实验环境
虚拟机:Virtualbox
系统:CentOS-6.5
JDK:jdk-8u172-linux-x64.tar
Hadoop版本:Hadoop-2.7.3
上述软件均是开源,大家可以网上自行下载
一、CentOS6.5安装
1.打开Virtualbox,点击新建
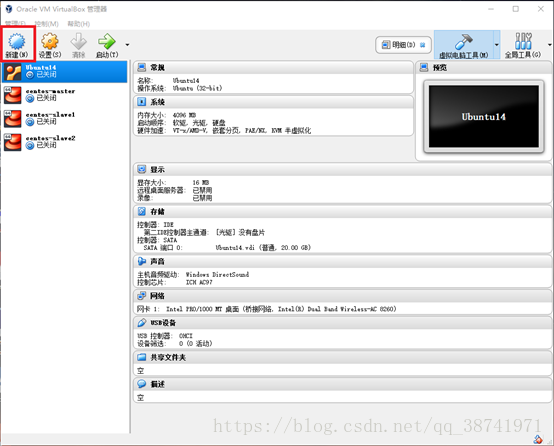
2.输入第一台机器名centos6.5-matser,类型选择linux,版本选择Red Hat(64-bit)
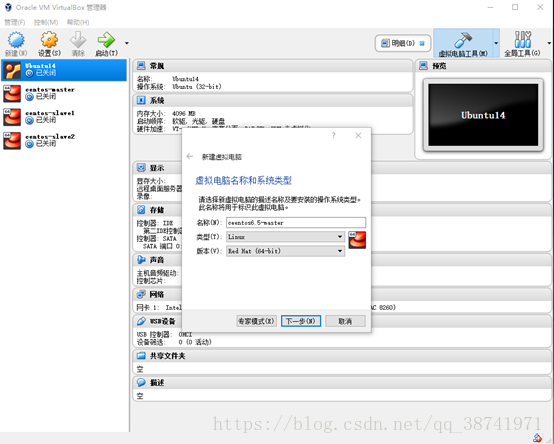
3.设置分配内存大小,电脑8G内存的可以选择分配1024MB即可

4.选择现在创建虚拟硬盘

5.选择VDI模式

6.选择动态分配

7.创建虚拟硬盘分配20GB的大小
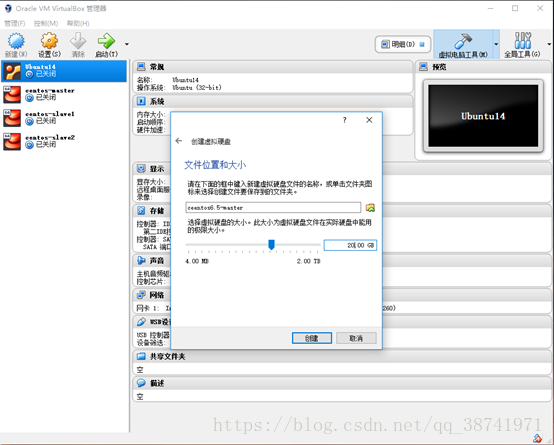
8.重复上述2-7步骤,完成另外两台机器slave1,slave2的创建

#下述步骤,每台机器都要执行
9.完成机器创建后,需要选中机器点击网络

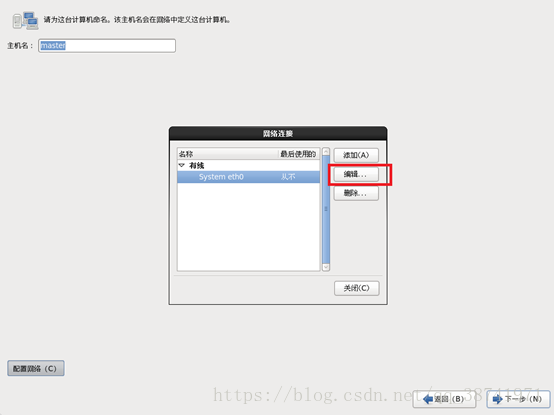
10.选择桥接网卡,在这里dodo使用的是无线(寝室校园网需要特别注意,建议使用自己的手机无线),所以用的是无线网卡,界面名称选择为dodo电脑的Intel(R)Dual…,混杂模式选择全部允许,详细同下图

11.选中机器,并启动
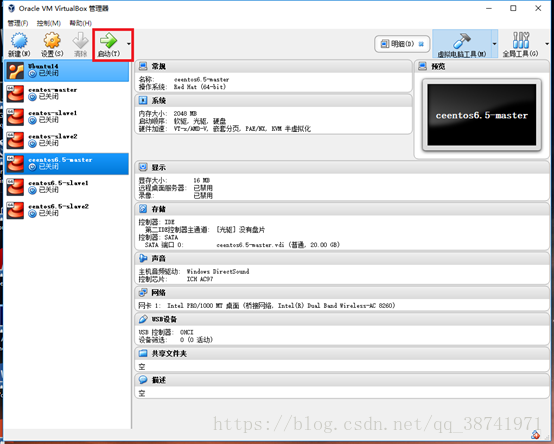
12.为机器选择下载好的ISO文件,这里dodo使用的是centos6.5

13.选择skip跳过即可

14.选中Install or upgrade an existing system,键盘点击Enter
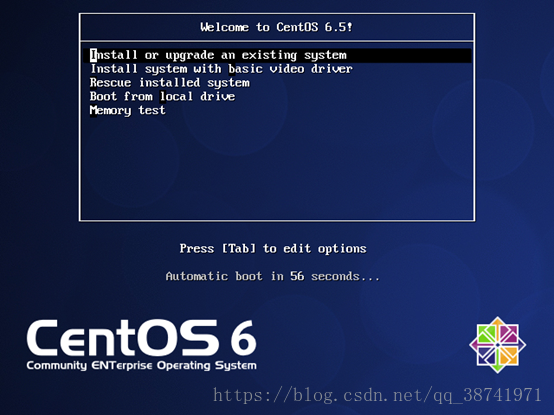
14.进入安装界面,点击next

15.选择语言
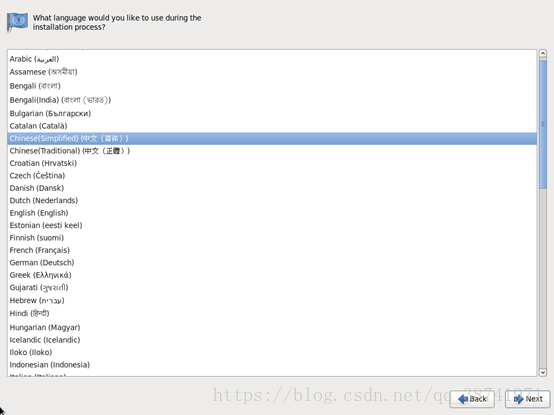
16.选择键盘,这里都是美国英语式,不建议变更,点击下一步
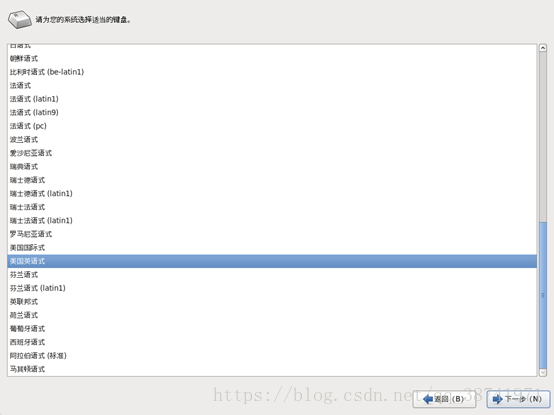
17.选择基本存储设备,点击下一步
18.选择:是,忽略所有数据 ,点击下一步

19.1.第一台主机名是master,后面两台主机名分别是slave1,slave2

19.2.一定一定一定要记得点击配置网络
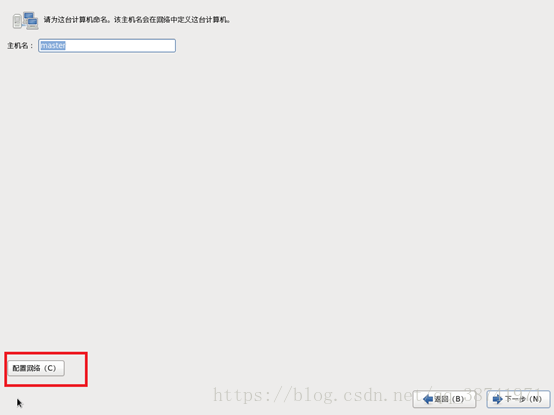
19.3编辑网络,勾选上自动连接,点击应用。下一步

20.取消勾选系统时钟使用UTC时间,城市选择亚洲/上海,点击下一步

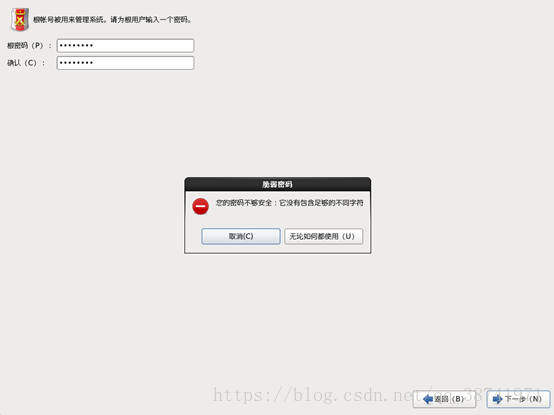
21.创建root用户的密码,密码过于简单,直接无论如何都使用即可,点击下一步
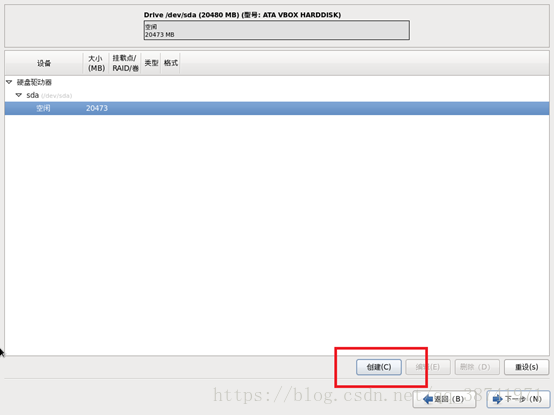
22.1.选择创建自定义布局,点击下一步

22.2鼠标选中空闲,点击创建,创建标准分区

22.3文件系统类型为swap,分配大小为4096MB

22.4第二块文件系统类型选择ext4,注意挂载点为 / ,下方选择使用全部空间

22.5自定义布局完成,点击下一步

22.6格式化即可,点击下一步
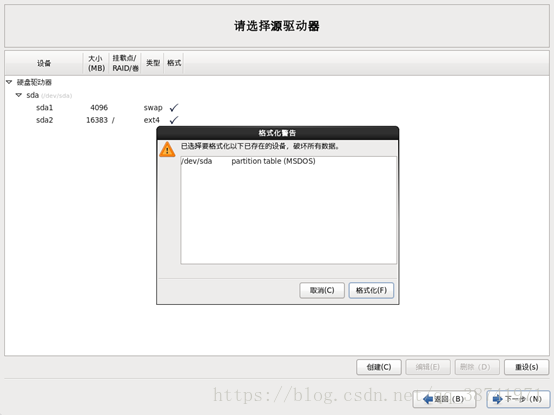
22.7将修改写入磁盘,点击下一步

22.8,点击下一步
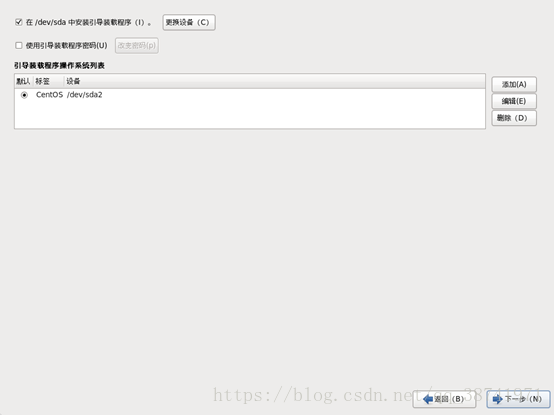
23,我们点击选中BasicServer,统一三台机器都是终端界面即可(有需求图形界面的同学选择Desktop),点击下一步

24.等待安装

25.点击重新引导,完成重启

26.重复9~25步骤,完成另外两台机器的创建
27.输入ifconfig,查看网络状态,inet addr 地址存在即可。并且三台机器的Ip网段一致,如下方192.168.43.xxx

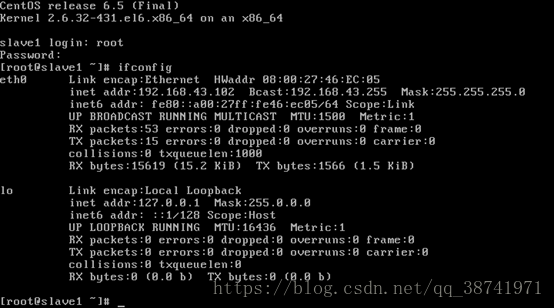

28.至此,三台机器搭建完成
二、配置三台机器之间ssh免密码登录
| 192.168.43.196 | master |
| 192.168.43.102 | slave1 |
| 192.168.43.242 | slave2 |
#每个节点都需要执行
#编辑/etc/profile
vim /etc/hosts
#生成公钥和私钥
ssh-keygen -t rsa #一路回车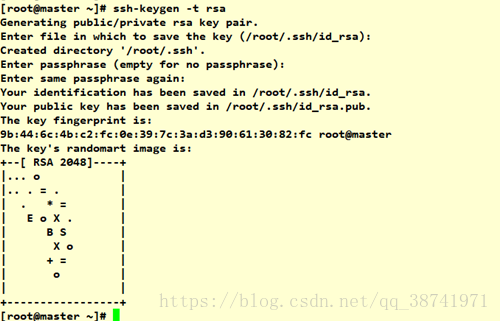
# 将公钥添加到认证文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 并设置authorized_keys的访问权限
chmod 600 ~/.ssh/authorized_keys
#只在一个节点上执行即可
# 只要在一个节点执行即可。这里在 192.168.43.196上执行,将两个字节点的认证文件追加到主节点的认证文件中
ssh 192.168.43.102 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
ssh 192.168.43.242 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys# 此时,主节点上的认证文件就含有三个主机的认证证书内容,分发整合后的文件到其它节点
scp ~/.ssh/authorized_keys 192.168.43.102:~/.ssh/
scp ~/.ssh/authorized_keys 192.168.43.242:~/.ssh/#测试是否免密
# 测试时,第一次,需要输入密码,之后就不需要输入密码了。
# 在192.168.43.196上测试,进入操作其他主机时可以敲入exit退出
ssh 192.168.43.102
ssh 192.168.43.242
# 在192.168.43.102上测试
ssh 192.168.43.196
ssh 192.168.43.242
# 在192.168.43.242上测试
ssh 192.168.43.196
ssh 192.168.43.102三、使用putty进行虚拟机的操作
putty能够给我们模拟虚拟机的界面,方便我们的操作,可以使用复制和粘贴,在后期需要配置环境变量的时候会很方便,但是有时候大家会苦恼没法永久设置字体样式,下面给大家提供方法
1.打开putty

2. 输入虚拟机的ip地址号端口号22
创建Save Sessions cos2 ,点击Save,选中cos2
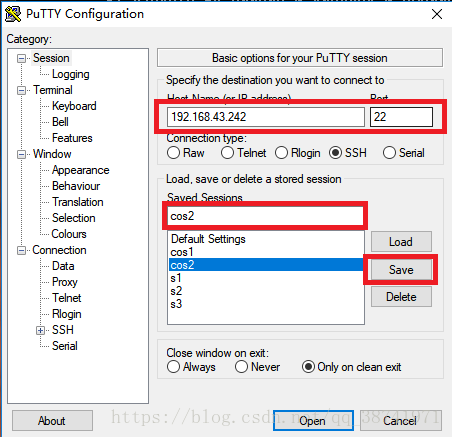
3.点击appearance,选中change,设置字体样式

4.点击colours,分别设置前景色(字体色)和背景色(页面的颜色)

5.点击界面上方session,完成设置后点击save
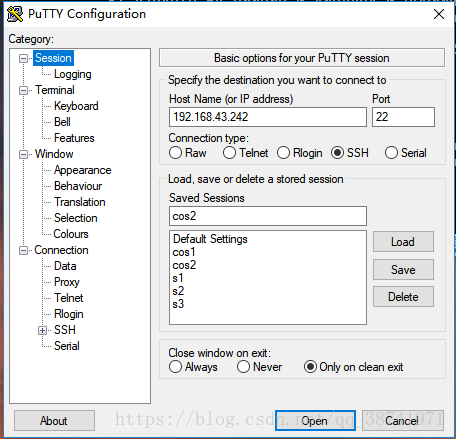
6.下次再启动putty点击cos2,点击open即可,不需要再重新设置字体样式和起前景色背景色
7. 三台机器同理设置,使用putty会方便我们的代码粘贴,操作更加方便快捷
四、jdk的卸载与安装
1.为三台主机添加统一的用户和密码
# 添加用户
useradd hadoop
# 修改密码
passwd hadoop
#仅在master节点上操作
2.在master的/home/hadoop目录下创建download目录,将jdk,和hadoop文件传入
cd /home/Hadoop
mkdir download
3.打开filezilla
输入master的IP地址,用户名root,密码 端口号22,点击快速链接
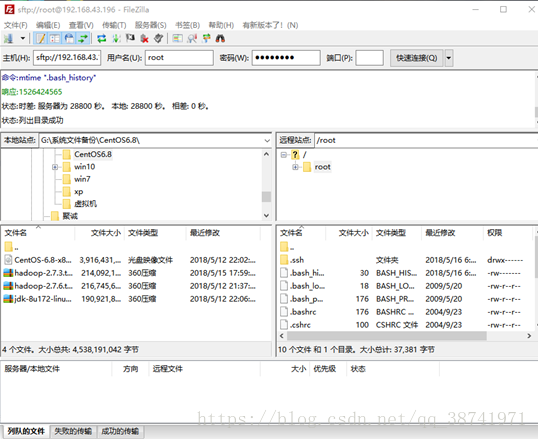
4. 找到windows下存放文件的路径,并且选择好master的目录路径,传送文件
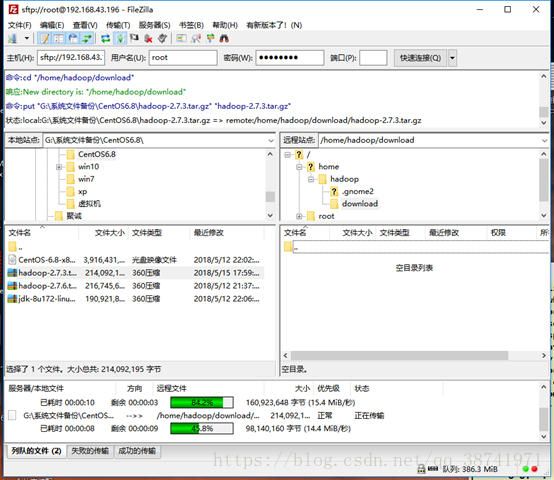
5.查看文件是否传送
ls /home/hadoop/download
#每个节点都需要操作
1.检查当前本机安装的JDK
rpm -qa|grep jdk
2.卸载本机自带的JDK
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
3.查询当前系统相关的Java目录,并且删除
whereis java4.删除查询出的结果目录
rm -rf /etc/java
rm -rf /usr/lib/java
rm -rf /usr/share/java
#仅在master节点上操作
5.在/usr下创建目录java,将/home/Hadoop/download目录下的jdk解压到/usr/java下
cd /usr
mkdir java
tar -zxvf /home/hadoop/download/jdk-8u172-linux-x64.tar.gz -C /usr/java
6..编辑vim /etc/profile 文件,在文件末尾追加
JAVA_HOME=/usr/java/jdk1.8.0_172
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
7.退出编辑器,刷新/etc/profile使之生效
source /etc/profile8.检查JDK状态
java –version
javac -version

9.回到/usr目录下将java文件打包
tar -zcvf java.tar.gz java10.将打包的java.tar.gz文件分发到子节点slave1,slave2的/usr下
scp /usr/java.tar.gz [email protected]:/usr
scp /usr/java.tar.gz [email protected]:/usr
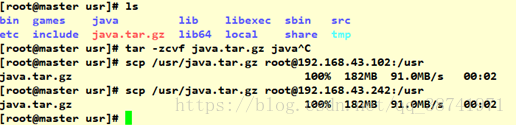
#到slave1,slave2节点上操作
11.在字节点slave1,slave2上的/usr目录下将java.tar.gz文件解压
tar -zxvf java.tar.gz12.分别编辑slave1,slave2节点的/etc/profile文件
JAVA_HOME=/usr/java/jdk1.8.0_172
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
13.退出编辑器,刷新/etc/profile使之生效
source /etc/profile14.分别对子节点使用javac –version检查
#所有节点都需要操作
15.将/usr/java文件用户和用户组修改为hadoop,使用ll -al查看
chown -R hadoop:hadoop java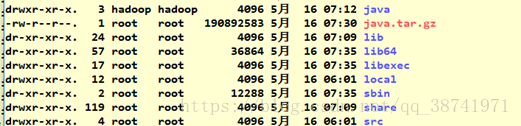
16.至此,完成JDK的配置
五、Hadoop安装配置
#所有节点执行
1.关闭selinux
vi /etc/sysconfig/selinuxSELINUX=disabled
2.关闭主机的防火墙
chkconfig -off iptables
chkconfig -off ip6tables3.查看防火墙是否全关闭(如果没有重复步骤2)
chkconfig iptables --list
chkconfig iptables --list#在master节点下操作
4.将hadoop-2.7.3.tar.gz解压到/usr下
tar -zxvf /home/hadoop/download/hadoop-2.7.3.tar.gz -C /usr5.进入/usr下,将hadoop-2.7.3改名为hadoop
mv hadoop-2.7.3 hadoop6..进入hadoop/etc/hadoop下,修改hadoop-env.sh文件
cd /usr/hadoop/etc/hadoop
vim hadoop-env.sh# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_1727.修改core-site.xml
vim core-site.xml<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>8.修改hdfs-site.xml
vim hdfs-site.xml<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
</configuration>9.修改yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>10.修改mapred-site.xml
vim mapred-site.xml<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>12.修改slaves,添加两个子节点的ip地址
192.168.43.102
192.168.43.24213.进入 /usr ,打包hadoop
cd /usr
tar -zcvf hadoop.tar.gz hadoop14.将hadoop.tar.gz发送到两个子节点的/usr下
scp /usr/hadoop.tar.gz [email protected]:/usrscp /usr/hadoop.tar.gz [email protected]:/usr切换到slave1,slave2主机,分别将hadoop.tar.gz解压
tar -zxvf hadoop.tar.gz#三个节点都需要执行
1.配置hadoop的环境变量,在/etc/profile下追加
vim /etc/profileHADOOP_HOME=/usr/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin2.刷新/etc/profile
source /etc/profile#回到master主机节点
1.格式化namenode节点
hdfs namenode -format
2.启动hdfs
start-dfs.sh#每个节点运行jps
jps

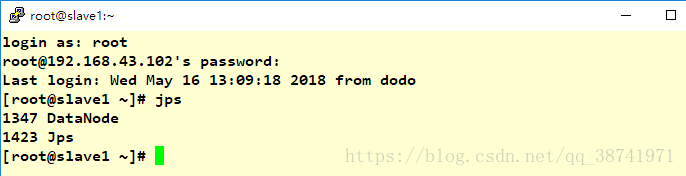

在window上输入 http://192.168.43.196:50070/
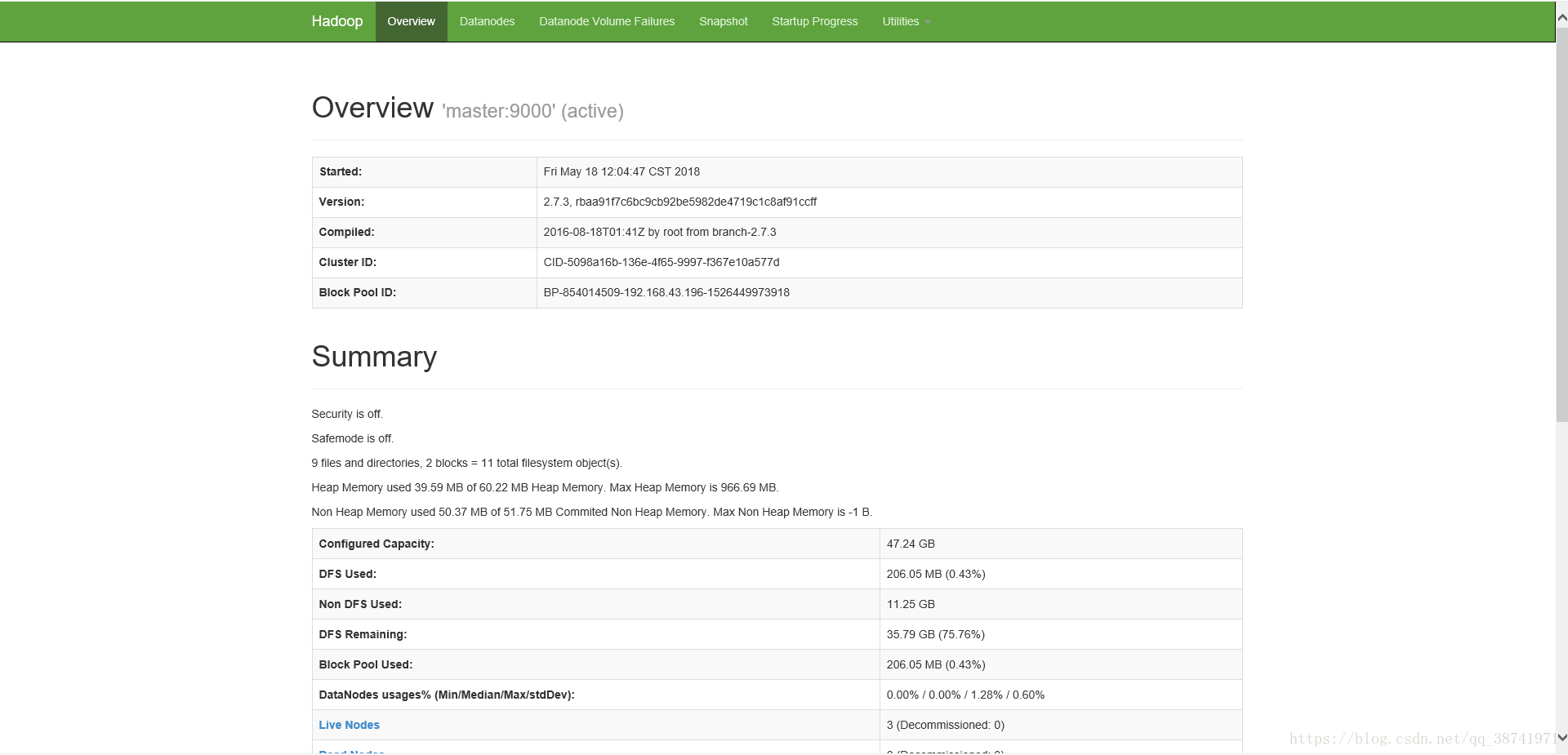
至此,集群搭建完毕