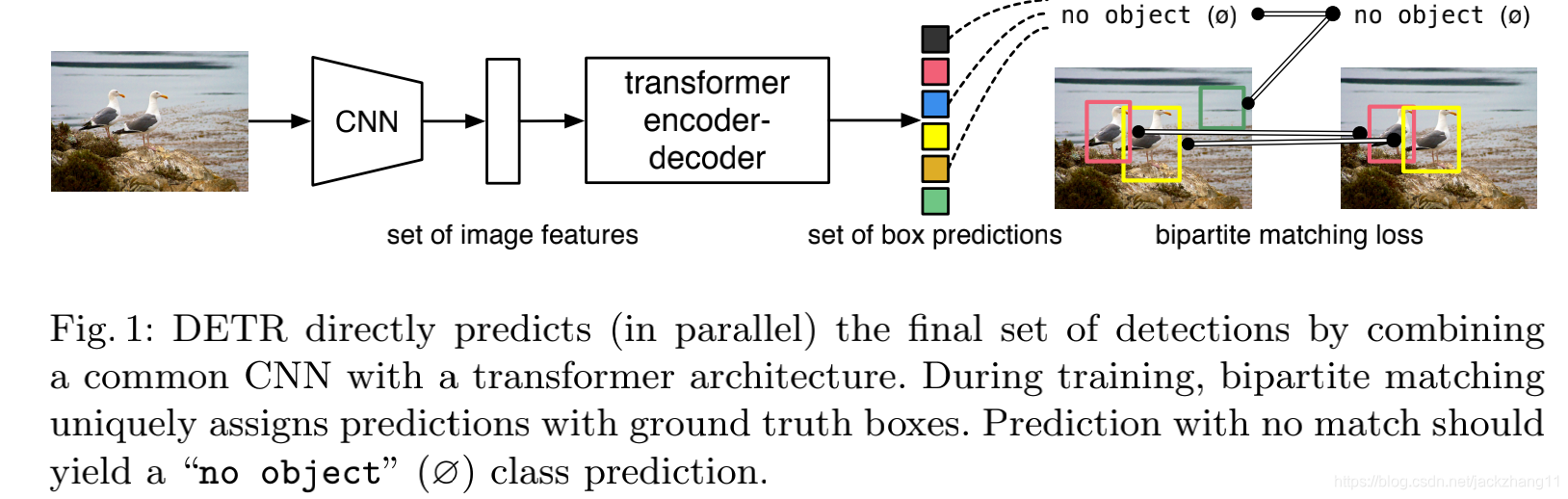
这个DETR的流程非常的清晰简洁:首先一张image作为input,通过一个CNN进行特征提取,得到一张feature map;随后将feature map的二维拆成一维,当作序列数据喂入有着encoder-decoder结构的transformer,得到若干个( N N N个,足够大,比一张图中出现最多的目标数要大)prediction box,包括了bbox的位置向量以及类别向量。最后将prediction与GT之间进行二分图匹配,利用匈牙利算法计算loss,实现end-to-end的训练。损失函数如下:
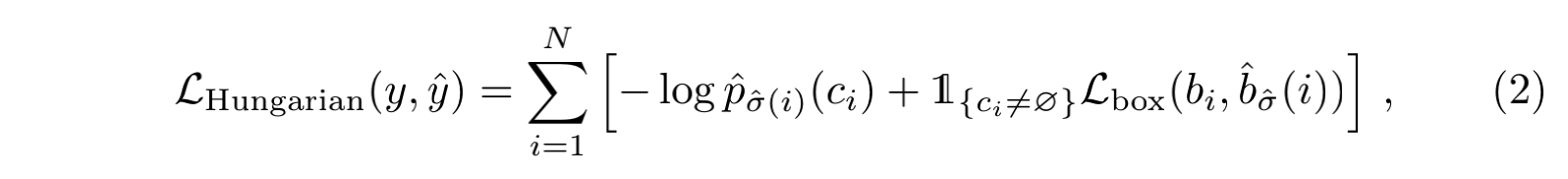
下面谈一下DETR每个部分的结构:
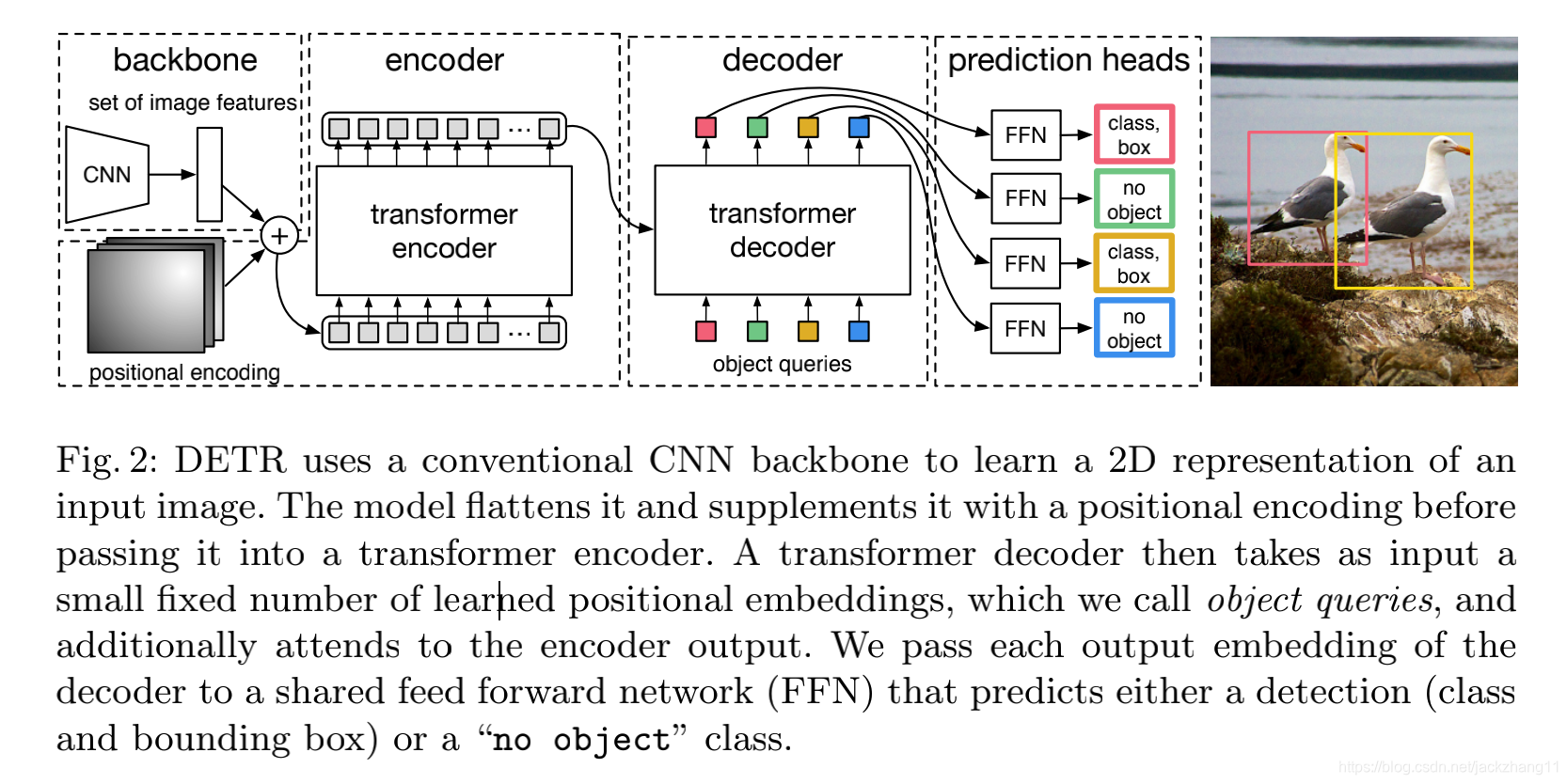
(1)backbone:一个CNN网络,对输入image进行特征提取,得到下采样过后的特征图;
(2)encoder:首先用一个1*1的卷积降维,接着毁掉特征图的二维空间结构,变为一维的特征图结构。然后送进若干个encoder layer,每一个encoder layer包含一个多头self-attention模块和一个FFN。由于transformer的结构是没有空间位置关系的( permutation-invariant),所以在每一个attention层都加一个position encoding,这里的位置编码是通过正余弦和位置计算出来的固定值(与下面的object query区分);
(3)decoder:

上图个人认为对decoder的理解很有帮助,之前encoder得到的输出,position encoding和object query作为decoder的输入。值得注意的是,object query相当于一种可学习的编码(在代码中表示为nn.Embedding),有一些表示物体在图像中位置的一维,其维度为 N N N,表示通过decoder会产生出 N N N个output embedding;
(4)FFN:将上述每一个output embedding分别喂入3层的MLP,得到每个box的中心坐标,宽高,以及类别向量等信息。
实验部分我感觉非常棒,特别详细而且discussion也很到位,在此不做赘述了,有兴趣的小伙伴可以看下论文,这里就贴一张表:
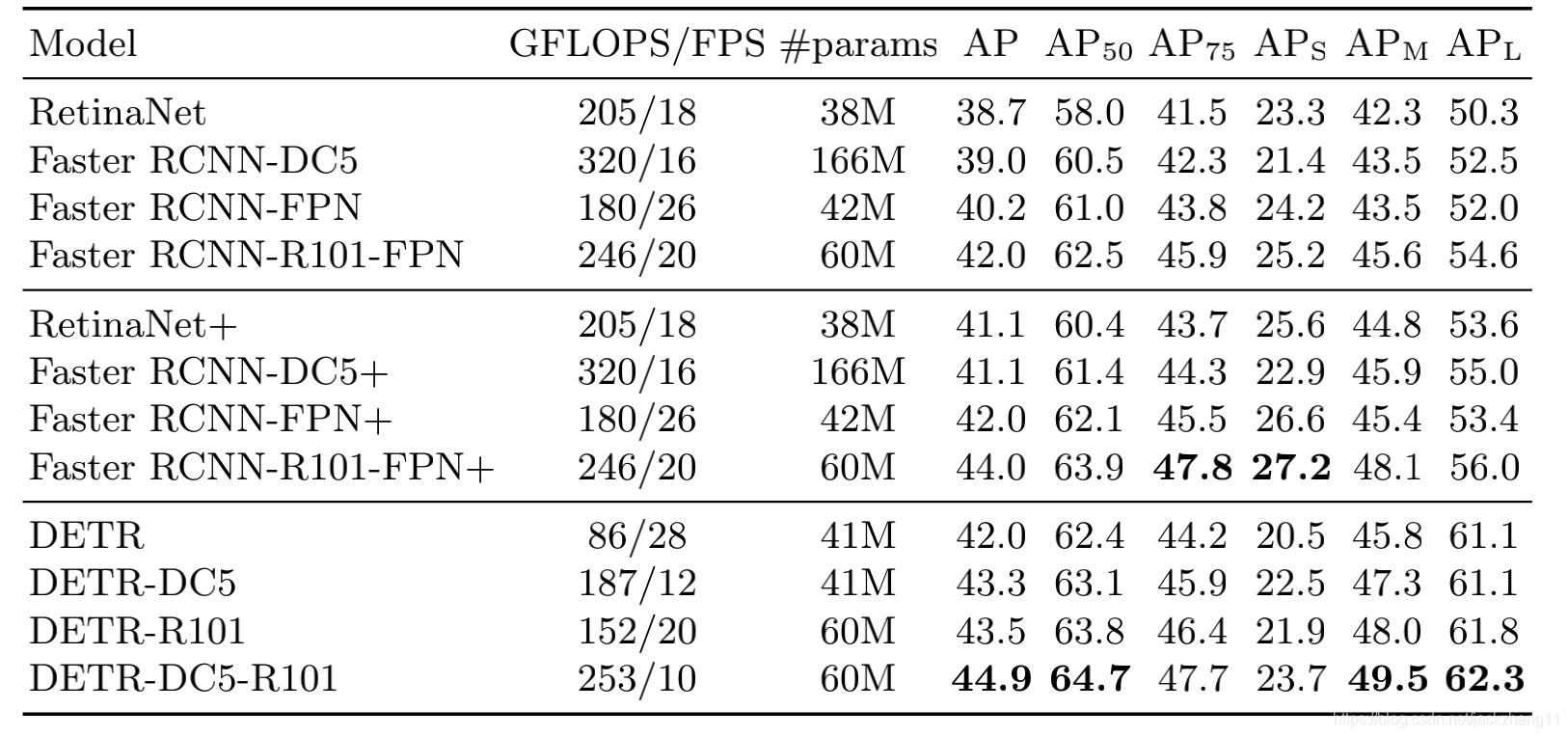
DETR和FasterRCNN相比的优缺点:
(1)transformer属于non-local,因此在全局的感知上要优于CNN。在DETR中对于大目标的检测效果好于FasterRCNN;但由于CNN结构是感受野逐层堆叠的,因此FasterRCNN在小目标检测上面优于DETR;
(2)transformer的整个pipeline更加简洁,没有了手动设置的anchor和复杂的后处理NMS过程,比FasterRCNN要简单;但是在训练方面的速度会比较爆炸,这也是后续产生deformable DETR的原因之一,这篇论文下一篇博客简单说一下。
以上是个人对这篇文章一些粗鄙的认知,如有不当请指正。
references:
https://www.zhihu.com/question/397624847