1.朴素贝叶斯对新闻进行分类:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.classification import classification_report
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
def naviebayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
#print(news.data[0])
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
#print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测,使用平滑处理 mlt = MultinomialNB(alpha=1.0)
#print(x_train.toarray())
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
#print("预测的文章类别为:", y_predict)
# 得出准确率
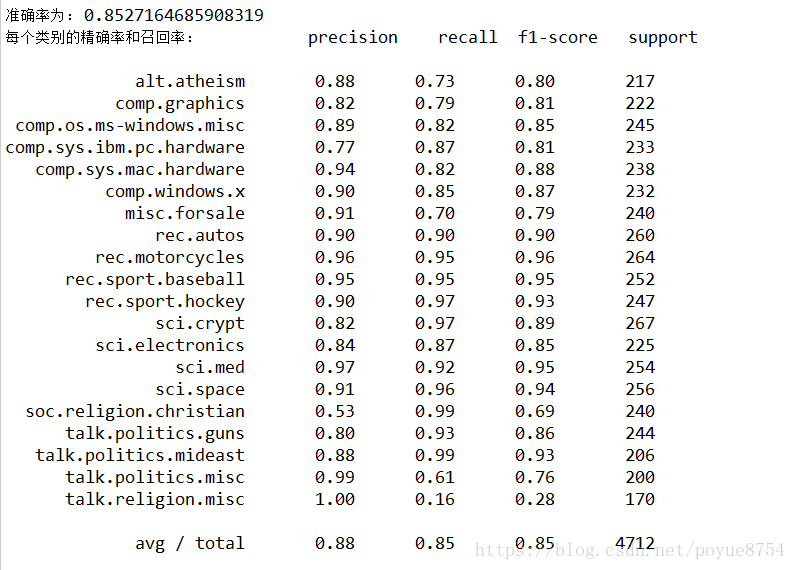
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
return None
if __name__=="__main__":
naviebayes()结果为:
2.拉普拉斯平滑系数:
为了避免训练集样本对一些特征的缺失,即某一些特征出现的次数为0,在计算P(X_1,X_2,X_3,...,X_n)的时候,各个概率相乘最终结果为零,这样就会影响结果。我们需要对这个概率计算公式做一个平滑处理:
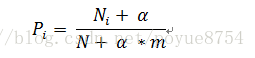
其中m为特征词向量的个数,a为平滑系数,当a=1,称为拉普拉斯平滑。