一、实验机型及架构描述
二、基础环境配置
三、JDK-Hadoop环境配置
四、Hadoop配置文件修改
五、启动hadoop集群(均在adserver操作)
本篇引用文章地址:
https://blog.csdn.net/u014454538/article/details/81103986
一、实验机型及架构描述
本次实验采用 3台 ubuntu16.04实例进行搭建
| 主机名 | IP地址 | 操作系统 | 运行服务 | 角色 |
|---|---|---|---|---|
| adserver | 192.168.200.10 | ubuntu 16.04 | NameNode、SecondaryNameNode、ResourceManager、JobHistoryServer | Master |
| monserver | 192.168.200.20 | ubuntu 16.04 | DataNode、NodeManager | Slave |
| osdserver-1 | 192.168.200.30 | ubuntu 16.04 | DataNode、NodeManager | Slave |
二、基础环境配置
修改主机名,网卡名
设置Ubuntu 16.04静态ip地址,此处仅作方法演示
1.首先查看IP地址

修改网卡配置文件,使其成为静态IP地址,修改好之后需要重启实例生效
$ sudo vi /etc/network/interfaces
修改主机名,此处用
$ sudo hostnamectl set-hostname YOUR_HOSTNAME
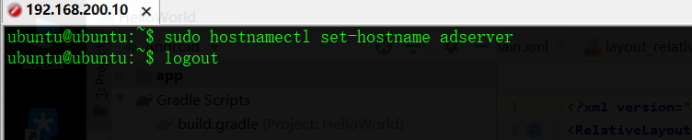
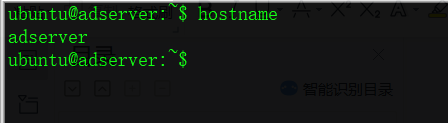
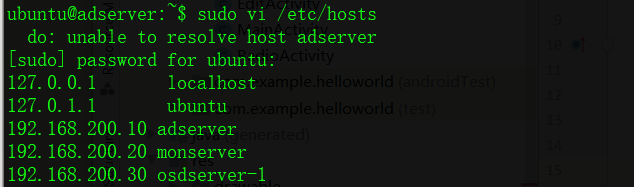
修改hosts,配置fqdn域名
创建hadoop用户,配置免密登录,每个节点都需配置
sudo useradd -d /home/hadoop -m hadoop
sudo passwd hadoop
echo "hadoop ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/hadoop
sudo chmod 0440 /etc/sudoers.d/hadoop

配置ssh免密登录 ,需先安装openssh-server(sudo apt get install openssh-server)
ubuntu@adserver:~$ ssh-keygen
ubuntu@adserver:~$ ssh-copy-id adserver
ubuntu@adserver:~$ ssh-copy-id monserver
ubuntu@adserver:~$ ssh-copy-id osdserver-1


ubuntu@adserver:~$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@adserver
ubuntu@adserver:~$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@monserver
ubuntu@adserver:~$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@osdserver-1


三、JDK-Hadoop环境配置
1、配置JDK环境,此处采用jdk-8u77
下载JDK jdk-8u77-linux-x64.tar.gz
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html

ubuntu@adserver:~$ ls -lh
total 173M
-rw-rw-r-- 1 ubuntu ubuntu 173M Mar 28 09:11 jdk-8u77-linux-x64.tar.gz
ubuntu@adserver:~$ tar -zxf jdk-8u77-linux-x64.tar.gz
ubuntu@adserver:~$ ls -lh
total 173M
drwxr-xr-x 8 ubuntu ubuntu 4.0K Mar 21 2016 jdk1.8.0_77
-rw-rw-r-- 1 ubuntu ubuntu 173M Mar 28 09:11 jdk-8u77-linux-x64.tar.gz

ubuntu@adserver:~$ sudo mkdir /usr/lib/jdk
ubuntu@adserver:~$ sudo mv jdk1.8.0_77/ /usr/lib/jdk/
ubuntu@adserver:~$ sudo ls /usr/lib/jdk/
jdk1.8.0_77

ubuntu@adserver:~$ sudo vi /etc/profile
添加jdk环境
#JDK
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_77
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
export PATH=${
JAVA_HOME}/bin:$PATH


2、配置Hadoop环境
安装Hadoop-2.7.2
下载地址:
https://archive.apache.org/dist/hadoop/core/hadoop-2.7.2/hadoop-2.7.2.tar.gz
解压缩:
ubuntu@adserver:~$ tar -zxf hadoop-2.7.2.tar.gz
ubuntu@adserver:~$ ls -lh
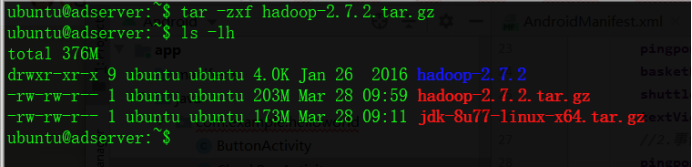
将hadoop移动到/usr/local/目录下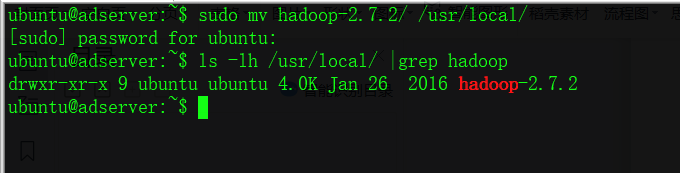
添加Hadoop环境变量
$ sudo vi /etc/profile
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

$ vi ~/.bashrc
#HADOOP
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

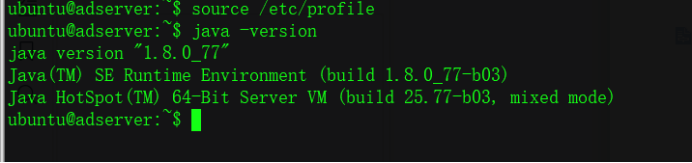
$ source /etc/profile
$ source ~/.bashrc
$ hadoop version
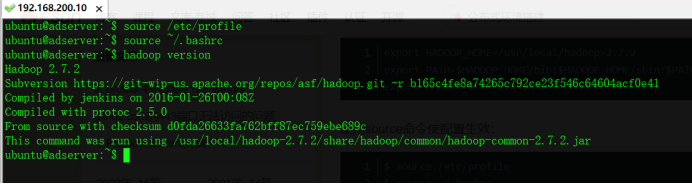
四、Hadoop配置文件修改
修改hadoop配置文件
修改/hadoop-2.7.2/etc/hadoop目录下的hadoop-env.sh、yarn-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1.在hadoop目录下创建tmp文件夹及其子目录
ubuntu@adserver:~$ sudo mkdir -p /usr/local/hadoop-2.7.2/tmp/dfs/data
ubuntu@adserver:~$ sudo mkdir -p /usr/local/hadoop-2.7.2/tmp/dfs/name
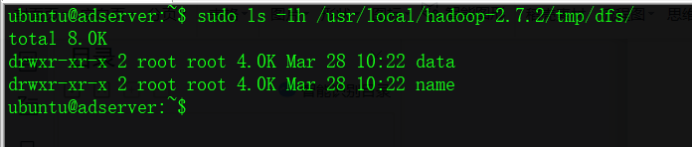
修改配置文件:
首先进入对应文件夹
ubuntu@adserver:~$ cd /usr/local/hadoop-2.7.2/etc/hadoop/

2.添加JAVA_HOME到Hadoop环境配置文件
①添加Java-home到hadoop-env.sh
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_77

② 添加Java-home到yarn-env.sh,直接在第一行添加即可
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_77

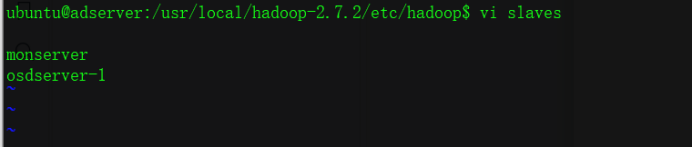
③ 添加slave主机名到slaves
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ vi slaves
monserver
osdserver-1
3.修改对应的配置文件
④ 修改 core-site.xml
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ vi core-site.xml
在 <configuration></configuration>中添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://adserver:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp</value>
<description>Abase for other temporary directories.</description>
</property>

⑤修改hdfs-site.xml文件,
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ vi hdfs-site.xml
在<configuration></configuration>中添加如下内容
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>adserver:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>

⑥修改 mapred-site.xml,需要先复制文件为mapred-site.xml,然后进行修改
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ vi mapred-site.xml
在<configuration></configuration>中添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>adserver:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>adserver:19888</value>
</property>

⑦、修改yarn-site.xml
ubuntu@adserver:/usr/local/hadoop-2.7.2/etc/hadoop$ vi yarn-site.xml
在<configuration></configuration>中添加如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>adserver:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>adserver:8032</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>adserver:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>adserver:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>adserver:8088</value>
</property>

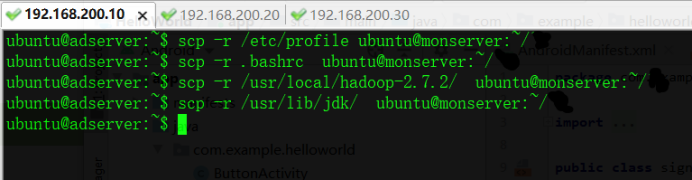
4.使用scp命令将/etc/hosts 、/etc/profile 、 ~/.bashrc 、 jdk、hadoop分别分发给2台slave节点,这里仅作复制到monserver的演示
ubuntu@adserver:~$ scp /etc/hosts ubuntu@monserver:~/
ubuntu@adserver:~$ scp -r /etc/profile ubuntu@monserver:~/
ubuntu@adserver:~$ scp -r .bashrc ubuntu@monserver:~/
ubuntu@adserver:~$ scp -r /usr/local/hadoop-2.7.2/ ubuntu@monserver:~/
ubuntu@adserver:~$ scp -r /usr/lib/jdk/ ubuntu@monserver:~/


ubuntu@monserver:~$ sudo mv hosts /etc/hosts
ubuntu@monserver:~$ sudo mv hadoop-2.7.2/ /usr/local/
ubuntu@monserver:~$ sudo mv jdk/ /usr/lib/
ubuntu@monserver:~$ sudo update-alternatives --install /usr/bin/java java /usr/lib/jdk/jdk1.8.0_77/bin/java 300
ubuntu@monserver:~$ sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jdk/jdk1.8.0_77/bin/javac 300
ubuntu@monserver:~$ source /etc/profile
ubuntu@monserver:~$ source .bashrc
ubuntu@monserver:~$ java -version
ubuntu@monserver:~$ hadoop version


设置所有节点hadoop-2.7.2的文件夹权限为0777:
设置所有节点hadoop-2.7.2的文件夹权限为0777:
设置所有节点hadoop-2.7.2的文件夹权限为0777:
ubuntu@adserver:~$ sudo chmod -R 0777 /usr/local/hadoop-2.7.2
ubuntu@monserver:~$ sudo chmod -R 0777 /usr/local/hadoop-2.7.2
ubuntu@osdserver-1:~$ sudo chmod -R 0777 /usr/local/hadoop-2.7.2

五、启动hadoop集群(均在adserver操作)
① 初始化namenode
ubuntu@adserver:~$ hadoop namenode -format
注意:首次运行需要执行初始化,之后不需要。
成功运行,应该返回Exitting with status 0,提示Shuting down Namenode at adserver/xxx.xxx.xxx.xx(adserver的IP地址),具体结果如下图所示:

②启动Hadoop的守护进程(NameNode, DataNode, ResourceManager和NodeManager等)
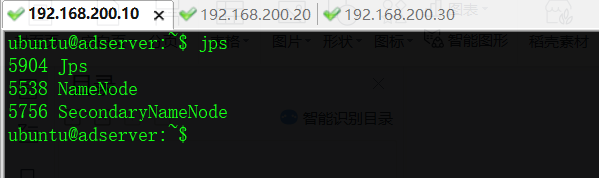
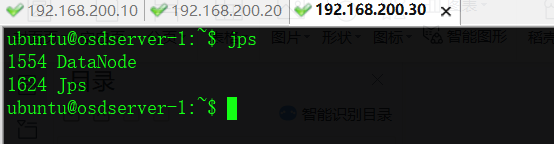
A、首先启动NameNode、SecondaryNameNode、DataNode
在adserver节点执行
ubuntu@adserver:~$start-dfs.sh

此时master节点上面运行的进程有:NameNode、SecondaryNameNode
此时slave节点上面运行的进程有:DataNode
B、启动ResourceManager、NodeManager
$ start-yarn.sh

YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性
此时master节点上面运行的进程有:NameNode、SecondaryNameNode、ResourceManager
slave节点上上面运行的进程有:DataNode、NodeManager
C、启动JobHistoryServer
$ mr-jobhistory-daemon.sh start historyserver
注:master节点将会增加一个JobHistoryServer 进程
注意:多次重启以后,一定要删除每个节点上的logs、tmp目录,并重新创建tmp目录
查看三台节点运行状态
ubuntu@adserver:~$ jps
ubuntu@adserver:~$ ssh monserver "/usr/lib/jdk/jdk1.8.0_77/bin/jps"
ubuntu@adserver:~$ ssh osdserver-1 "/usr/lib/jdk/jdk1.8.0_77/bin/jps"

