ResNet v2:Identity Mappings in Deep Residual Networks
摘要:
ResNets v1作为一种极深的网络框架,在精度和收敛等方面都展现出了很好的特性。在本文,我们分析了残差块(residual building blocks)背后的信号传播公式(数学表达式),公式表明,当使用恒等映射(identity mappings)作为跳跃连接(skip connections)及信号加合后的激活函数时,前向、反向传播的信号能直接从一个残差块传递到其他任意一个残差块。一系列的“ablation”实验也验证了这些恒等映射的重要性。这促使我们提出了一个新的残差单元,它使得训练变得更容易(更容易收敛),同时也提高了网络的泛化能力。我们报告了1001层的ResNet在CIFAR-10(4.62% error) 和CIFAR-100上的结果,以及200层的ResNet在ImageNet上的结果。代码可在 https://github.com/KaimingHe/resnet-1k-layers上下载。
1.简介
ResNets v1堆叠了很多残差单元,每一个单元(图1a)能够写为下面的通用形式:
这里 和 是第 个单元的输入和输出, 是一个残差函数。在ResNet中, 是一个identity mapping, 是一个ReLU函数。
超过100层的ResNets在ImageNet和MS COCO竞赛的许多识别挑战任务中展现出了极高的精度(state of art)。ResNets的核心思想是去学习加到 上的残差函数 ,这个思想的关键是恒等映射的使用。这种思想可以通过附加一个恒等跳跃连接(shortcut)来实现。
在本文中,我们致力于创建一个全局(整个网络)的直接信息传播路径来分析深度残差网络(而不是仅仅在残差单元内部)。我们的推导揭示了:如果 和 都采用恒等映射,那么在正向传播和反向传播中,信号总能从一个残差块传播到其它的任何一个残差块。我们的实验经验性地说明,当架构接近上面两种情况时,通常训练变得更加容易。
为了理解跳跃连接(skip connections)的作用,我们分析并对比了各种类型的
。我们发现,在所有研究的类型中,ResNet v1中选择的恒等映射
误差下降最快,训练误差最低。而使用缩放(scaling)、门控(gating)以及1×1 卷积的跳跃连接都产生了更高的训练损失和误差。这些实验表明,保持一个干净的(“clean”)信息通道(图1,2,4中灰色箭头)对于简化训练是十分有帮助的。
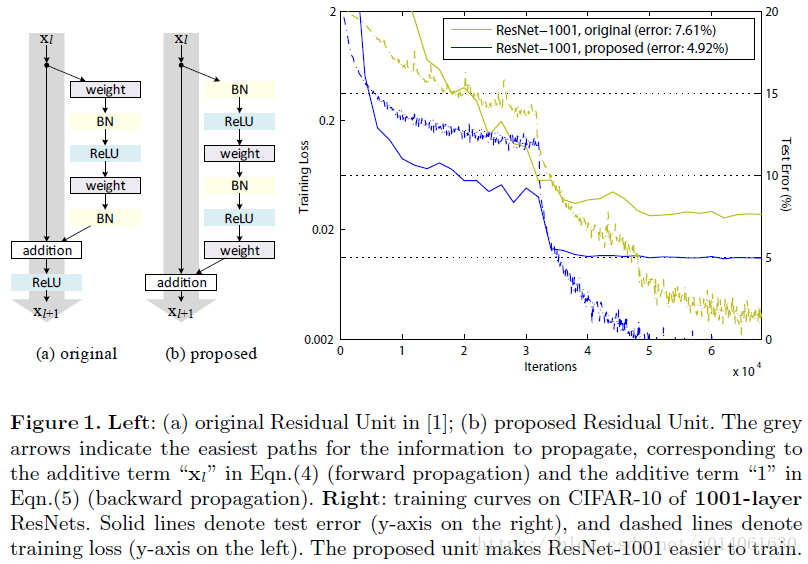
为了建立一个恒等映射
,我们将激活函数(ReLU和BN)看作有权重的层(weight layer)的“pre-activation”。这个观点产生了一个新的残差单元设计(图1b)。基于这个单元设计设计的ResNet-1001在CIFAR-10/100上表现出了更优的结果,并且与原始的ResNet-1001相比,也更容易训练,泛化能力更强。原始的ResNet-200在ImageNet上出现了过拟合现象,我们进一步展示了改进后网络的结果。这些结果表明,深度作为深度学习陈工的关键,仍有很大的研究空间。
2.深度残差网络的分析
ResNet-v1是一个由很多残差块堆叠的模块化架构。本文中,我们称这些块为“残差单元”,ResNet-v1的残差单元进行以下的计算:
如果 是一个恒等映射: ,我们可以把公式2带入公式1,得到:
等式4同样也具有良好的反向传播特性。假设损失函数为 ,根据反向传播的链式法则可以得到(等式5):
讨论
等式4和等式5表明了,在前向和反向传播阶段,信号都能够直接的从一个单元传递到其他任意一个单元。等式4的基础是是两个恒等映射:(i) skip connection
,(ii)
是一个恒等映射。
这些直接传递的信息流如Fig.1、2及4中灰色箭头所示。当这些灰色箭头不附带任何操作(除了必要的加法运算),也就是“clean” 时,以上两个条件是成立的。在接下来两部分中,我们会分别研究这两个条件的作用。
3.恒等跳跃连接的重要性(inportance of identity skip connections)
让我们考虑用 来替代恒等捷径:
在上面的分析中,原始的identity skip connection(公式3)被一个简单的缩放( )代替。如果skip connection 表示更复杂的变换(例如gating或者1x1卷积),公式8的第一项变成了 ,这里 是 的导数。这个乘积也可能阻碍信息的反向传播并且阻碍训练训练过程(实验中也证实了这些)。
3.1 关于skip connection的实验(Experiments on Skip Connections)
我们在CIFAR-10数据集上进行了ResNet_v1-110实验。这个极深的ResNet_v1-110有54个两层残差单元(包含3x3卷积层),并且优化起来也很有挑战。我们的具体实施细节(见附录)和ResNet_v1文中一致。为了避免随机因素的影响,本文中我们的结果为在CIFAR上每个框架运行5次得到的准确率的中位数。
虽然在上述分析中,假设
为恒等映射,这部分的实验中,和ResNet_v1一致,令
=ReLU。我们在下一节将对恒等映射
进行分析。我们的原始ResNet-110在测试集上的错误率为6.61%。其它变种(图2、表1)的对比总结如下:

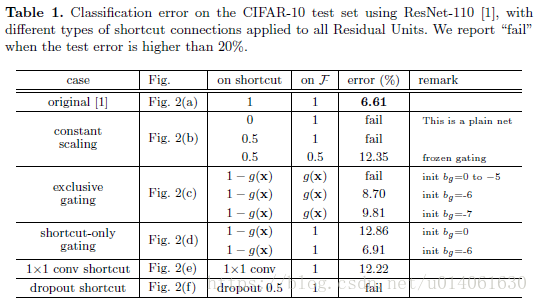
Constant scaling常量缩放
对于所有的捷径连接,我们设置λ=0.5 (Fig.2b)。我们进一步考虑
的两种缩放情况:(i)
不进行缩放。(ii)
用一个常量
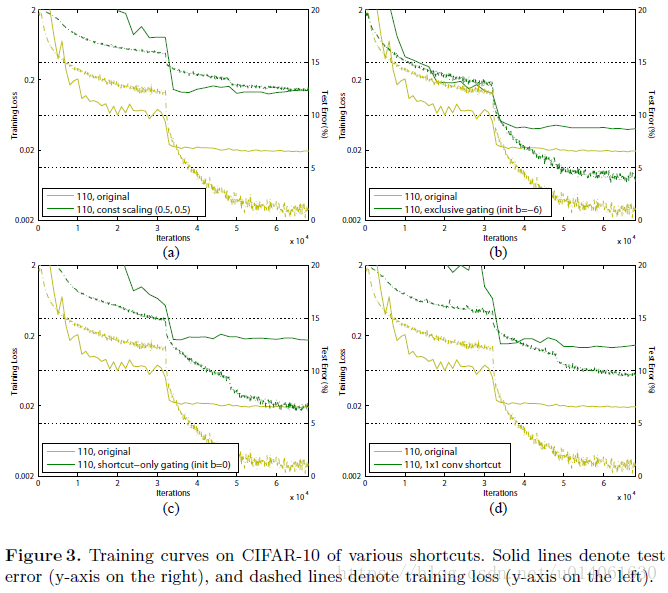
进行缩放,这和highway gating[6,7]有点相似,但是gate是固定的。(i)收敛的不好(测试错误率高于20%),(ii)能够收敛,但是测试错误率(12.35%)比原始的ResNet-110高很多。图3a说明训练误差比原始的ResNet-110高,这表明当shortcut信号scaled down时,优化有困难。
Exclusive gating
和Highway Network [6,7]一样,采用一个gating机制[5],我们考虑一个后面接sigmoid激活函数
的gating函数
。在一个卷积网络中
可以通过1x1卷积层实现。gating函数通过元素元素级别的乘法调节信号。
我们对[6,7]中使用的“exlusive” gates进行了研究,[6,7]中的 path通过 进行缩放,shortcut path通过 进行缩放(图2c)。我们发现偏差 的初始化对于gated模型的训练至关重要,根据[6,7]中的 ,我们设置b_{g}的初始值范围为0到-10,递减量为1,然后通过cross-validation来执行超参数搜索。然后使用最佳值(这里为−6)来在训练集上进行训练,测试错误率为 8.70% (Table1),这仍然落后于原始的ResNet-110。图3b展示了训练曲线。表1也报告了使用其他初始初始值的结果,注意到,当 初始化的不好时,exculsive gating网络不能收敛到一个好结果。
exclusive gating机制的影响是两面的,当 接近1时,gated shortcut连接是十分接近于identity的,这有助于信息的传播;但是在这种情况下, 接近0,并且抑制了函数 。为了单独研究gating函数对于shortcut path的影响,我们接下来研究了没有exclusive gating机制。
Shortcut-only gating
在这种情况下,函数
不进行缩放;shortcut path只用
进行缩放(图2d)。
的初始值对于这种情况仍然很重要。当
的初始值是0时(所以1-g(x)的初始化的期望值为0.5),网络收敛到一个很烂的结果(12.86%表1)。这也是由于训练误差很高(图3c)。
当 的初始值是一个非常小的负数(very negatively biased 例如 -6), 的值非常接近1并且shortcut连接接近于identity映射。因此结果(6.69%表1)是很接近ResNet_v1-110。
1x1 Convolutional shortcut
接下来我们使用 1××1 的卷积捷径连接替代恒等连接在进行实验。这种方案在ResNet_v1中使用在34层的ResNet(16个残差单元)上(即方案C),并展现出了很好的结果,表明了1××1 卷积shortcut是有效果的。但是我们发现当残差单元有很多时,这并不能起到特别好的效果。当使用1×1 的卷积捷径连接时,110 层的ResNet的结果很差(12.22%, Table1),训练误差变得很高(图3d)。当堆叠了如此多的残差单元时(110层有54个残差单元),即使shortcut path可能仍然阻碍信号的传播。我们发现相同模型(ResNet-110 with 1x1 conv shortcut)在ImageNet数据集上也出现了相同现象。
Dropout shortcut
最后我们在恒等捷径连接上添加Dropout(比率为0.5) 来进行实验(图2f)。网络并没有收敛到一个很好的结果。Dropout在统计学上相当于给捷径连接强加了一个
为0.5的缩放,这和0.5的constant scaling很类似,同样的阻碍了信号的传播。
3.2 讨论
如图2中灰色箭头所示,shortcut连接是信息传递最直接的路径。shortcut连接中的操作 (scale、gating、1××1 conv及 dropout) 会阻碍信息的传递,以致于优化困难。
值得注意的是1×1的卷积shortcut连接引入了更多的参数,本应该具有比恒等捷径连接更强大的表达能力。事实上,shortcut-only gating 和1×1的卷积涵盖了恒等捷径连接的解空间(即,他们能够以恒等捷径连接的形式进行优化)。然而,它们的训练误差比恒等捷径连接的训练误差要高得多,这表明了这些模型退化问题的原因是优化问题,而不是表达能力的问题。
4.激活函数的使用(On the Usage of Activation Functions)
上面的实验内容验证了公式5和公式8中的分析,两个公式都假设加和后的激活函数 为恒等连接。但是在上述实验中 是ReLU(和ResNet_v1中一样,采用ReLU),因此,公式5和8只是以上实验的近似。接下来我们研究函数 的影响。
我们希望去重新安排激活函数(ReLU and/or BN)使得
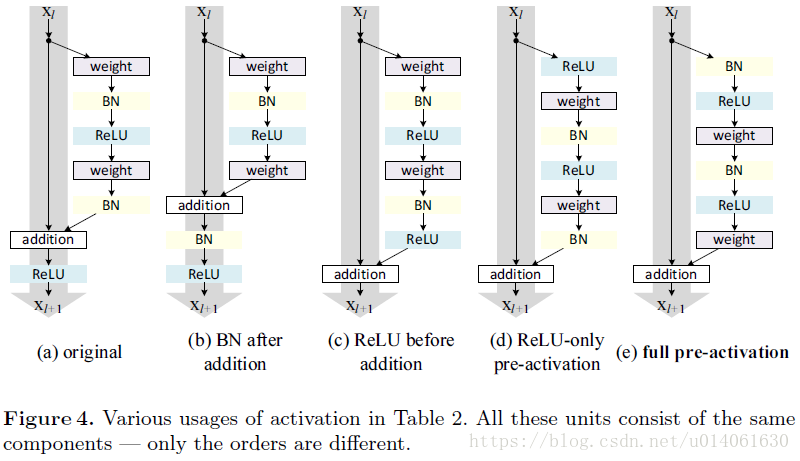
成为一个恒等映射。原始的残差单元(ResNet_v1中的)如图4a,BN被安排在了每一个weight layer后,并且ReLU被放在BN后(除了残差单元内部的最后一个ReLU(加和之后的ReLU))。图4b-e展示了我们研究的一些变种。
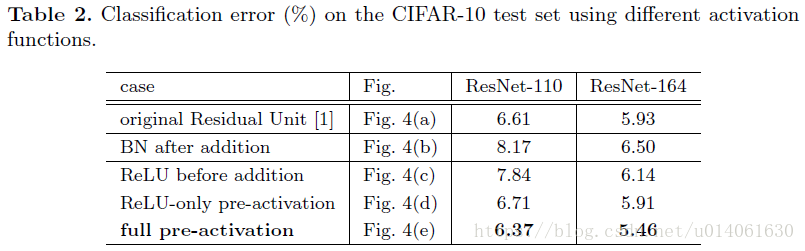
4.1 激活函数的实验(Experiments on Activation)
本章,我们使用ResNet_v1-110和164层瓶颈结构(称为ResNet_v1-164)来进行实验。瓶颈残差单元包含一个1×1的conv层来降维,一个3×3的conv层,还有一个1×1的conv层来恢复维度。正如ResNet_v1中所述,它的计算复杂度和包含两个3×3的层的残差单元相同。更多细节参见附录。ResNet-164的基本结构在CIFAR-10上具有很好的结果——5.93%(Table2)。
BN after addition
在将
调整至恒等映射之前,我们先反其道而行之,在加法后添加一个BN(图4b))。这样
就包含了BN和ReLU。这样的结果比基本结构的结果要差很多(Table2)。不像原始的设计,目前的BN层改变了流经捷径连接的信号,并阻碍了信息的传递,这从训练一开始训练误差降低的困难就可以看出(图6左)。
ReLU before addition
使得
成为identity映射的一个简单的方法是:将ReLU移到加和之前(图4c)。但是,这导致
只能产生非负的结果。但是直觉上,我们认为一个残差函数的输出结果应该在
之间。造成的结果是,前向传播信号是单调递增的。这可能会影响representation能力,并且导致结果比基础模型差(7.84%表2)。我们期望去有一个残差函数产生的值在
之间。这个条件可以通过其他的残差单元(包括下面一个)来满足。
Post-activation or pre-activation?
在原始的设计中(公式1和公式2),activation
会同时影响下一个残差单元的两条路径:
。接下来,我们设计了一个不对称的形式,这里每一个activation
只能影响
路径:
,对于任意的
。通过给符号重命名,我们可以得到下面的公式:
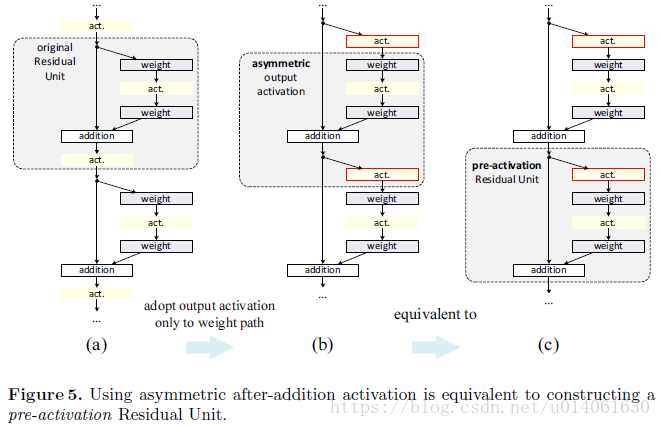

后激活(post-activation)与预激活(pre-activation)的区别是由元素加和引起的(element-wise addition)。对于一个有 个激活(BN and/or ReLU)的 层plain网络,我们认为后激活和预激活的差异不大。但是对于branched layers merged by addition,激活的位置很重要。
我们对下面两种设计进行了实验:(i) ReLU-only preactivation (图4d)),和(ii) full pre-activation (图4e) ,它的BN和ReLU全都放置在权重层的前面。表2表明了,只使用ReLU预激活的结果与原始ResNet-110/164的很接近。这个ReLU层不与BN层连用,因此无法享受BN所带来的好处。
然而,令人惊讶的是,当BN和ReLU都用在预激活上,结果得到了很可观的提高(表2、3)。在表3中,展示了使用不同结构的结果:(i) ResNet-110,(ii) ResNet-164,(iii) 一个110层的ResNet结构,其中每一个捷径连接跳过1层(即,每一个残差单元只包含一层),称它为“ResNet-110(1layer)”,以及(iv) 一个含有333个残差单元的1001层瓶颈结构(对应于每一种尺寸特征图有111个残差单元),称它为“ResNet-1001”。我们同样在CIFAR-100上进行实验。表3表明了我们的“预激活”模型比原始的模型的性能要好得多。分析过程如下。
4.2 分析
我们发现pre-activation的影响是两方面的。首先,优化变得容易了(与基础的ResNet相比),因为 是一个identity映射。第二,使用BN作为pre-activation增强了模型的正则。
Ease of optimization
当训练1001层的ResNet时,效果十分明显。图1展示了训练的曲线。使用ResNet_v1中的原始设计,训练初期训练误差下降的非常慢。对于
,它会阻碍信号负值的部分,并且,当有很多残差单元时,这个效应就会变得十分明显;另外,公式3以及由此推导的公式5不是一个好的近似。另一方面当
是一个恒等映射时,信号能直接在两个单元间传播。我们的1001层的网络训练误差下降的非常快(图1)。同时,它的loss也是我们研究的模型中最低的,说明了优化(训练)的成功。
我们同时也发现:当ResNet的层数不多时, 的影响不是很明显(图6右的164)。在训练初期,训练曲线似乎受到了一点影响,但是马上回归到良好的状态。通过监控模型的响应,我们观测到,这是因为在经过一定的训练后,权重被调整到使得公式1中的 总是大于0的,因此 并不会截断它(由于先前ReLU的存在, 总是非负的,因此只有当 是非常负的时候, 才会小于0)。当时在使用1000层的模型时,这种截断就会更加频繁。
Reducing overfitting
使用pre-activation单元的另一个影响是正则(regularization)(图6右)。pre-ctivation版本产生了稍微高一点的训练误差,但是产生了更低测试误差。这个现象同时在ResNet-110,ResNet-110(1-layer),ResNet-164中可以观察到(数据集CIFAR-10、100)。这可能是由BN的正则作用引起的。在原始的残差单元中(图4a),尽管BN对信号进行了标准化(normalizes),但是它很快就被合并到捷径连接上,组合的信号并不是被标准化的。这个非标准化的信号又被作为下一个权重层的输入。与之相反,在我们的pre-activation版本,所有权重层的输入都进行了标准化。
5 结果
Comparisions on CIFAR-10/100
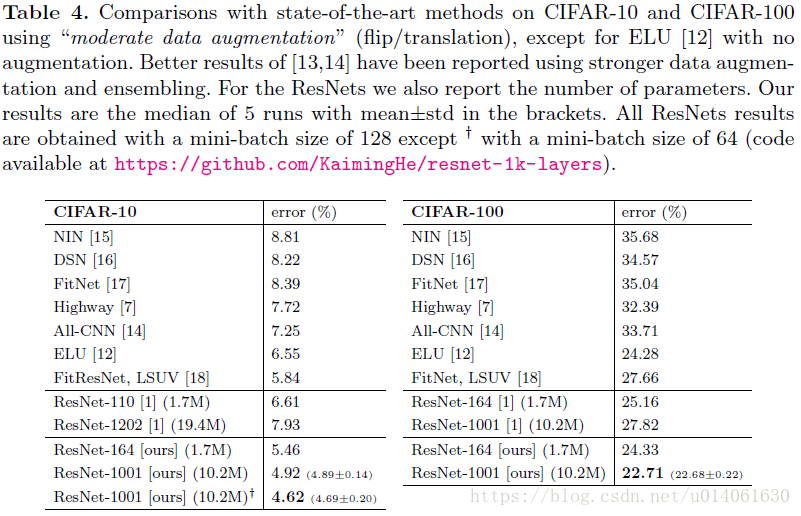
表4在CIFAR-10数据集上比较了当前的state of art方法,这里我们的模型取得了相当有竞争力的结果。可以注意到:对于这些小数据集,我们不需要专门裁剪网络的深度和宽度以及使用正则化技术(例如Dropout)。我们取得这样的结果仅仅是通过一个简单但必要的方法—–加深网络。这些结果说明了网络深度的潜力(potential of
)。
Comaprisions on ImageNet
接下来,我们报告了在1000类的ImageNet数据集上的实验结果。使用图2、3中的skip connections时,ResNet-101在ImageNet上也同样出现了优化困难。没有采用identity shortcut的网络的训练误差明显比原始的ResNet高 at the first learning rate(类似于图3),并且由于资源有限,我们停止了 训练。但是我们完成了一个”BN after addition”(图4b)的ResNet-101的训练(on ImageNet),并且观察到更高的训练loss和验证误差。这个模型的single-crop (224x224)验证误差是24.6%/7.5%,原始的ResNet的验证误差是23.6%/7.1%。这与CIFAR数据集上的结果(图6右)一致。
表5展示了ResNet-152和 ResNet-200(比ResNet-152多16个3-layer瓶颈残差单元,这些单元被添加到28x28的feature map上)的结果,所有训练从头开始。我们注意到原始的ResNet论文中在训练模型时,使用了图像较短边 [256,480]的尺寸抖动(scale jittering),所以当 =256时,在224××224的裁切图像的测试是负偏向的(原文为:so the test of a 224x224 crop on =256 (as did in ResNet_v1) is negatively biased这句话需要好好理解)。与之相反,在所有原始的以及我们提出的ResNet上,我们从s=320的图像中裁切一个的320××320图像进行测试。 即使ResNets是在更小的裁切图像上进行训练的,但是由于ResNets的全卷积设计,在更大的裁切图像上它们也能够很容易的进行测试。这个尺寸(320x320)和Inception v3使用的299××299的尺寸很接近,因此是一个更公平的比较。
原始的ResNet-152的top-1错误率(on a 320x320 crop)为21.3%,pre-activation的top-1错误率为21.1%。在pre-activation版本上的提高不是很大,因为这个模型并没有出现严重的泛化困难。但是原始的ResNet-200的top-1为21.8%(比原始的ResNet-152高)。但是我们发现,原始的ResNet-200有着比ResNet-152更低的训练误差,表明它可能有点过拟合。
我们的pre-ctivation ResNet-200的top-1为20.7%,比原始的ResNet-200低1.1%并且ResNet-152的两个版本低。当使用[19,20]缩放(scale)和纵横比(aspect ratio augmentation)增强时,我们的ResNet-200的结果优于Inception v3(表5)。与我们同时进行的Inception-ResNet-v2模型的single-crop结果为19.9%/4.9%。我们期望我们的观测和提出的残差单元将会帮助这种类型和其它泛化类型的ResNet的训练。
Computational Cost
我们模型的计算复杂度和深度成正相关(所以1001层网络比100层网络复杂10倍)。在CIFAR上,ResNet-1001用2块GPU训练大概耗时27小时;在ImageNet上,ResNet-200用8块GPU训练大概耗时3周(与VGG网络相当)。
6 结论
本文研究了深度残差网络的连接机制背后的传播公式。我们的推导表明Identity shortcut连接和identity after-addition activation对于信息的顺利传播很重要。Ablation实验出现了和我们公式推导过程中一致的现象。我们也表明1000层深的网络也能够被轻易地训练并且达到更好的准确率。
附录:Implementation Details
本文的实现细节和超参数和ResNet_v1一致。在CIFAR的训练过程中,我们只对图片进行平移(translatation)和(flipping)增强。初始学习率为0.1,在第32k和48k次迭代学习率除以10。根据ResNet_v1,对于所有在CIFAR上的实验,我们在前400个迭代使用一个更小的学习率0.01来预热训练,之后再将学习率调回0.1,尽管我们认为这对本文提出的残差单元并不是必要的。在2块GPU上mini-batch的大小为128(每一块上各64),weight decay为0.0001,动量为0.9,权重采用ResNet_v1类似的初始化方式。
在ImageNet上,我们使用与ResNet_v1一样的数据增强方案来训练模型。初始学习率为0.1(没有预热),然后在第30和60个epochs学习率除以10。在8块GPU上的大小为256(每一块上32)。weight decay、动量和权重初始化方式和上段所述一致。
当使用预激活残差单元(图4d、e和 图5)时,我们特别关注整个网络的第一个和最后一个残差单元。对于第一个残差单元(前面是一个独立的卷积层 ),我们在 后面执行第一个激活,然后再分成两条路径;对于最后一个残差单元(后面接着平均池化层和一个全连接分类器),在它的元素加法后执行一个额外的激活。这两个特殊情况是我们通过Fig.5中的修改程序来获得预激活网络自然而然产生的结果(These two special cases are the natural outcome when we obtain the pre-activation network via the modification procedure as shown in Fig. 5.)。
瓶颈残差单元(对于ResNet-164/1001 on CIFAR)按照ResNet_v1的方式构建。例如,在ResNet-110中,一个 单元将被 单元代替,两者有着相近的参数量。对于瓶颈残差网络,当减小feature map的size,我们使用projection shortcut来增加维度,当使用pre-activation时,pre-activation也适用于这些 projection shortcuts。
【5】 Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation (1997)
【6】 Srivastava, R.K., Greff, K., Schmidhuber, J.: Highway networks. In: ICML work-shop. (2015)
【7】 Srivastava, R.K., Greff, K., Schmidhuber, J.: Training very deep networks. In:NIPS. (2015)
参考博客
https://blog.csdn.net/wspba/article/details/60750007