本次环境搭建使用Ubuntu虚拟机完成
在搭建Hadoop环境之前需要安装VMware和Ubuntu虚拟机,这边就不再赘述,在本文中使用了Ubuntu16.04作为虚拟机,一共四台虚拟机,其中一台作为NameNode其他三台作为DataNode,因为有很多配置都是重复的,所以我们先在一台机器上配置完成之后,采用复制虚拟机的方式完成所有机器的环境配置
安装JDK
NameNode也就是master节点的ip 是192.168.88.130,在这台机器上首先安装JDK,JDK版本是1.8.0_151,下载JDK之后进行解压,
tar -zxvf jdk-8u151-linux-x64.tar.gz
然后将解压出来的文件夹放到/usr/local/下(需要root权限)
sudo mv jdk1.8.0_151 /usr/local/
在 /etc/profile 文件中设置环境变量
#set Java environment
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/binsource /etc/profile 让环境变量生效
使用java -version进行验证
安装Hadoop
首先从官网上下载Hadoop压缩包 hadoop-2.6.5.tar.gz 进行解压
tar -zxvf hadoop-2.6.5.tar.gz
扫描二维码关注公众号,回复: 943587 查看本文章
同样的使用mv 命令将解压完的文件夹放到 /usr/local/目录下
修改/usr/local/hadoop-2.6.5/etc/hadoop/hadoop-env.sh文件中的jdk安装地址为
export JAVA_HOME=/usr/local/jdk1.8.0_151
修改/etc/profile 文件,添加Hadoop环境变量,修改后如下所示
export JAVA_HOME=/usr/local/jdk1.8.0_151
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin运行hadoop version 如下图所示

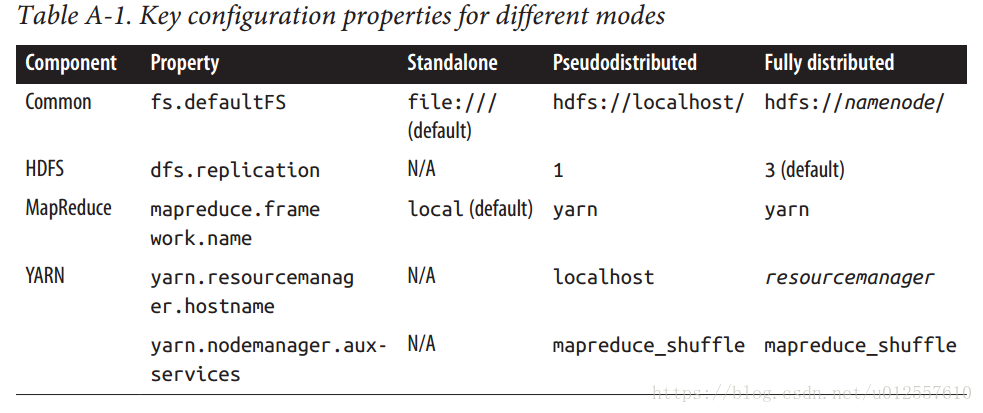
Hadoop 有三种运行模式:
- 第一种是独立模式不会创建守护进程适合开发的时候进行调试,独立模式下会使用本地文件系统,运行本地MapReduce Job
- 第二种是伪分布式模式,所有的守护进程都在同一个机器中运行,也就是在本机上模拟分布式环境
- 第三种是完全分布式模式,守护进程运行在不同的物理主机上
三种模式的不同点如下图所示
如果不做其他的配置默认会在独立模式下运行,本文主要介绍的是完全分布式模式下的运行,所有还需要做下面的一些配置项
伪分布模式配置
为了在机器上同时存在多个模式的配置,首先通过下面的命令拷贝配置文件所在文件夹并生成一个软链接
cp -r /usr/local/hadoop-2.6.5/etc/hadoop /usr/local/hadoop-2.6.5/etc/hadoop_pseudo
cd /usr/local/hadoop-2.6.5/etc/
ln -s hadoop_pseudo hadoop
修改hadoop_pseudo中的配置文件,如下所示,一共四个文件,其中mapred-site.xml可以通过复制mapred-site.xml.template文件得到,修改以下四个文件就完成了基本的配置,其中
core-site.xml是核心配置文件,用来说明HDFS的NameNode
hdfs-site.xml是用来配置HDFS的副本数量的,副本数量和DataNode的数量一致
mapred-site.xml用来说明mapreduce使用的框架
yarn-site.xml用来说明yarn框架的RM节点是谁
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>此外还需要安装SSH,节点之间的通信需要SSH的支持
sudo apt-get install ssh
ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
使用 ssh localhost测试是否完成
格式化HDFS文件系统
hdfs namenode -format
启动守护进程
start-dfs.sh
start-yarn.sh
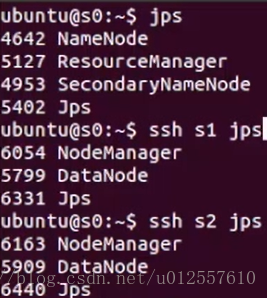
或者可以使用start-all.sh启动所有的守护进程,但是这个方法被废弃了,推荐使用一个个启动的方式,启动完成之后,使用jps命令查看java进程,如下图所示

完全分布模式配置
将上面配置完成的虚拟机再复制三个,
master ip 192.168.88.130
s1 ip 192.168.88.131
s2 ip 192.168.88.132
s3 ip 192.168.88.133
修改主机名称
修改每台虚拟机的/etc/hostname 文件,依次改为master,s1 ,s2,s3
为配置文件夹创建软链接
和伪分布式一样,可以采用软链接的形式,避免在命令行中加–config参数,直接复制一份伪分布式的配置文件
cd /usr/local/hadoop-2.6.5/etc/
cp -r hadoop_pseudo hadoop_cluster
ln -s hadoop_cluster hadoop
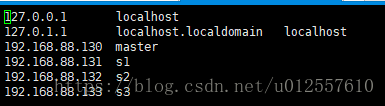
修改/etc/hosts文件,每一台机器都需要一致,可以使用scp命令进行远程拷贝或者一台一台进行修改
修改master节点的hadoop配置文件
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master/</value>
</property>
</configuration>- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>- mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>修改slaves文件,添加两行
s1
s2
根据上述配置,目前master这台机器是作为NameNode和RM,另外三台机器中的两台是DataNode,另一台可以作为SecondaryNameNode(在上面的配置中没有进行配置)在完成上面的配置后,需要将上述的配置同步到所有的节点,同样的可以使用scp远程拷贝同步到不同的节点上去
cd /usr/local/hadoop-2.6.5/
scp -r ./etc/ master@s1:/usr/local/hadoop-2.6.5/
scp -r ./etc/ master@s2:/usr/local/hadoop-2.6.5/
scp -r ./etc/ master@s3:/usr/local/hadoop-2.6.5/
重新格式化文件系统
hadoop namenode -format
启动hadoop
start-all.sh
结尾
通过上面的几个步骤,就完成了Hadoop的完全分布模式配置
参考资料
[1]Hadoop The Definitive Guide 4th Edition
[2]Hadoop 官方文档