完全分布式运行模式
准备三台虚拟机
克隆虚拟机
本文在hadoop环境搭建(二)伪分布式运行模式中的虚拟机(hadoop-00)为模板进行克隆,或者自行准备3台安装了hadoop和jdk的centos的虚拟机
克隆出3台虚拟机 分别为:
hadoop-01
hadoop-02
hadoop-03
以克隆出hadoop-01为例子
克隆步骤如下:




对克隆出的虚拟机ip分配和hostname修改
修改每台虚拟机ip和修改主机名字
参考hadoop环境搭建(一)中修改ip和主机名自的方法
我进行如下分配修改:
192.168.218.133 hadoop-01
192.168.218.134 hadoop-02
192.168.218.135 hadoop-03
后面的操作在那一台虚拟机注意看主机名!
编写xsync集群分发脚本
需求:循环复制文件到所有节点的相同目录下
- 在/home/atguigu目录下创建bin目录,并在bin目录下创建xsync文件:
[zyy@hadoop-01 ~]$ cd /home/zyy
[zyy@hadoop-01 ~]$ mkdir bin
[zyy@hadoop-01 ~]$ cd bin/
[zyy@hadoop-01 bin]$ touch xsync
[zyy@hadoop-01 bin]$ vi xsync
该文件中编写如下代码:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- Hadoop-0$host --------------
rsync -rvl $pdir/$fname $user@hadoop-0$host:$pdir
done
-
修改脚本 xsync 具有执行权限
[zyy@hadoop-01 bin]$ chmod 777 xsync -
调用脚本方法:
xsync 文件名称
如将 /home/zyy/bin 分发到hadoop-02和hadoop-03
[zyy@hadoop-01 bin]$ xsync /home/zyy/bin
查看分发结果:
hadoop-02中
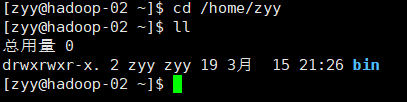
hadoop-03中

说明分发成功脚本编写成功!
集群配置
集群部署规划

配置集群
(1)核心配置文件
-
配置core-site.xml
[zyy@hadoop-01 bin]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/ [zyy@hadoop-01 hadoop]$ vi core-site.xml编写修改成如下配置:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hadoop-01:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>

(2)HDFS配置文件
- 配置hadoop-env.sh
[zyy@hadoop-01 hadoop]$ vi hadoop-env.sh
#配置内容如下:
export JAVA_HOME=/opt/module/jdk1.8.0_162

- 配置hdfs-site.xml
[zyy@hadoop-01 hadoop]$ vi hdfs-site.xml
#配置内容如下:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Hadoop-03:50090</value>
</property>

(3)YARN配置文件
- 配置yarn-env.sh
[zyy@hadoop-01 hadoop]$ vi yarn-env.sh
#配置内容如下
export JAVA_HOME=/opt/module/jdk1.8.0_162

- 配置yarn-site.xml
[zyy@hadoop-01 hadoop]$ vi yarn-site.xml
#配置内容如下
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop-02</value>
</property>

(4)MapReduce配置文件
- 配置mapred-env.sh
[zyy@hadoop-01 hadoop]$ vi mapred-env.sh
#配置内容如下
export JAVA_HOME=/opt/module/jdk1.8.0_162

- 配置mapred-site.xml
[zyy@hadoop-01 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[zyy@hadoop-01 hadoop]$ vim mapred-site.xml
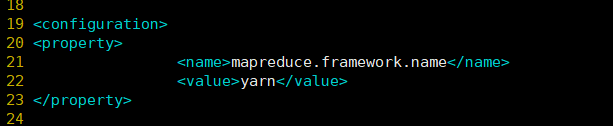
#配置内容如下:
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)集群上分发配置好的Hadoop配置文件
[zyy@hadoop-01 hadoop]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop
(6)格式化NameNode
- 如果是hadoop环境搭建(二)伪分布式运行模式中的虚拟机(hadoop-00)为模板进行克隆的:进行这一步,如果不是且没有启动过集群可以跳过第一步
#删除 data/ logs/
[zyy@hadoop-01 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/
[zyy@hadoop-01 hadoop-2.7.2]$ rm -rf data/ logs/
[zyy@hadoop-02 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/
[zyy@hadoop-02 hadoop-2.7.2]$ rm -rf data/ logs/
[zyy@hadoop-03 hadoop-2.7.2]$ cd /opt/module/hadoop-2.7.2/
[zyy@hadoop-03 hadoop-2.7.2]$ rm -rf data/ logs/
- 格式化
[zyy@hadoop-01 hadoop-2.7.2]$ bin/hdfs namenode -format
SSH无密登录配置
- 生成公钥和私钥
[zyy@hadoop-01 hadoop-2.7.2]$ cd ~
[zyy@hadoop-01 ~]$ cd .ssh/
[zyy@hadoop-01 ~]$ ssh-keygen -t rsa
然后连续3个回车

- 将公钥拷贝到要免密登录的目标机器上
[zyy@hadoop-01 ~]$ ssh-copy-id Hadoop-01
[zyy@hadoop-01 ~]$ ssh-copy-id Hadoop-02
[zyy@hadoop-01 ~]$ ssh-copy-id Hadoop-03
注意:
这个只是hadoop-01的
还需要在hadoop-02和hadoop-03重复以上两个步骤
群起集群
- 配置slaves
[zyy@hadoop-01 ~]# vim /opt/module/hadoop-2.7.2/etc/hadoop/slaves
#配置内容如下:
hadoop102
hadoop103
hadoop104
注意修改时不要有多余的空格或换行字符!
- 同步所有节点配置文件
[zyy@hadoop-01 .ssh]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop/slaves
无密设置后就不需要输入密码了!

- 启动集群
启动HDFS
[zyy@hadoop-01 .ssh]$ cd /opt/module/hadoop-2.7.2/
[zyy@hadoop-01 hadoop-2.7.2]$ sbin/start-dfs.sh

在hadoop-01,hadoop-02,hadoop-03分别查看
[zyy@hadoop-01 hadoop-2.7.2]$ jps
4585 DataNode
4477 NameNode
4831 Jps
[zyy@hadoop-02 .ssh]$ jps
3969 DataNode
4060 Jps
[zyy@hadoop-03 .ssh]$ jps
4068 Jps
3896 DataNode
3994 SecondaryNameNode
- 启动YARN
[zyy@hadoop-02 .ssh]$ cd /opt/module/hadoop-2.7.2/
[zyy@hadoop-02 hadoop-2.7.2]$ sbin/start-yarn.sh
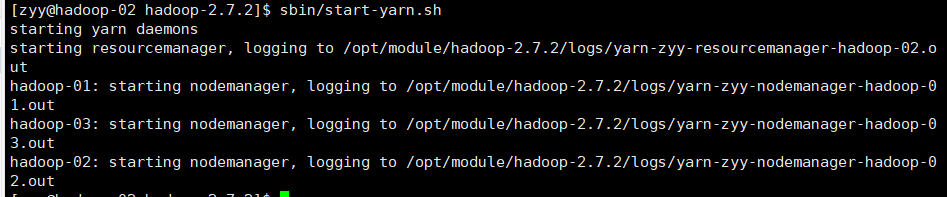
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
到这里就收工了,完全分布式就部署好了!!!!!
