NIN: Network In Network
摘要:我们提出了一个名为‘Network In Network (NIN)’的深度网络,去提高模型对于局部感受野的local pathes的判别力。传统的卷积层使用线性filters结构。取而代之,我们构建了一个更复杂的神经网络结构去abstract局部感受野的data。我们使用通用近似模块MLP来构建这个复杂神经网络。改进后的网络的feature maps的计算方式与CNN一致使用滑动窗的方式。深度NIN通过堆叠多个上述结构来实现。除了用微型网络增强网络的局部建模能力,在分类任务中,我们还实施了全局平均池化over feature maps,全局平均池化很容易去解释并且不容易过拟合than FC。NIN在CIFAR-10、CIIFAR-100取得了state of art,在SVHN和MNIST上取得了不错的性能。
关键点:mlpconv层,global average pooling层
文章总结:
NIN改进了传统的CNN,采用了少量参数就取得了超过AlexNet的性能,AlexNet网络参数大小是230M,NIN只需要29M。本文的最主要贡献是改进了CNN。
1. 为什么要在conv前加MLP?
卷积层对下层的数据快来说是一个GLM(generalized linear model,广义线性模型),作者认为广义线性模型的抽象层次较低。作者认为“特征是不变的”,即同一概念的不同变种的特征是相同的。当sample的latent概念是线性可分时,CNN的抽象是合理的。但同一概念的数据一般是存在于一个非线性流形中,因此特征和输入之间的关系是一个高度非线性的函数。这就是作者使用MLP来增强conv的原因。
传统的CNN用超完备滤波器来提取潜在特征:使用大量的滤波器来提取某个特征,把所有可能的提取出来,这样就可以把我想要提取的特征也覆盖到。这种通过增加滤波器数量的办法会增大网络的计算量和参数量。
2. mlpconv层(创新点1)
CNN高层特征是低层特征通过某种运算的组合。所以作者提出了局部感受野中进行更复杂的运算。mlpconv层可以看成局部感受野上进行conv运算之前,还进行mlp运算。
作者将改进后的层称为mlpconv层,并将其和CNN进行了对比。下图是结构对比图:
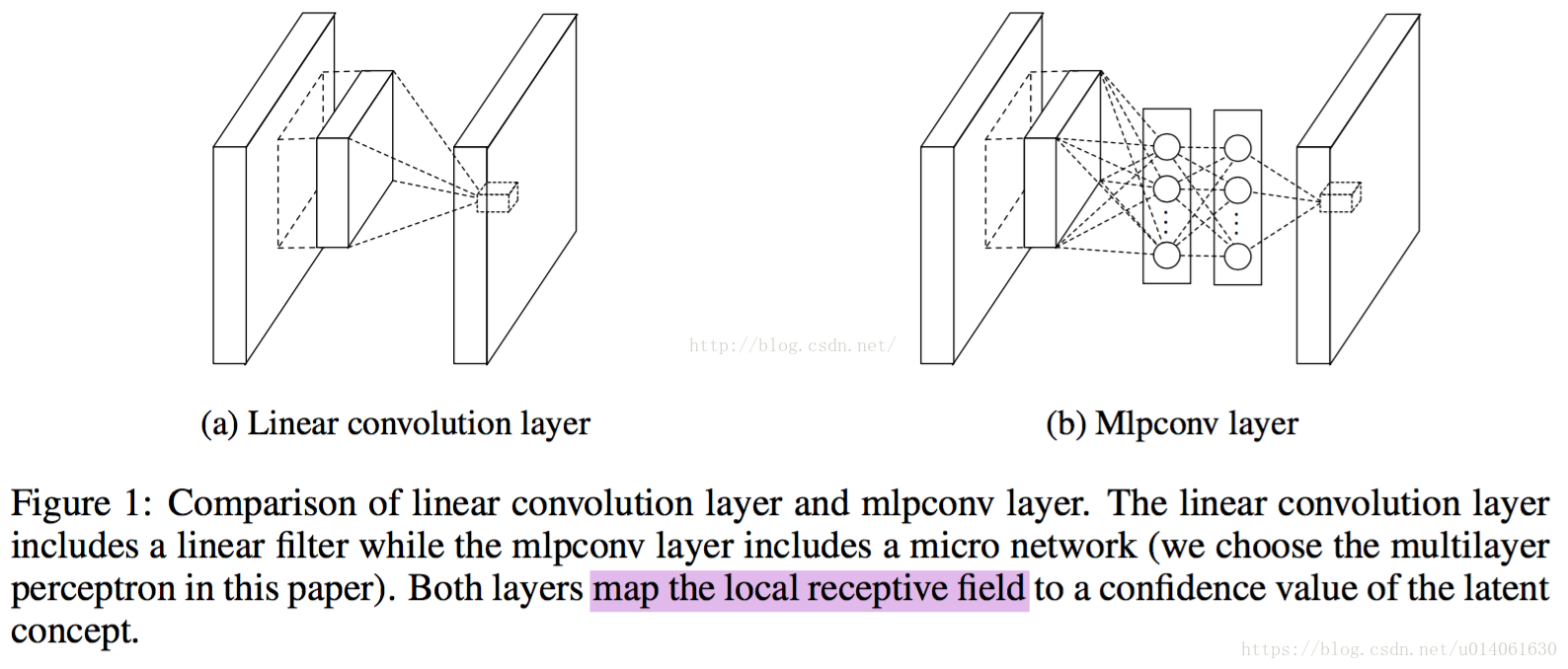
改进后的mlpconv层的计算方式和conv层类似,通过将mlp+filter滑过整个输入,最终得到feature maps。
从图上可以看到,每个局部感受野的神经元进行了更复杂的运算。
其实NIIN和Maxout的想法有很多相似的地方,但是mlpconv相比maxout更巧妙
3. 全局平局池化层(创新点2)
在NIN网络中,作者用feature maps的空间池化(spatial average)代替了常用的FC层,这种池化被成为全局平均池化(global average pool)。作者将全局平均池化层的输出当做各类别的概率。使用FC(黑箱)时很难解释各类别的概率信息是怎么反向传播回前面的卷积层的。全局平均池化层有实际意义,它将feature maps和类别对应起来。并且,FC层容易过拟合并且严重依赖Dropout正则。
传统的卷积网络用卷积提取特征,然后得到的特征再用FC+softmax逻辑回归分类层进行分类。使用全局平均池化层,每个特征图作为一个输出。这样参数量大大减小,并且每一个特征图相当于一个输出特征(表示输出类的特征)。
AlexNet网络的参数很大一部分来自于FC,本文用全局平均池化层取代FC,大大减少了参数量,所以,NIN在性能超AleNet的情况下,参数量从230M降到29M,很大一部分的减少来自于FC的去除。
4. NIN网络架构
NIN架构主要的创新点是mlpconv层和global average pooling层。下面将给出这两个部分的数学公式。
传统conv层的数学表达式
单个感受野上的计算:

是feature maps的channel的index
是像素在feature map里的index
mlpconv层的数学表达式
单个感受野上的计算:
这里 是mlp的层数,这里mlp层用的激活函数是ReLU
从跨通道池化(cross channel (cross feature map) pooling)的角度来看,上面的公式等效于在一个正常的卷积层上实施级联跨通道加权池化(cascaded cross channel parametric pooling)。池化层对输入的feature map进行加权线性求和,然后用ReLU进行激活 。这种级联跨通道加权池化使得模型能够学习到通道之间的关系
这种跨通道加权池化也等效于1x1卷积层。这个解释使得理解NIN的结构变得容易
一般来说mlp是一个3层的网络结构。
global average pooling层的数学表达式
在全局平均池化层,将最后一层的每一个feature map的平均值,然后将平均值组成的向量输入到softmax层。
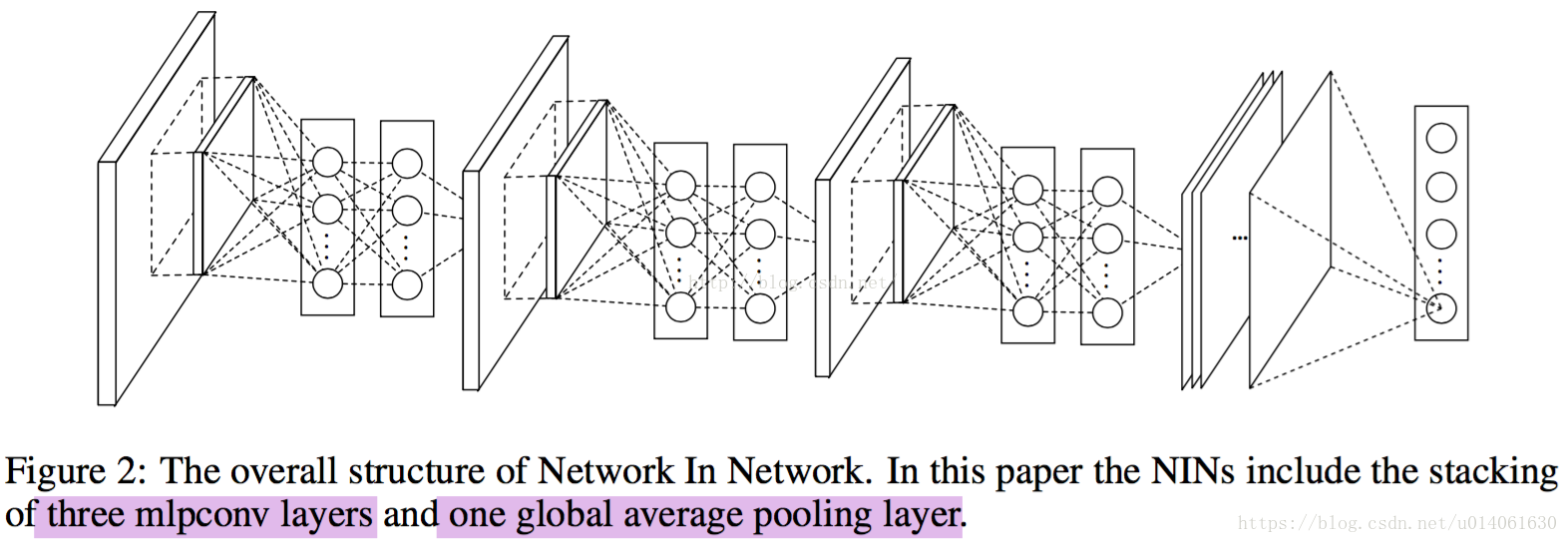
网络架构图
NIN文章使用的网络架构如图(总计4层):3层的mlpconv + 1层global_average_pooling。
作者提供了NIN的 Caffe版模型,感兴趣的可以查看。
下面是TensorFlow实现的NIN网络:
#coding:utf-8
import tensorflow as tf
def print_activation(x):
print(x.op.name, x.get_shape().as_list())
def inference(inputs,
num_classes=10,
is_training=True,
dropout_keep_prob=0.5,
scope='inference'):
with tf.variable_scope(scope):
x = inputs
print_activation(x)
with tf.variable_scope('mlpconv1'):
x = tf.layers.Conv2D(192, [5,5], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(160, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(96, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.nn.max_pool(x, [1,3,3,1], [1,2,2,1], padding='SAME')
print_activation(x)
if is_training:
with tf.variable_scope('dropout1'):
x = tf.nn.dropout(x, keep_prob=0.5)
print_activation(x)
with tf.variable_scope('mlpconv2'):
x = tf.layers.Conv2D(192, [5,5], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(192, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(192, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.nn.max_pool(x, [1,3,3,1], [1,2,2,1], padding='SAME')
print_activation(x)
if is_training:
with tf.variable_scope('dropout2'):
x = tf.nn.dropout(x, keep_prob=0.5)
print_activation(x)
with tf.variable_scope('mlpconv3'):
x = tf.layers.Conv2D(192, [3,3], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(192, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
x = tf.layers.Conv2D(10, [1,1], padding='SAME', activation=tf.nn.relu, kernel_regularizer=l2_regularizer(0.0001))(x)
print_activation(x)
with tf.variable_scope('global_average_pool'):
x = tf.reduce_mean(x, reduction_indices=[1,2])
print_activation(x)
x = tf.nn.softmax(x)
print_activation(x)
return x
if __name__ == '__main__':
x = tf.placeholder(tf.float32,[None,32,32,3])
logits = inference(inputs=x,
num_classes=10,
is_training=True)
'''
也许有人问为什么用1x1卷积实现NIN,这个其实在作者文章的3.2节已经阐述了。懒得翻原文的,查看本博客中,加粗的两段文字。
'''mlpconv和maxout的对比:
maxout可以拟合任意的凸激活函数,所以maxout对samples是凸集的情况很有效。mlpconv层与maxout层假设凸函数的情况不同的是,它采用了通用拟合函数MLP而不是凸函数,所以mlpconv适用于各种分布的latent concepts。