实验环境
namenode: 192.168.103.4
datanode1:192.168.103.15
datanode2: 192.168.103.5
datanode3: 192.168.103.3
操作系统: ubuntu-16.04-x64
hadoop版本: apache-hadoop-2.6.5
jdk版本:1.8
安装步骤
1.安装jdk
jdk的安装过程此处不赘述,不熟悉的话可以参考网上的资料。
2.修改主机映射并配置ssh免密码登录
为了方便配置信息的维护,我们在hadoop配置文件中使用主机名来标识一台主机,那么我们需要在集群中配置主机与ip的映射关系。
修改集群中每台主机/etc/hosts文件,添加如下内容。
192.168.103.4 namenode
192.168.103.15 datanode1
192.168.103.5 datanode2
192.168.103.3 datanode3
集群在启动的过程中需要ssh远程登录到别的主机上,为了避免每次输入对方主机的密码,我们需要对namenode配置免密码登录
在namenode上生成公钥。
ssh-keygen
一路enter确认即可生成对应的公钥。
将namenode的公钥拷贝到datanode1, datanode2, datanode3节点上。
ssh-copy-id -i ~/.ssh/id_rsa.pub root@datanode1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@datanode2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@datanode3
3. namenode配置hadoop,并复制到其余节点
下载hadoop 安装包,点击这里获取hadoop-2.6.5。
解压安装包
tar xf hadoop-2.6.5.tar.gz修改etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_91修改etc/hadoop/core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://namenode:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop-2.6.5/tmp</value> </property>修改etc/hadoop/hdfs-site.xml
<property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-2.6.5/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-2.6.5/tmp/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property>修改etc/hadoop/mapred-site.xml
扫描二维码关注公众号,回复: 1443945 查看本文章
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>修改etc/hadoop/slaves
datanode1 datanode2 datanode3将配置好的hadoop安装包拷贝到其余的datanode上。
scp -r hadoop-2.6.5 root@datanode1:/opt scp -r hadoop-2.6.5 root@datanode2:/opt scp -r hadoop-2.6.5 root@datanode3:/opt
4.启动集群,并验证是否成功
格式化分布式文件系统(在namenode节点上执行)
./bin/hadoop namenode -format
启动集群dfs
./sbin/start-dfs.sh
在namenode和datanode节点上查看进程
namenode:
root@namenode:/opt/hadoop-2.6.5# jps
14941 Jps
14478 NameNode
14703 SecondaryNameNode
datanode1:
root@datanode1:~# jps
13569 DataNode
13757 Jps
datanode2:
root@datanode2:~# jps
17178 Jps
16970 DataNode
datanode3:
root@datanode3:~# jps
4586 DataNode
4815 Jps
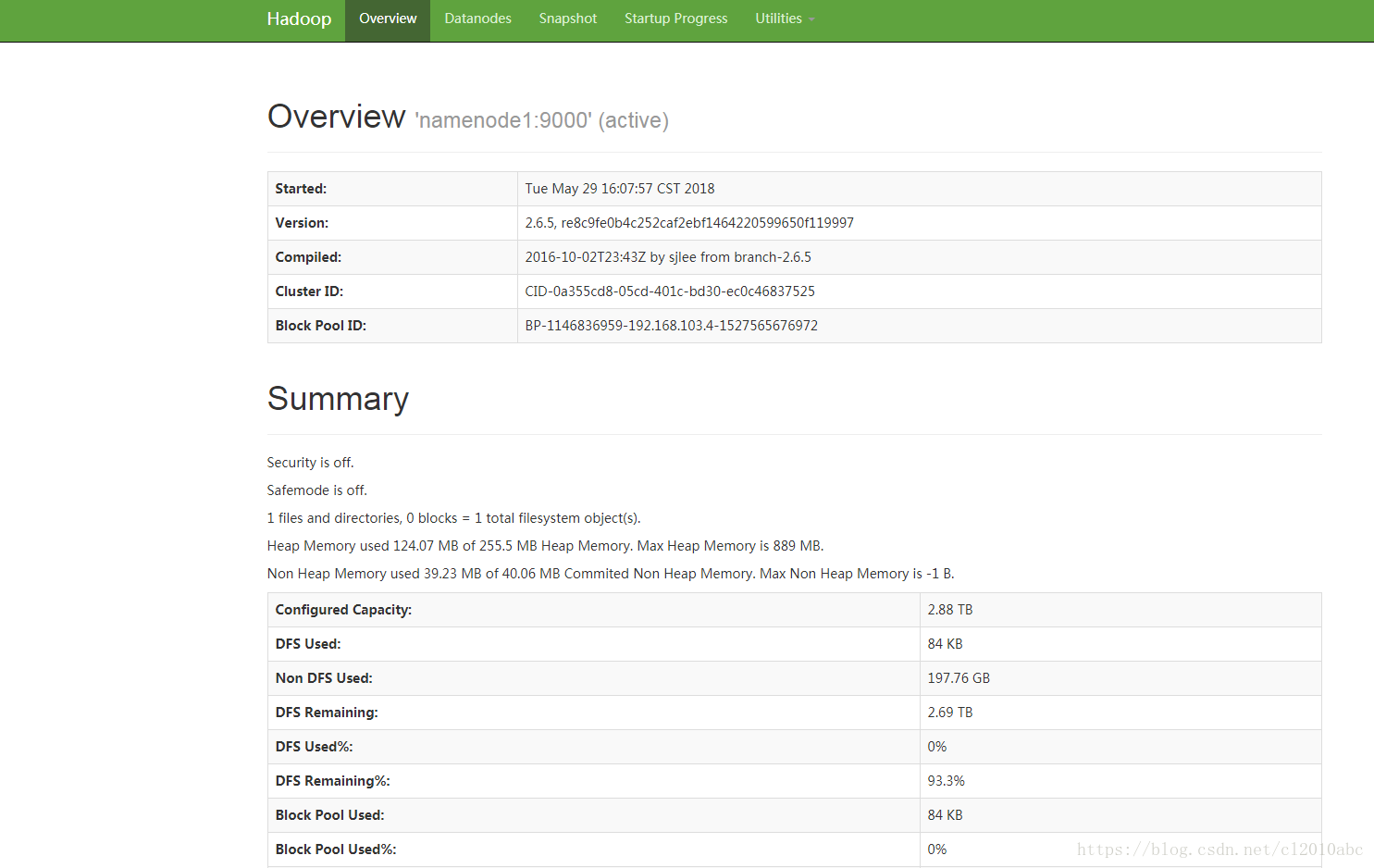
访问hadoop 集群的web界面
http://192.168.103.4:50070/