文章目录
写在前面:《一种基于DTW聚类的水文时间序列相似性挖掘方法》;期刊:《计算机科学》;主办单位:重庆西南信息有限公司;中文核心
作者介绍:


1 摘要
- 先对数据进行小波去噪、特征点分段 以及 语义划分;
- 基于DTW距离对划分后的子序列,做层次聚类并符号化;
- 根据符号序列间的编辑距离,筛选候选集;
- 最后通过序列间的DTW距离进行精确匹配,获取相似水文时间序列。
实验数据:以滁河六合站的日水位数据进行实验, 结果表明,所提方法能够有效地缩小候选集, 提高查找语义相似的水文时间序列的效率。
2 引言
-
水文时间序列的相似性分析,可以回答防汛指挥中经常会问到的 “当前水文过程相当于历史上哪一时期的同类过程” 等问题, 同时也是研究时序关联规则挖掘、聚类、模体挖掘以及异常发现等问题的基础,因而在洪水预报、防洪调度等方面有着重要的意义。
-
在水文时间序列 相似性查询中,时间序列降维和相似性度量方式,是相似性分析研究的热点问题。
2.1 现有的研究
-
基于特征点的分段表示法,能在保留子序列语义的基础上,实现有效的时间序列降维,在水文时间序列相似性挖掘中被广泛应用。
例如:
《水文时间序列相似性查询的分析与研究》
《基于Hadoop水文时间序列相似性研究与应用》
《水文时间序列相似性查询优化算法》
《基于语义相似的水文时间序列相似性挖掘》 -
时间序列符号化的经典算法SAX,SAX采用PAA算法对时间序列进行降维,用不同的符号代表相应平均值的子序列,具有简单易用的特点。然而,PAA算法等长划分时往往会破坏语义,导致符号化效果不理想,因此后期的符号化算法多是基于SAX算法,并结合数据特点进行改进。
例如:
《A symbolic representation of time series, with implications for streaming algorithms》 -
闫秋燕等提出了一种基于关键点的SAX改进算法,该算法选取序列中满足一定筛选条件的极值点作为关键点来对时间序列进行分段【就是分段+SAX结合被】,很好地保留了序列的形态特征。
例如:
《一种基于关键点的SAX改进算法》 -
朱跃龙等通过引入语义相似的概念,基于极值点对时间序列进行划分并赋予语义符号,实现水文时间序列的语义符号化。
例如:
《基于语义相似的水文时间序列相似性挖掘》 -
李迎提出了一种基于DTW的符号化时间序列聚类算法,该算法将DTW距离用于关键点提取后的符号序列间的相似性度量,再利用Normal矩阵和FCM方法进行聚类分析,说明了将DTW距离用于时间序列聚类分析具有较高的准确率。
注意:但是该算法对初始聚类中心敏感,容易产生局部最优解,且无法避免孤点造成的影响。
《一种基于DTW的符号化时间序列聚类算法》
现有的水文时间序列的相似性度量方式主要有欧氏距离、动态模式匹配、FastDTW距离
2.2 本文贡献
在前人研究成果的基础上(《基于语义相似的水文时间序列相似性挖掘》作者:朱跃龙等),本文在其DTW_SS方法的基础上,针对 DTW_SS 方法在挖掘过程中产生的候选集过大(如果查询的原序列比较短,或者是模式很单一的话,比如说{UD}, 那么就有可能出现 候选集过大的问题),导致采用DTW距离进行精确匹配耗时过长的问题。
- 本文提出的方法:
DTW_CSW方法
① 采用凝聚层次聚类方法,对语义划分后的子序列做聚类分析并符号化;
② 根据符号化结果在历史数据中获取与查询符号序列编辑距离最小的候选集;
③ 最后在候选集中进行DTW距离精确匹配以获取相似时间子序列,从而提高查询效率。
3 时间序列语义相似与聚类
3.1 时间序列的语义是什么
时间序列语义化是对水文时间序列进行离散化,将所得子序列看作一系列的符号,并对每个符号进行语义解释。

3.2 层次聚类
-
层次聚类方法将数据对象 聚集成聚类树,通常分为凝聚和分裂两种层次聚类方法。
-
凝聚层次聚类 :是一种自底向上的策略,首先将每个对象看作一个类,然后根据不同的类间距离度量准则合并初始类,直至满足终止条件。
分裂层次聚类 :是一种自顶向下的策略,先是将所有对象看作一个类,然后再不断分解,直到满足终止条件。
- 本文采用的是凝聚层次聚类,无需事先确定聚类中心,且在结果生成后,可以剔除数据中的孤点,能达到更好的聚类效果。
3.3 算法步骤
本文采用DTW距离,作为时间子序列间的相似性度量;
通过凝聚层次聚类法,对单一语义的子序列进行聚类,距离算法步骤如下:
输入:时间序列子序列集合(通过极值点分段后的,一段一段右符号表示出来的序列 的集合)
输出:N类语义相同的子序列们
步骤一:初始化。
把每个子序列归为一类,计算两两之间的DTW距离作为类间距离;
步骤二:合并
寻找各个类之间,距离最近的两个类,然后合并他们。
步骤三:重新计算类间距离。

步骤四:重复步骤二和步骤三,直到满足终止条件(终止条件应该是 找到N个类??)
- 然后就是需要确定聚类中心

4 基于DTW聚类的相似性挖掘
此方法分为两个阶段:准备阶段和查询阶段。
4.1 相似性挖掘准备阶段

4.2 相似性挖掘查询阶段
- 这一段我笑拉了,这也太搞笑了…
- 为啥等长?等长用啥DTW,直接欧式距离上啊!
- 防止候选集太大然后DTW计算复杂度太高,你做候选集全用DTW,怎么了、是生成候选集的时间复杂度不计算在内吗??

- 历史序列X
- 查询序列Q
4.3 数据预处理介绍
-
数据填补
用前后的均值来代替缺失值 -
数据平滑
时间序列的整体波动趋势,是水文时间序列数据中最受关注的部分。
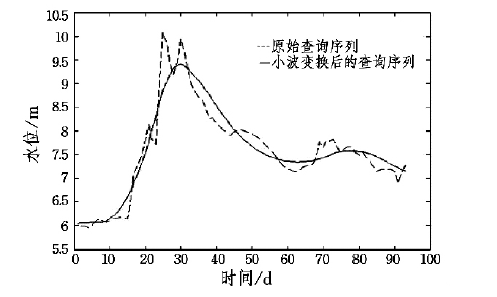
有研究表明,小波变换能够在很好地保持序列真题变化趋势的情况下最大限度地去除噪声,适用于水文时间序列平滑处理。
《基于语义相似的水文时间序列相似性挖掘》
《水文时间序列模式挖掘》
如下图所示,小波变换对于时间序列的平滑效果。
4.4 特征点的选择
特征点。特征点是指水文时间序列中,对序列整体形态和整体趋势变化影响较大的数据点。
基于特征点的分段表示法——能够在不破话序列语义的基础上,实现有效的时间序列降维,提高查询速度。

4.5 时间序列符号化
时间序列符号化,是将 时间序列 转换为 符号序列 的过程。
符号序列的每一个符号,都表示一段子序列。(因为是用上升、平稳、下降 三个符号 UDB 来表示的嘛!)
4.6 符号序列度量
- 两个符号序列通过插入、删除和替换符号,达到完全一致的最小编辑次数。

4.7 小结一下
- 说白了,就是在人家朱跃龙(作者)的基础上,在得到符号序列之后,多做了一步聚类分析。【其实真的没必要,因为做聚类分析也是在用DTW去计算距离,通过这个方法缩小候选集,前后时间还可能对掉了…。。。。结果就是又麻烦,又没有效率】
5 实验对比与分析
数据:滁河六合站的日平均水位
方法:在DTW_SS的基础上,采用基于DTW距离的凝聚层次聚类方法,对符号化后的子序列做聚类,达到缩小候选集的目的。
5.1 实验步骤

注意:表1 说明了两种方法的符号序列,以及阈值的选取。
5.2 时间消耗对比结果
- 我还是那句话,没有计算“构建候选集”的时间复杂度,这个结果毫无参考价值好嘛。。。
- 只计算【查询阶段】的时间复杂度,而不计算【数据准备】阶段的时间复杂度???
- (如果我哪里是没有理解到位,也可以指出来,不过先喷再说,如果人家的过程正确,欢迎私信或者评论,反正我先喷再说。。。)

5.3 准确性分析
- 我真的笑不活了,准确性是这么判断的吗?你在别人的实验基础上,加了一点杂七杂八的东西进去,然后选三个最相似的,结果中了两个相同的,就说自己的方法是有效的?是准确的?我2022年看这个论文真觉得看不懂了
6 总结
终于到了总结部分,这文章看的我真的是很火大。
把方法改的乱七八糟,然后结果准确率的衡量指标又十分主观,方法“改进了”,但是在对比时间复杂度的时候也并没有计算到【准备阶段】的时间复杂度,说白了就是把人家在后面要做的比较,放在前面做完了,然后就说自己的效率比别人高??
学术?道德?底线?
我真的火力全开在喷。。。
- 哎受不了了,下一篇下一篇!