- 论文链接: https://arxiv.org/pdf/1312.4400v3.pdf
- 论文题目:Network In Network
Network In Network
Introduction
CNN的卷积核对于其所卷积的data patch来说其实本质上是一个广义线性模型(generalized linear model,GLM),而GLM本身它的对于特征的表达能力以及抽象等级是偏低的。抽象来说,特征是不变的对于同一概念的变体。如果将GLM替换成一个更为有效的非线性函数逼近那么将会提高局部模型的抽象表达能力。当潜在概念的样本是线性可分的时候,GLM会取得很好的效果,完成很好的抽象,比如概念的变体都位于GLM定义的分割超平面的一侧。因此,传统的CNN其实隐式地制定了假设,也就是潜在概念是线性可分的。然而同一概念下的数据往往位于非线性流形当中,因此这些概念的抽象表达往往是输入的高度非线性方程。在NIN中,GLM被一个“微网络”(micro network)结构所代替,它是一个非线性方程逼近。在本篇当中,选择多层感知机(multilayer perceptron)作为微网络的实例,因为它是一个通用函数逼近而且可以用BP进行训练。
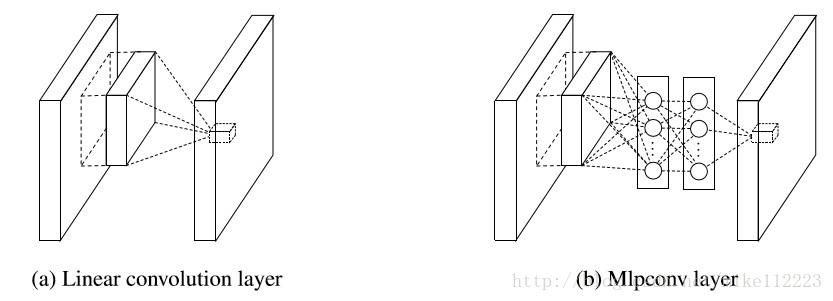
这个最终网络结构被叫做mlpconv层,下图是该层与传统卷积层的比较。同样都是将局部感受野映射为一个输出特征向量。mlpconv加入了带有非线性激活函数的FC layers。这也就是Network In Network 名字的由来,网络中的网络。
当然有别于传统的CNN会在最后接上FC进行分类,NIN经过一个全局average pooling层直接输出最后一层mlpconv层的特征图的spatial average作为分类依据,然后将最终的向量输入进softmax完成分类。在传统的CNN中,因为FC layers仿佛黑盒子般的存在,很难说明白,分类层的信息是怎么样从损失函数传播到之前的卷积层的。相反,全局平均池化会更具有意义且更容易阐明,因为它加强了特征图与分类别的联系,这都是使用了微网络这一更强大的局部模型让这一切成为可能。还有,本身FC layers会非常容易过拟合而且严重依赖于dropout这一泛化手段,而全局平均池化本身就有泛化作用能够自然的防止整个结构的过拟合。
Convolutional Neural Networks
刚刚讲到线性卷积当潜在概念的实例是线性可分时,是足够用来进行抽象的。但是好的抽象表达往往是输入数据的高度非线性方程。传统CNN,为了弥补就需要运用超完备的卷积核来覆盖所有潜在概念的变体。也就是说,单独的线性卷积核会经过训练来反映同一概念的不同变体。然后,对于同一概念拥有太多的卷积核将对网络的下一层施加很大的压力,因为下一层需要考虑上一层带来的变体的所有结合。在CNN中,越高层的卷积核映射于原输入更大的范围。它会结合低层的概念去生成更高层次的概念。因此,我们认为在结合低层概念去生成高层概念之前,对局部patch进行更好的抽象将会带来益处。
近期出现的maxout网络,通过对于仿射特征图(仿射特征图是线性卷积的直接结果,没有经过激活函数)的最大值池化减小了特征图的数量。对于线性方程的最大值化会完成一个分段线性逼近,可以拟合任意的凸函数,相比于传统卷积层完成的线性可分,maxout网络会更好地分割位于凸集的概念。
然而maxout网络也是强加了潜在概念实例是位于输入空间的凸集里的这一先验,实际上这并不一定。所以有必要施以一个更为普世一般的方程逼近,当潜在概念的分布非常复杂的时候。于是我们通过引入新的NIN结构来试图完成这一任务。
NIN从一个更为普世的角度出发,将微网络植入进CNN结构中来寻求所有层特征的更好的抽象。
Network In Network
MLP Convolution Layers
对于潜在概念分布没有任何的先验的情况下,理想的是运用一个通用的函数逼近来完成局部patches的特征提取,因为它会更好的逼近潜在概念的抽象表达。径向基网络(Radial Basis Network)和多层感知机是两个著名的通用函数逼近。我们选择MLP是因为:
- MLP和CNN兼容的很好,而且可以运用BP算法。
- MLP本身也是一个深层模型,这与特征复用的精神一致。
mlpconv层的计算如下,
这里 代表的是特征图里的像素坐标, 代表围绕坐标 的输入patch(也就是输入特征图中当前跟卷积核进行卷积的patch), 代表第n层的kernel,它本质上是第n层kernel的下标(即表示当前是第n层的第几个kernel在进行卷积),值得注意的是,这里的 和 都是三维的,因为是多通道的卷积。
n代表MLP中的层数,MLP的激活函数采用ReLU。
很容易看出,上述公式中,第一个公式与传统卷积相同,即卷积核与特征图patch卷积经过ReLU进行输出,那 本质上是一个[1, 1]的数值,所有的 卷积结果合并起来就是 ,也就是一个[1, 1, output_channel]的向量,这个时候将这个向量输出到下一层,而下一层开始就是MLP。
从跨通道(跨特征图)池化的角度来看,上述公式等价于传统卷积层的级联跨通道带参数池化(cascaded cross channel parametric pooling, cccp层)。每个pooling层其实就是对输入特征图进行加权线性重组,然后再经过一个ReLU。这些跨通道的池化特征图会在接下来的层中反复的进行跨通道池化,这就是级联的由来。这个级联跨通道带参数池化结构允许跨通道信息进行复杂且可学习的交互。
这个跨通道带参池化层其实本质上等价于1x1的卷积层。
综上,其实mlpconv本质上就是,传统卷积层+多个1x1卷积层的一个结构。
与maxout层相比:
在maxout网络中的maxout层是跨通道对多个仿射特征图进行max pooling。公式如下:
对线性函数的进行maxout会得到一个分段线性函数,这可以拟合任意的凸函数。对于一个凸函数来说,方程函数值的采样都会低于一个特定的阈值,最终这些采样值会形成一个凸集。因此,通过局部patch的凸函数逼近,maxout能够去拟合一个分割超平面来分割那些样本值位于凸集内的潜在概念。Mlpconv层有别于maxout层,是用一个通用函数逼近来代替一个凸函数逼近,这将能够更好的去拟合潜在概念的不同分布。
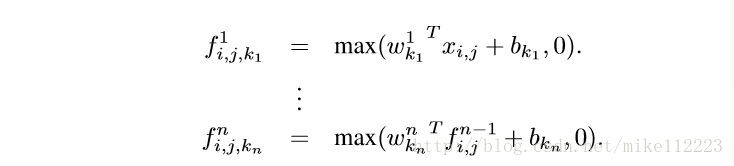
Global Average Pooling
传统卷积神经网络会在网络的低层中进行卷积操作。对于分类问题,最后一层卷积层的输出特征图会被向量化,然后输出到一个FC layer连接softmax逻辑回归层的结构中。这个结构很好的桥接了卷积结构和传统的神经网络分类器。它将卷积层作为特征提取,然后将最终得到的特征用传统的方式进行分类。
然后,FC layers有一个很大的缺点就是容易过拟合,会影响整个网络的泛化能力。Dropout是一个很好的针对FC的正则化手段。
在这篇论文中,我们提出采用全局平均池化(global average pooling)来代替传统的FC layers。这个想法是在最后的mlpconv层中针对分类任务中的每一个分类相应的生成一个特征图。不是运用一个FC layers,而是对每个特征图进行平均池化,然后将得到的结果向量直接输出到softmax中。这种做法有两个好处:
- 对于网络前面的卷积结构,这种加强特征图与对应分类的关联的做法更加自然。特征图也会更容易被训练作为对应分类的分类依据。
- 全局平均池化没有参数需要训练,过拟合也就无从谈起,并且全局平均池化综合了所有空间信息,因此对于输入的空间平移更加鲁棒。
Network In Network Structure
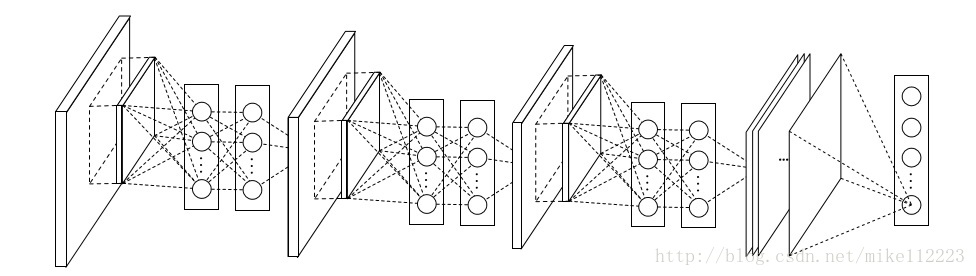
NIN的整个网络结构其实就是mlpconv层的堆叠,最后再接一个全局平均池化层和softmax。降采样层可以加入到mlpconv层之间,就像CNN和maxout网络一样。下图是一个三层mlpconv层的NIN结构。可根据具体任务进行网络修改。
总结
NIN,引入了一种全新的网络结构,mlpconv层,通过加强对局部patch的更好的特征提取与抽象表达,来加强整个网络的特征表达能力,克服了线性卷积作为GLM无法很好地拟合表达高度非线性特征的缺点,还克服了线性卷积需要超完备卷积核才能保证覆盖所有潜在概念的缺点,大大减小参数数量。引入cccp层,也就是1x1卷积核,加强通道间的信息交互与学习。引入全局平均池化代替FC layers,加强了特征图与对应分类的关联,也同时摒弃了FC layers带来的大量参数以及其容易过拟合的性质。
小广告
淘宝choker、耳饰小店 物理禁止
女程序员编码时和编码之余 都需要一些美美的choker、耳饰来装扮自己
男程序员更是需要常备一些来送给自己心仪的人
淘宝小店开店不易 希望有缘人多多支持 (O ^ ~ ^ O)
本号是本人 只是发则小广告 没有被盗 会持续更新深度学习相关博文和一些翻译
感谢大家 不要拉黑我 ⊙﹏⊙|||°