Inception v4, Inception-ResNet:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
摘要:最近几年,深度卷积神经网络对图像识别性能的巨大提升发挥着关键作用。以Inception网络为例,其以相对较低的计算代价取得出色的表现。最近,与传统结构相结合的残差连接网络在2015ILSVRC挑战赛上取得了state of art的成绩;它的性能跟最新的Inception-v3 网络非常接近。这引出一个问题:Inception架构和residual连接的结合能否带来性能的提高。在本文,我们发现残差连接显著地加速了Inception网络的训练。residual Inception网络和Inception网络的计算量相当,但性能有微弱优势。针对残差和非残差Inception网络,本文也提出了一些新的简化版本。这些变种显著提高了ILSVRC 2012分类任务的单帧识别(single-frame recognition)性能。我们进一步说明了:适当的激活缩放如何使得很宽的Residual Inception网络的训练更加稳定。
本文通过三个residual和一个Inception网络的集成,在ImageNet分类比赛中取得了top-5: 3.08%的错误率。
总结:本文在Inception v3的基础上,设计了v4,并且研究了Inception和Residual connection的结合。
Inception-v4在v3的基础上,对Inception架构进行了彻底的探索。
Inception-ResNet将Inception和ResNet结合进一步肯定了残差连接的效果
1. 简介
自从AlexNet赢得了ImageNet 2012比赛后,AlexNet已经成功应用到了很多计算机视觉任务上,例如:目标检测[4],分割[10],人体姿势估计[17],视频分类[7],目标追踪[18],超分辨率[3]等。这些只不过是深度卷积网络成功案例中很少的一部分。
在本文,我们研究了何凯明提出的残差连接[5]和Inception v3[15]的结合。在ResNet中,认为残差连接对非常深的架构的训练非常重要。因为Inception网络趋向于非常深,考虑用残差连接替代滤波器的连结便是很自然的事。这将在保持计算量基本不变的情况下,允许Inception充分利用残差连接的优点。
除了直接的融合,我们也研究了Inception本身通过变得更深更宽能否能变得更加高效。为了实现这个目的,我们设计了一个新版本的Inception-v4,相比Inception-v3,它有更加统一简化的网络结构和更多的inception模块。回首过去,Inception-v3继承了之前的很多方法。技术性局限主要在于使用DistBelief对分布式训练进行模型分割。
在本文中,我们将会比较Inception v3、v4和Inception-ResNet。这里的Inception-ResNet和Inception的参数量、计算量基本一样。但作者其实也进行了更深,更宽的Inception-ResNet实验(在ImageNet上,性能基本相似)。
本文的最后一个实验对当前最高性能模型进行了集成(集成了4个模型,3个ResNet和1个Inception-v4)。可以清晰的看到,Inception-v4和Inception-ResNet-v2性能相近,都超过了当前的state of art,我们想要去探究怎样的集成更能提高准确率(on ImageNet)。意外的是,我们发现single-frame performance的提高不能转变为集成版本类似大的性能提升。尽管如此,它仍然在验证集上取得了top-5: 3.1%的准确率(刷新了记录)。
在最后一节,我们研究了一些错误的分类并且得出结论,集成仍然没有达到标记的label噪声对应的准确率,所以,准确率仍有提高的空间。
2. 相关工作
自从AlexNet之后,卷积网络在大型图像识别任务中越来越流行。接下来的一些重要的里程碑有:NIN、VGGNet、GoogLeNet。
残差连接是由He等人提出的。在ResNet中,它以令人信服的理论和实践证据,证明了信号的加性合并的优点,在图像识别中,尤其是物体检测任务中。何凯明认为对于非常深的卷积模型的训练,残差连接是必须的。我们的发现看起来不支持这个观点(至少对于图像识别是这样)。However it might require more measurement points with deeper architectures to understand the true extent of beneficial aspects offered by residual connections。在试验部分,我们说明了没有残差连接的深度网络的训练并不难做到。但是,残差连接极大地提高了训练速度,单单这一点就值得肯定。
Inception深度卷积架构在GoogLeNet中提出,后来,Inception v2中引入了BN,v3引入了大尺寸filter的分解。
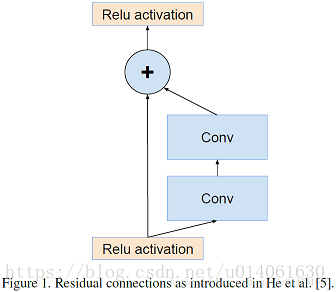
ResNet中提出的残差连接模块
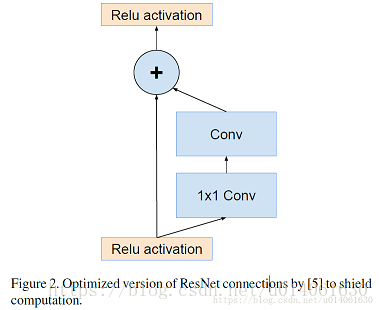
优化版ResNet模块,加入了1x1卷积。
3. 架构的选择
3.1 纯Inception模块
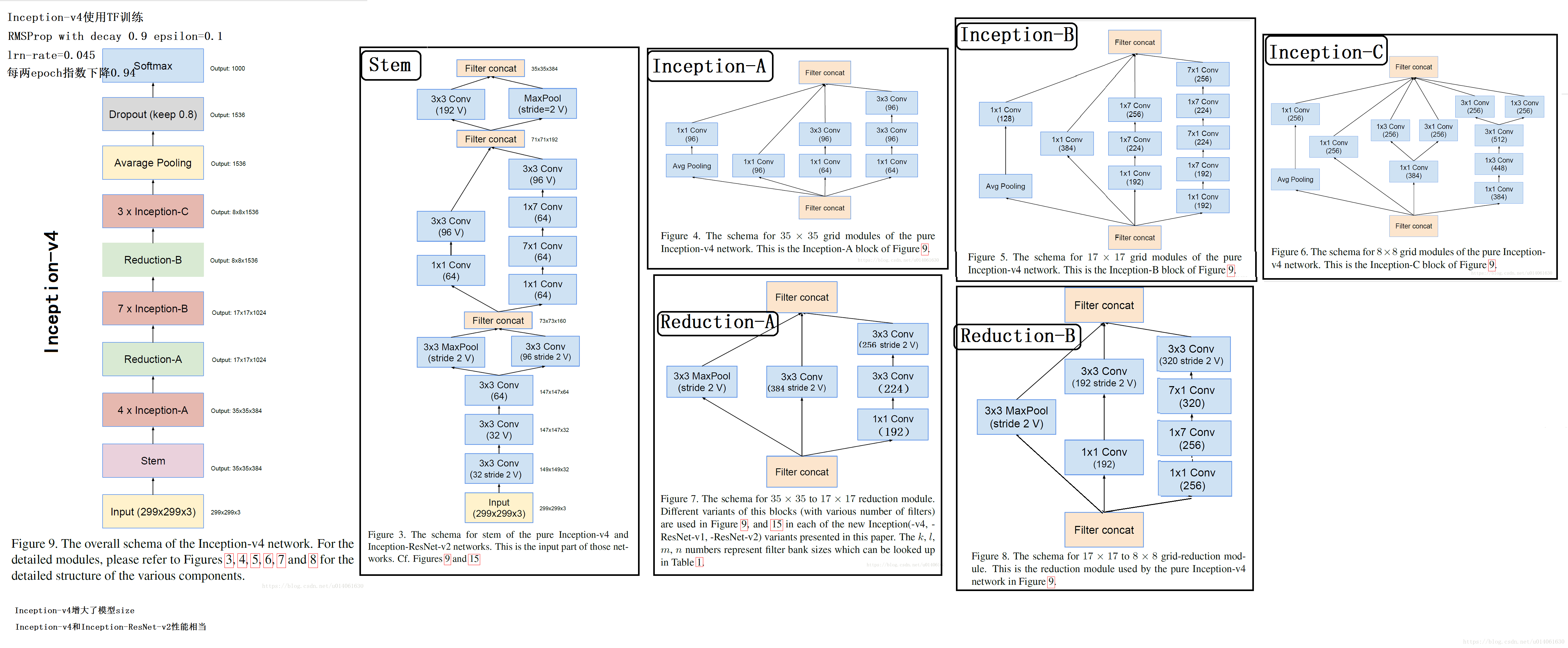
以前的Inception模型通过分布式进行训练,将每个副本被划分成一个含多个子网络的模型,以满足内存需求。然而,Inception结构是高度可调的,这就意味着各层滤波器(filter)的数量可以有多种变化,而整个训练网络的质量不会受到影响。为了优化训练速度,我们对层大小进行调整以平衡不同子网络的计算。相反,随着TensorFlow的引入,大部分最新的模型无需分布式的对副本进行训练。它通过反向传播(back propagation)进行内存优化,并仔细考虑梯度计算需要的tensors,以及通过结构化计算减少这类tensors的数量。过去,我们对网络结构的更迭做得非常保守,并限制实验改变独立网络的组分,同时保持其余网络的稳定性。由于之前没有对网络进行简化,导致网络看起来更加复杂。在最新的Inception-v4实验中,我们决定去掉不必要的模块,同时统一各个grid size一样的Inception模块的参数。如图9,展示了大尺寸的Inceptionv4网络结构。图3至8是每个部分的详细结构。所有图中没有标记“V”的卷积使用same的填充原则,意即其输出网格与输入的尺寸正好匹配。使用“V”标记的卷积使用valid的填充原则,意即每个单元输入块全部包含在前几层中,同时输出激活图(output activation map)的网格尺寸也相应会减少。
在过去的Inception架构(v1、v2、v3)中,作者对于结构的改变是相对保守的,并且作者为了保持网络其余部分的稳定 ,各部分的改变都很有限。复杂的前层的选择导致网络复杂度过高。在本文的实验中(Inception v4),作者将打破前面的限制,均匀改变各个grid size模组。图9是Inception v4的结构图,图3、4、5、6、7、8是每一个部件的细节图。没V的卷积采用same填充,标记V的卷积采用valid填充。
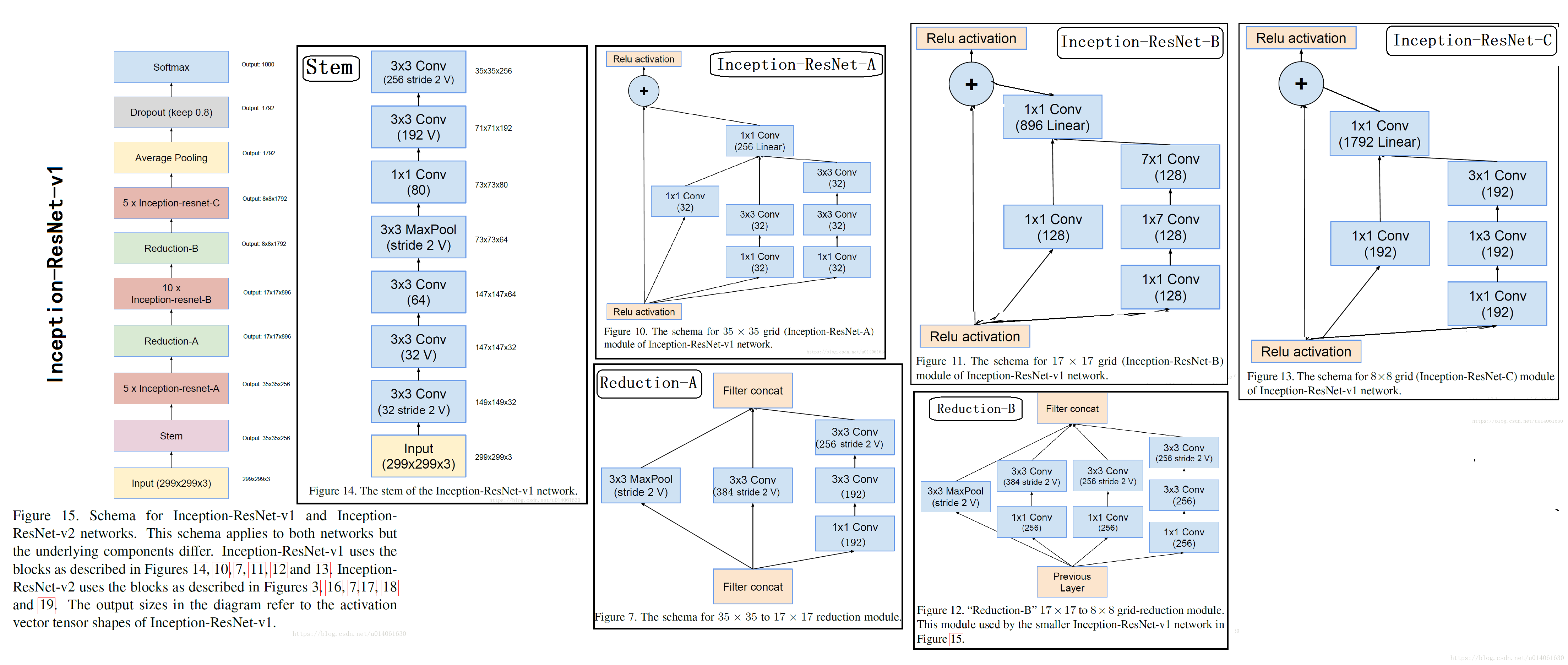
3.2 残差Inception模块(Residual Inception blocks)
在Residual-Inception网络中,我们使用比原始Inception模块计算量更低的Inception模块。每个Inception块后紧连接着滤波层(没有激活函数的1×1卷积)以进行维度变换,以实现输入的匹配。这样补偿了在Inception块中的维度降低。
我们尝试了很多Inception-Residual版本。这里对其中的两个进行具体细节说明。第一个是“Inception-ResNet-v1”,计算量跟Inception-v3大致相同,第二个“Inception-ResNet-v2”的计算量跟Inception-v4网络基本相同。图15是Residual-Inception的架构图。(但是,实验中Inception-v4单个step的时间更慢,这可能是因为有了更多的层)。
残差和非残差Inception的另外一个小技术性区别是,在Inception-ResNet网络中,我们只在传统层上使用BN。在全部层使用 batch-normalization是合情合理的,但是我们想保持每个模型副本在单个GPU上就可以训练。结果证明,使用更大的activation尺寸消耗更多的GPU内存。省略这些activation后的BN层,我们能够增加更多的Inception模块。我们希望可以更好的利用计算量,因而这种trade-off变得没有必要。

3.3 残差模块的缩放(Scaling of the Residuals)
我们也发现,如果filter的数量超过1000,残差网络开始出现不稳定,同时网络会在训练过程早期便会出现“死亡”,即经过几万次训练后,平均池化层(average pooling) 之前的层开始只生成0。降低学习率、增加额外的BN层都无法避免这种状况。
我们发现,在将残差加到前层的activation之前,对本层的activation进行放缩能够稳定训练。通常,我们将残差放缩因子定在0.1到0.3之间去缩放residuals。(如图20)
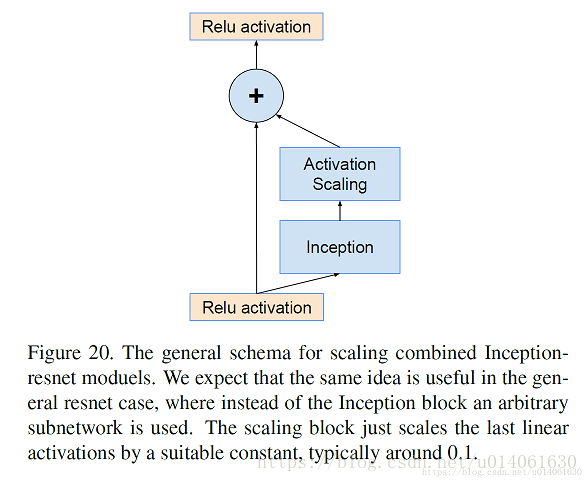
类似的不稳定在ResNet文中也出现过, 文中建议通过两个阶段的训练来避免这种情况,其中第一个“warm-up”阶段使用极低的学习率,紧接着第二阶段使用高学习率。我们发现如果滤波器数量非常大,那么即使很低的学习率(0.00001)也不足以解决不稳定性,而且使用高学习率训练对其效果也有损伤。最终我们发现只需对残差进行缩放的方法更加可靠。
即使缩放并不是完全必须的,它似乎并不会影响最终的准确率,但是放缩能有益于训练的稳定性。
4. 训练策略(Training Methodology)
训练使用TensorFlow的随机梯度算法(20块GPU)
早期实验采用momentum with a decay 0.9
最好的模型是用RMSProp with a decay 0.9 and
=1.0
学习速率:0.045 decayed every two epochs using an exponential rate of 0.94
模型评估 are performed using a running average of the parameters computed over time.
5. 实验的结果(Experimental Results)
首先作者观察了四个模型的top-1和top-5验证错误在训练中的变化过程。在实验后,我们发现:我们的连续评估是在验证集的一个子集上进行的,这个子集忽略了大约1700个黑名单实体,由于缺少边界。这证明了忽略只应该在CLSLOC benchmark上实施,但是与其他报告相比(包括我们团队早前的一些报告),产生了一些不可比的(更加乐观的)数字。差异大约是0.3% for top-1,0.15% for top-5。但是因为差异是一致的,所以我们认为曲线的对比是公平的。
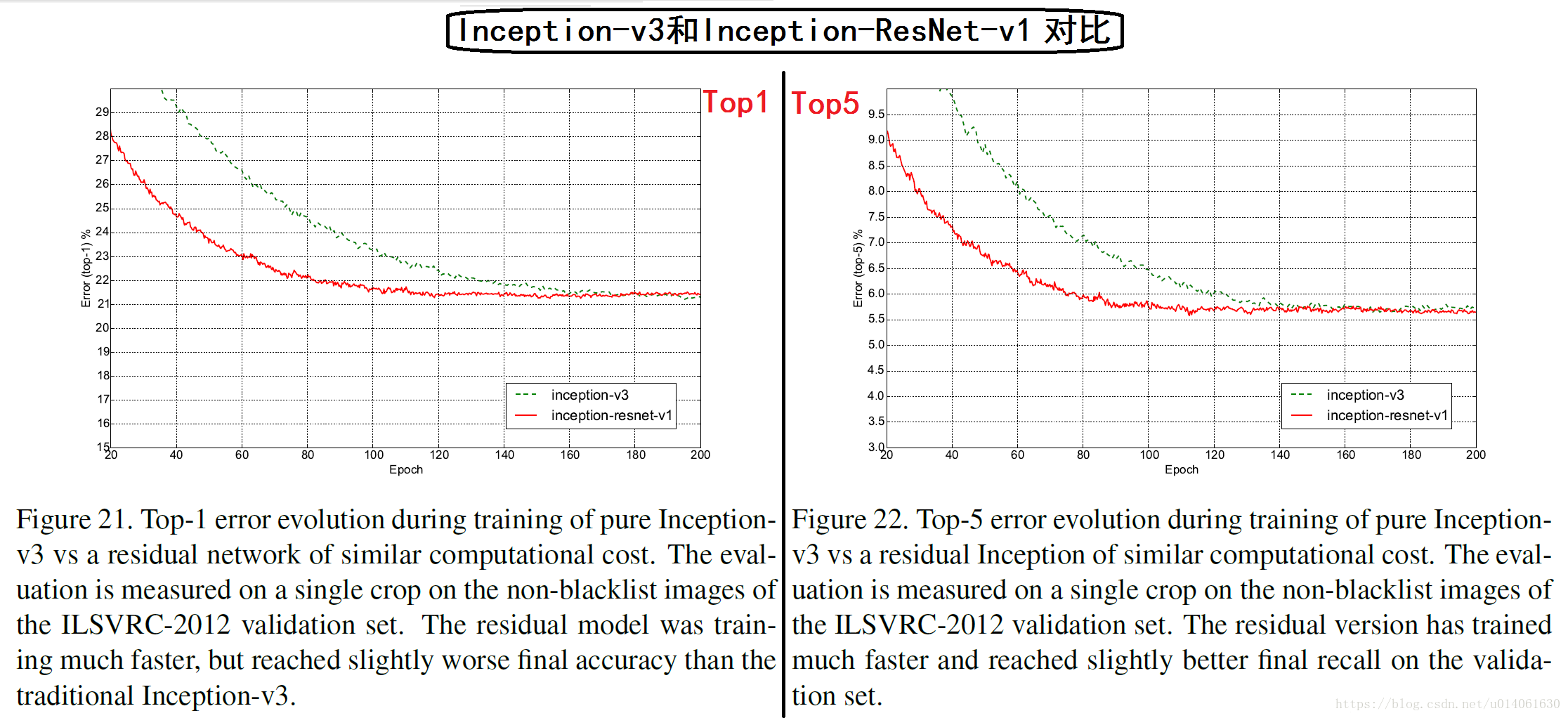
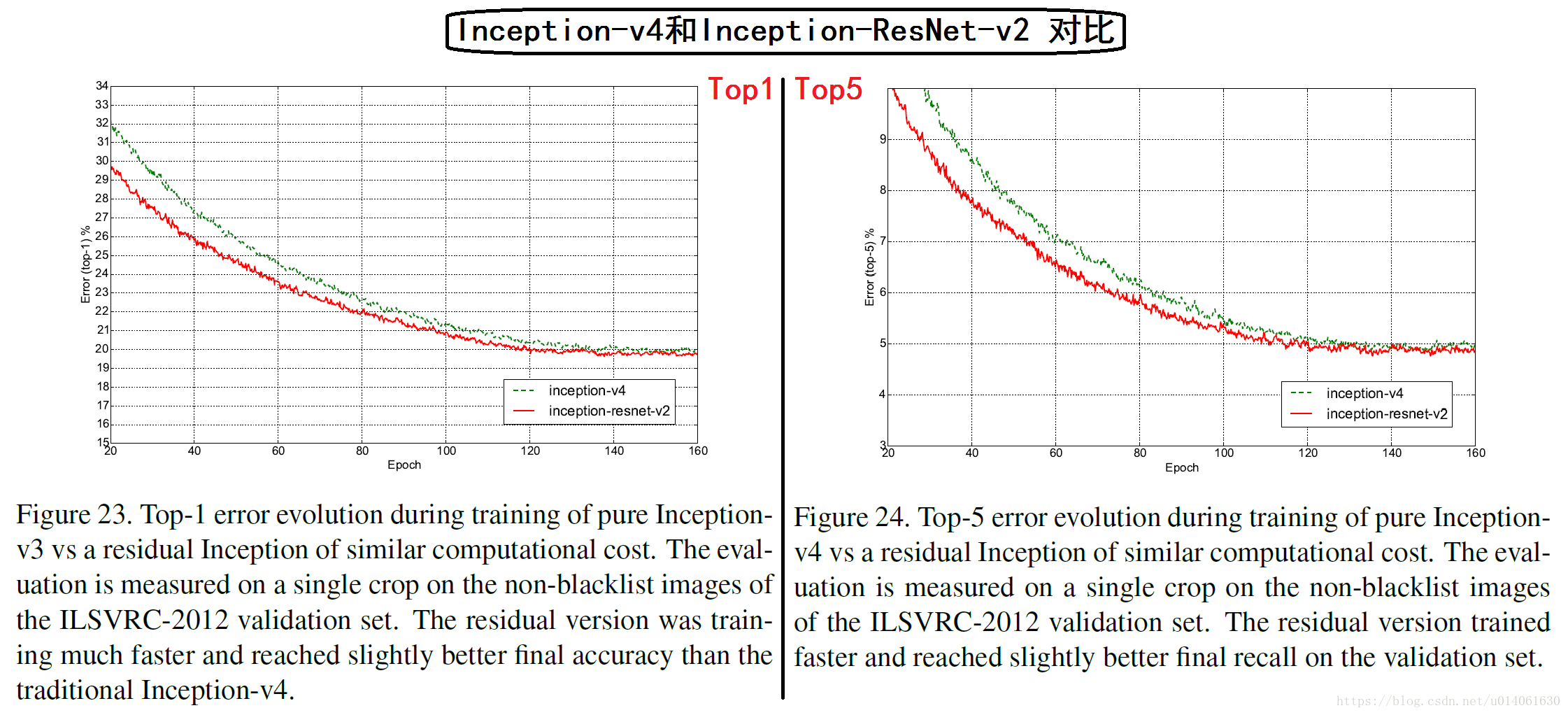
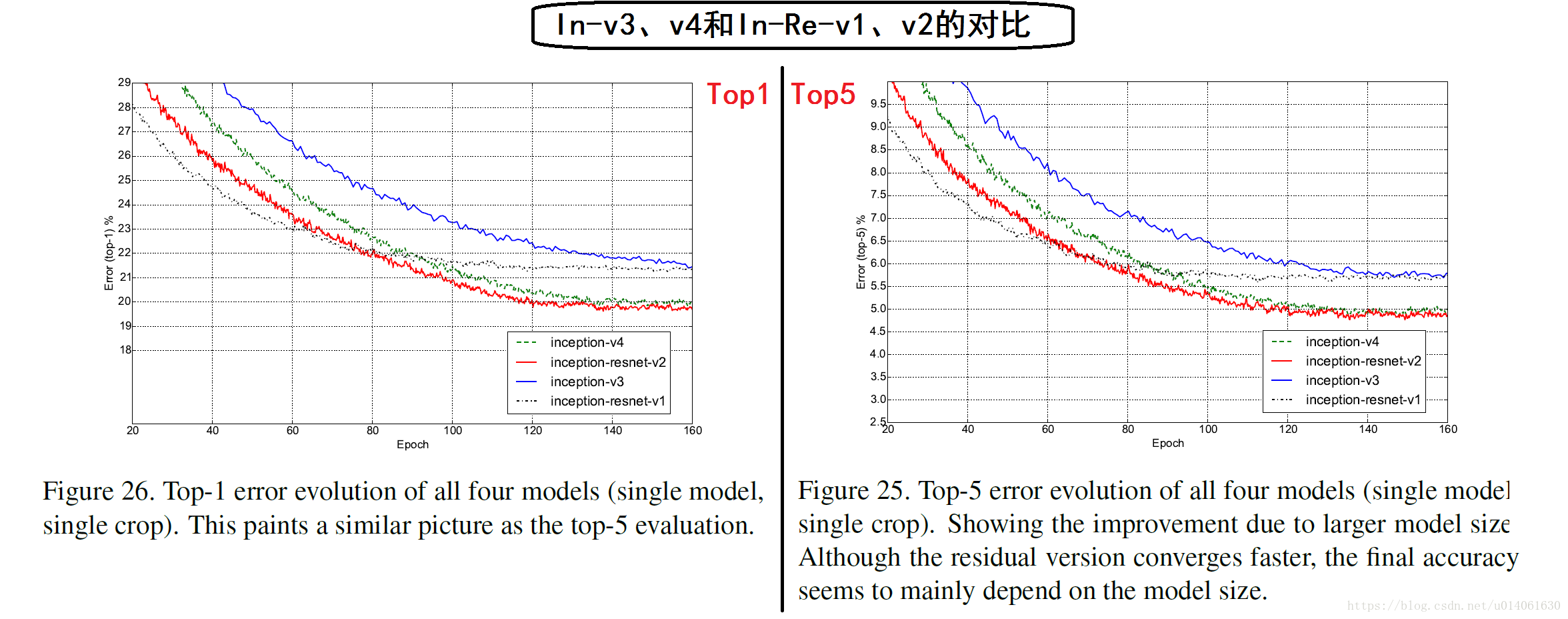
另一方面,我们在50000张验证图像上进行多次裁剪和集成验证。同样最后的集成模型在测试集进行测试并在ILSVRC测试服务器上验证我们的网络调整并没有导致过拟合。我们想强调的是,最终进行了一次验证,并在去年进行了两次结果提交:一次是BN-Inception论文和后来的ILSVR-2015 CLSLOC竞赛,因此我们相信测试集很好的验证了本文模型的泛化能力。
最后,我们展示了不同版本Inception和Inception-ResNet的比较结果。Inception-v3和Inception-v4模型是深度卷积网络,他们没有使用残差连接,而Inception-ResNet-v1和Inception-ResNet-v2使用了残差连接而没有使用filter-expansion连接。
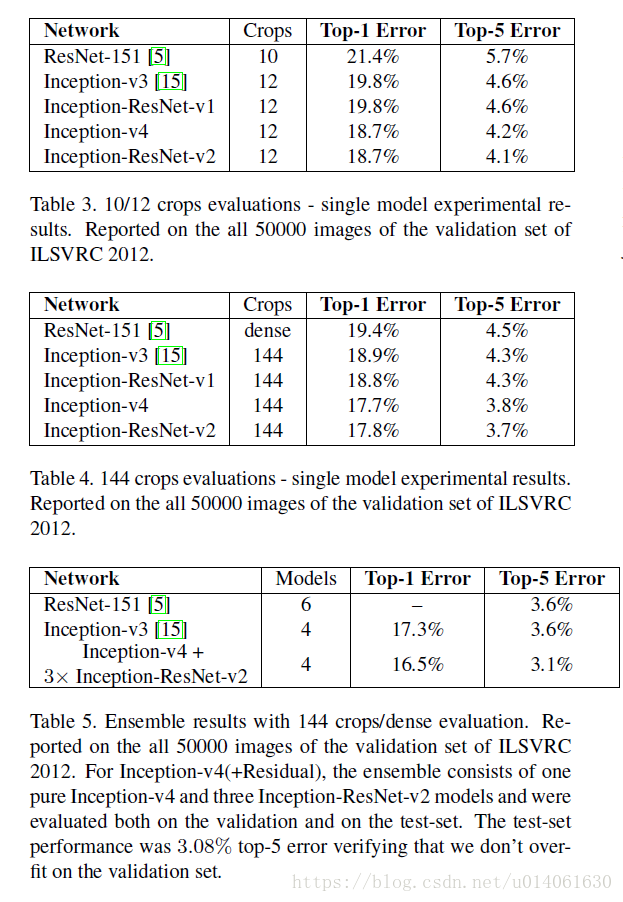
表2展示了在验证集上各种结构的单个模型以及单次裁剪的top-1和top-5错误率。
表3展示了使用小数量裁剪的各种模型的性能比较:引文5中对ResNet做了10个裁剪,对于Inception,我们如引文14描述那样,使用12种裁剪进行验证。
表4展示了单个模型的性能。对于残差网络dense的验证结果可参见引文14。对于Inception网络,[14]描述了针对inception网络的144种裁剪策略
Table5比较了组合的结果。[5]描述了对于纯净的残差网络,6个模型的dense验证的结果。对于Inception网络4个模型的组合,144种裁剪策略正如[14]描述即可。
6.结论
本文详细呈现了三种新的网络结构:
- Inception-Reset-v1:混合Inception版本,它的计算效率同Inception-v3;
- Inception-ResNet-v2:更加昂贵的混合Inception版本,同明显改善了识别性能;
- Inception-v4:没有残差链接的纯净Inception变种,性能如同Inception-ResNet-v2
我们研究了引入残差连接如何显著的提高inception网络的训练速度。而且仅仅凭借增加的模型尺寸,我们的最新的模型(带和不带残差连接)都优于我们以前的网络。
下面给出Inception-v4的TensorFlow实现:
#python3
#modules.py for Inception-v4
import numpy as np
import tensorflow as tf
def stem(inputs,
scope='Stem'):
'''
Stem for Inception-v4 and Inception-ResNet-v2
Figure 3
'''
with tf.variable_scope(scope):
x = inputs
#conv1
with tf.variable_scope('conv1'):
x = tf.layers.conv2d(x, 32, [3,3], 2, padding='valid')
#conv2
with tf.variable_scope('conv2'):
x = tf.layers.conv2d(x, 32, [3,3], 1, padding='valid')
#conv3
with tf.variable_scope('conv3'):
x = tf.layers.conv2d(x, 64, [3,3], 1, padding='same')
#sub1
with tf.variable_scope('sub1'):
sub1 = tf.layers.max_pooling2d(x, [3,3], 2, padding='valid')
sub2 = tf.layers.conv2d(x, 96, [3,3], 2, padding='valid')
x = tf.concat([sub1,sub2], axis=-1)
#sub2
with tf.variable_scope('sub2'):
sub1 = tf.layers.conv2d(x, 64, [1,1], 1, padding='same')
sub1 = tf.layers.conv2d(sub1, 96, [3,3], 1, padding='valid')
sub2 = tf.layers.conv2d(x, 64, [1,1], 1, padding='same')
sub2 = tf.layers.conv2d(sub2, 64, [7,1], 1, padding='same')
sub2 = tf.layers.conv2d(sub2, 64, [1,7], 1, padding='same')
sub2 = tf.layers.conv2d(sub2, 96, [3,3], 1, padding='valid')
x = tf.concat([sub1,sub2], axis=-1)
#sub3
with tf.variable_scope('sub3'):
sub1 = tf.layers.conv2d(x, 192, [3,3], 2, padding='valid')
sub2 = tf.layers.max_pooling2d(x, [3,3], 2, padding='valid')
x = tf.concat([sub1,sub2], axis=-1)
return x
def inception_a(inputs,
scope='Inception-A'):
'''
Inception-A for Inception-v4
Figure 4
'''
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.average_pooling2d(x, [3,3], 1, padding='same')
sub1 = tf.layers.conv2d(sub1, 96, [1,1], 1, padding='same')
sub2 = tf.layers.conv2d(x, 96, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(x, 64, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 96, [3,3], 1, padding='same')
sub4 = tf.layers.conv2d(x, 64, [1,1], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 96, [3,3], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 96, [3,3], 1, padding='same')
x = tf.concat([sub1,sub2,sub3,sub4], axis=-1)
return x
def inception_b(inputs,
scope='Inception-B'):
'''
Inception-B for Inception-v4
Figure 5
'''
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.average_pooling2d(x, [3,3], 1, padding='same')
sub1 = tf.layers.conv2d(sub1, 128, [1,1], 1, padding='same')
sub2 = tf.layers.conv2d(x, 384, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(x, 192, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 224, [1,7], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 256, [7,1], 1, padding='same')
sub4 = tf.layers.conv2d(x, 192, [1,1], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 192, [1,7], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 224, [7,1], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 224, [1,7], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 256, [7,1], 1, padding='same')
x = tf.concat([sub1,sub2,sub3,sub4], axis=-1)
return x
def inception_c(inputs,
scope='Inception-C'):
'''
Inception-C for Inception-v4
Figure 6
'''
sub = []
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.average_pooling2d(x, [3,3], 1, padding='same')
sub1 = tf.layers.conv2d(sub1, 256, [1,1], 1, padding='same')
sub.append(sub1)
sub2 = tf.layers.conv2d(x, 256, [1,1], 1, padding='same')
sub.append(sub2)
sub3 = tf.layers.conv2d(x, 384, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 256, [1,3], 1, padding='same')
sub.append(sub3)
sub3 = tf.layers.conv2d(sub3, 256, [3,1], 1, padding='same')
sub.append(sub3)
sub4 = tf.layers.conv2d(x, 384, [1,1], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 448, [1,3], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 512, [3,1], 1, padding='same')
sub4 = tf.layers.conv2d(sub4, 256, [3,1], 1, padding='same')
sub.append(sub4)
sub4 = tf.layers.conv2d(sub4, 256, [1,3], 1, padding='same')
sub.append(sub4)
x = tf.concat(sub, axis=-1)
return x
def reduction_a(inputs,
params,
scope='Reduction-A'):
'''
Reduction-A
Figure 7
'''
[k,l,m,n] = params
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.max_pooling2d(x, [3,3], 2, padding='valid')
sub2 = tf.layers.conv2d(x, n, [3,3], 2, padding='valid')
sub3 = tf.layers.conv2d(x, k, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, l, [3,3], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, m, [3,3], 2, padding='valid')
x = tf.concat([sub1,sub2,sub3], axis=-1)
return x
def reduction_b(inputs,
scope='Reduction-B'):
'''
Reduction-B for Inception-v4
Figure 7
'''
with tf.variable_scope(scope):
x = inputs
sub1 = tf.layers.max_pooling2d(x, [3,3], 2, padding='valid')
sub2 = tf.layers.conv2d(x, 192, [1,1], 1, padding='same')
sub2 = tf.layers.conv2d(sub2, 192, [3,3], 2, padding='valid')
sub3 = tf.layers.conv2d(x, 256, [1,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 256, [1,7], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 320, [7,1], 1, padding='same')
sub3 = tf.layers.conv2d(sub3, 320, [3,3], 2, padding='valid')
x = tf.concat([sub1,sub2,sub3], axis=-1)
return x#python3
#Inference for Inception-v4
import numpy as np
import tensorflow as tf
import modules as modules
def print_activation(x):
print(x.op.name, x.get_shape().as_list())
def inferene(inputs,
scope='inference'):
with tf.variable_scope(scope):
x = inputs
#Stem
with tf.variable_scope('Stem'):
x = modules.stem(x, scope='Stem')
#Inception-A-x
with tf.variable_scope('Inception-A-x'):
for i in range(4):
x = modules.inception_a(x, scope='Inception-A-'+str(i))
#Reduction-A
with tf.variable_scope('Reduction-A'):
x = modules.reduction_a(x, [192,224,256,384], scope='Reduction-A')
#Inception-B-x
with tf.variable_scope('Inception-B-x'):
for i in range(7):
x = modules.inception_b(x, scope='Inception-B-'+str(i))
#Reduction-B
with tf.variable_scope('Reduction-B'):
x = modules.reduction_b(x, scope='Reduction-B')
#Inception-C-x
with tf.variable_scope('Inception-C-x'):
for i in range(3):
x = modules.inception_c(x, scope='Inception-C-'+str(i))
#Average Pooling
with tf.variable_scope('Average_Pooling'):
x = tf.layers.average_pooling2d(x, [8,8], 1, padding='same')
#Dropout
with tf.variable_scope('Dropout'):
x = tf.layers.dropout(x, rate=0.2)
#Softmax
with tf.variable_scope('Softmax'):
logits = tf.layers.conv2d(x,1000,[1,1],1,padding='same')
return logits
inputs = tf.placeholder(tf.float32, [None,299,299,3])
y = inferene(inputs)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
tf.summary.FileWriter('log/', sess.graph)