1 摘要
一种基于变量相关性的多元时间序列相似性搜索方法。
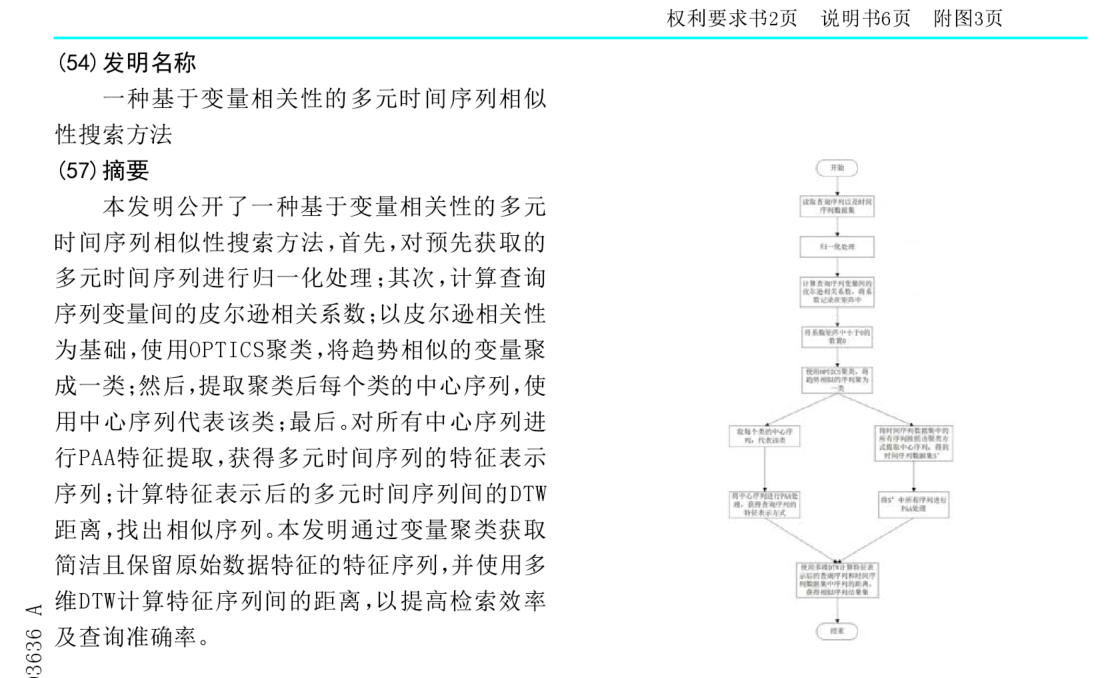
步骤一:对多元时间序列进行归一化处理
步骤二:计算序列间数据间的皮尔逊相关系数
步骤三:以皮尔逊相关性为基础,使用OPTICS聚类,将趋势相似的变量聚成类
步骤四:提取聚类后每个类的中心序列,用中心序列代表该类
步骤五:最后对所有中心序列进行PAA特征提取,获得多元时间序列的特征表示数列
步骤六:计算特征表示后的多元时间序列间的DTW距离,找出相似序列。
2 介绍——针对多元时间序列相似度量
- 很多一元时间序列相似度量的方法,无法直接用于多元时间序列的研究(如最长公共子序列、编辑距离等等)
- 使用于多元时间序列的相似度量方法(如动态时间弯曲、欧式距离等),往往无法平衡计算效率与查询准确率之间的矛盾
2.1 目前常见的多元时间序列特征提取方法
- 主成分分析(CPCA)
- 多维分段拟合
- 奇异值分解(SVD)
- 特征点提取
3 步骤分析
3.1 归一化
- 具体的说,就是选择两条时间序列(别整什么“多元,俩就是俩”)(这里貌似是有m条时间序列,好的先不管,先用两条去分析)

- 归一化之后,得到的是两条序列,不等长,每个序列的数据值都在[0, 1]
3.2 采用皮尔逊相关系数,算相关性
- “计算所有变量间的相关性” —— 请问变量是指什么?
- 每一个时间点的数据,都是一个变量。
举个例子说,两条序列,序列A有2万个数据(每小时一个水位值),序列B有3万个数据(每小时一个水位值),那么用皮尔逊相关性分析来说,就是一个2万 * 3万的矩阵。矩阵中的每一个值,就是横坐标与纵坐标之间的皮尔孙相关性。

- 那么上图说,“根据变量间的相关性判断两变量是否可以归为一类”, 这一句话是真的读不懂了…怎么能把两个时间序列中某两个点,或者多个点,归为一类呢?