一,介绍
朴素贝叶斯采用了属性独立的假设条件,这在现实生活中是难以成立的,因而人们尝试对属性条件进行了一定程度放松,假设每个属性最多依赖另一个属性,产生了一类称为半朴素贝叶斯的学习方法:
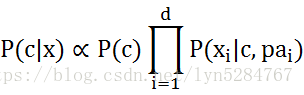
半朴素贝叶斯的基本思路是适当考虑一部分依赖性强的属性。最常用的策略是“独依赖估计”,认为每个属性最多只依赖一个其他属性。确定属性依赖关系的算法包括:SPODE算法、TAN算法和AODE算法。
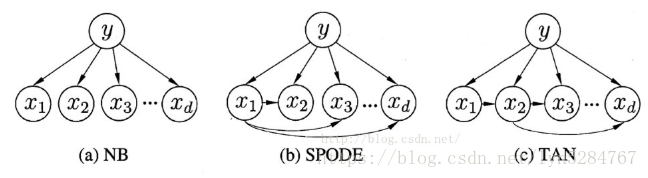
(1)SPODE算法
假设所有属性都依赖同一个属性,这个属性称为“超父”,“超父”属性通过交叉验证等方法确定。
(2)TAN算法
是一种最大带权生成树算法,构建步骤如下:
1.计算两属性之间的互信息
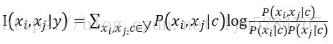
2.以属性为节点构建完全图,任意两节点之间的权重设为I(Xi,Xj|y)
3.构建完全图的最大带权生成树,挑选跟变量,将边设置为有向
4.加入类别节点有y,增加从y到每个属性的有向边
(3)AODE算法
尝试将每个属性作为超父来构建SPODE,然后将SPODE集成起来作为最终结果
朴素贝叶斯(NB)、SPODE、TAN属性依赖关系如下:
二,代码实现
训练数据
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是 5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,,是 6,青绿,稍蜷,浊响,清晰,稍凹,软粘,是 7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是 9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否 10,青绿,硬挺,清脆,清晰,平坦,软粘,否 11,浅白,硬挺,清脆,模糊,平坦,硬滑,否 14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否 15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,否 16,浅白,蜷缩,浊响,模糊,平坦,硬滑,否
测试数据
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是 4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是 8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是 12,浅白,蜷缩,浊响,模糊,平坦,软粘,否 13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否 17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
import math
import numpy as np
import random
# 加载数据
def loadData(filename):
dataSet = []
fr = open(filename,encoding='utf-8')
for line in fr.readlines():
lineArr = line.strip().split(',')
dataSet.append(lineArr)
labels = ['编号','色泽','根蒂','敲声','纹理','头部','触感']
return dataSet,labels
# SPODE算法
def SPODE(dataSet,labels,testData):
index = CrossValidation(dataSet, labels,testData) # 交叉验证获取超父属性
pn = [3, 3, 3, 3, 3, 2] # 各变量的类型数
tdata = dataSet[random.randint(1,len(dataSet)-1)]
px = np.zeros((2, 1))
pclass = 0 # 为正类的概率
nclass = 0 # 为负类的概率
pc = np.zeros((2, 1));tempdata = []
for data in dataSet: # 遍历训练数据,筛选出满足依赖属性的数据
if (data[-1] == '是' and data[index] == tdata[index]): # 刷选出满足依赖属性的数据
pc[0] += 1;tempdata.append(data)
if (data[-1] == '否' and data[index] == tdata[index]):
pc[1] += 1; tempdata.append(data)
for j in range(1, len(labels)):
if (index != j):
for data in tempdata: # 遍历训练数据,筛选出符合条件数据
if (data[-1] == '是' and data[index] == tdata[index] and data[j] == tdata[j]): # 刷选出满足依赖属性的数据
px[0] += 1
if (data[-1] == '否' and data[index] == tdata[index] and data[j] == tdata[j]):
px[1] += 1
pclass += np.log((px[0] + 1) / (pc[0] + pn[j - 1]))
nclass += np.log((px[1] + 1) / (pc[1] + pn[j - 1]))
good = ((pc[0] + 1) / (pc[0] + pc[1] + 2)) * pclass
bad = ((pc[1] + 1) / (pc[0] + pc[1] + 2)) * nclass
print(tdata)
if (good >= bad):
print(pclass,nclass,'是')
else:
print(pclass, nclass, '否')
# TAN算法
def TAN(dataSet,labels,testData):
tdata = testData[random.randint(1, len(testData)-1)]
goodlist, badlist = CalcI(dataSet,labels,tdata)
OrientedGraph(goodlist, badlist,tdata)
def OrientedGraph(goodlist, badlist,tData):
max = 0.0
pclass = 0 # 为正类的概率
nclass = 0 # 为负类的概率
pc = np.zeros((2, 1))
tmp = []
for data in dataSet: # 遍历训练数据,筛选出满足依赖属性的数据
if (data[-1] == '是'): # 刷选出满足依赖属性的数据
pc[0] += 1
if (data[-1] == '否'):
pc[1] += 1
for i in range(1,len(tData)-1):
for data in goodlist:
if(data[0] == tData[i] or data[1]==tData[i]):
if(data[2]>max): # 最强相关属性
max = data[2]
tmp = data
goodlist.remove(tmp) # 找到最强相关属性后移出
pclass +=max;max=0.0
for data in badlist:
if(data[0] == tData[i] or data[1]==tData[i]):
if(data[2]>max):
max = data[2] # 最强相关属性
tmp = data
badlist.remove(tmp) # 找到最强相关属性后移出
nclass += max; max = 0.0
good = ((pc[0] + 1) / (pc[0] + pc[1] + 2)) * pclass
bad = ((pc[1] + 1) / (pc[0] + pc[1] + 2)) * nclass
print(tData)
if (good >= bad):
print(pclass, nclass, '是')
else:
print(pclass, nclass, '否')
# 计算属性之间的互信息
def CalcI(dataSet,labels,tdata):
pn = [3, 3, 3, 3, 3, 2] # 各变量的类型数
goodlist = []
badlist = []
pc = np.zeros((2, 1))
for data in dataSet: # 遍历训练数据,筛选出满足依赖属性的数据
if (data[-1] == '是'): # 训练数据分类
pc[0] += 1
if (data[-1] == '否'):
pc[1] += 1
for i in range(1, len(labels)):
for j in range(i + 1, len(labels)):
tmpglist = [];tmpblist = []
pijx = np.zeros((2, 1));pix = np.zeros((2, 1));pjx = np.zeros((2, 1));pijc = np.zeros((2, 1));pic = np.zeros((2, 1));pjc = np.zeros((2, 1));Iijy = np.zeros((2, 1))
for data in dataSet:
if (data[i] == tdata[i] and data[j] == tdata[j] and data[-1] == '是'): # 计算P(Xi,Xj|C)分母
pijx[0] += 1
if (data[i] == tdata[i] and data[j] == tdata[j] and data[-1] == '否'):
pijx[1] += 1
if (data[i] == tdata[i] and data[-1] == '是'): # 计算P(Xi|C)分母
pix[0] += 1
if (data[i] == tdata[i] and data[-1] == '否'):
pix[1] += 1
if (data[j] == tdata[j] and data[-1] == '是'): # 计算P(Xj|C)分母
pjx[0] += 1
if (data[j] == tdata[j] and data[-1] == '否'):
pjx[1] += 1
pijc[0] = (pijx[0] + 1) / (pc[0] + pn[i - 1]) # 计算P(Xi,Xj|C)
pijc[1] = (pijx[1] + 1) / (pc[1] + pn[i - 1])
pic[0] = (pix[0] + 1) / (pc[0] + pn[i - 1]) # 计算计算P(Xi|C)
pic[1] = (pix[1] + 1) / (pc[1] + pn[i - 1])
pjc[0] = (pjx[0] + 1) / (pc[0] + pn[i - 1]) # 计算计算P(Xj|C)
pjc[1] = (pjx[1] + 1) / (pc[1] + pn[i - 1])
Iijy[0] = pijc[0] * np.log(pijc[0] / (pic[0] * pjc[0])) # 计算属性之间的互信息
Iijy[1] = pijc[1] * np.log(pijc[1] / (pic[1] * pjc[1]))
tmpglist.append(tdata[i]);tmpglist.append(tdata[j]);tmpglist.append(Iijy[0])
goodlist.append(tmpglist)
tmpblist.append(tdata[i]);tmpblist.append(tdata[j]);tmpblist.append(Iijy[1])
badlist.append(tmpblist)
return goodlist, badlist
# 交叉验证选择最优属性
def CrossValidation(dataSet,labels,testData):
pn = [3, 3, 3, 3, 3, 2] # 各变量的类型数
maxcorrect = 0
index = 0
for i in range(1,len(labels)): # 遍历所有属性,选择第i个属性作为超父
correct = 0
pc = np.zeros((2, 1))
tempdata = []
for tdata in testData: # 遍历测试数据
for data in dataSet: # 遍历训练数据,筛选出满足依赖属性的数据
if (data[-1] == '是' and data[i] == tdata[i]): # 刷选出满足依赖属性的数据
pc[0] += 1;tempdata.append(data)
if (data[-1] == '否' and data[i] == tdata[i]):
pc[1] += 1;tempdata.append(data)
for j in range(1,len(labels)):
px = np.zeros((2, 1))
pclass = 0 # 为正类的概率
nclass = 0 # 为负类的概率
if (i != j):
for data in tempdata: # 遍历训练数据,筛选出符合条件数据
if (data[-1] == '是' and data[i] == tdata[i] and data[j]==tdata[j] ): # 刷选出满足依赖属性的数据
px[0] += 1
if (data[-1] == '否' and data[i] == tdata[i] and data[j]==tdata[j] ):
px[1] += 1
pclass += np.log((px[0] + 1) / (pc[0] + pn[j - 1]))
nclass += np.log((px[1] + 1) / (pc[1] + pn[j - 1]))
if ((pclass >= nclass and tdata[-1]=='是') or (pclass < nclass and tdata[-1]=='否')): # 正确的分类
correct+=1
if(correct>maxcorrect): # 正确分类最多的属性作为”超父“
maxcorrect = correct
index= i
return index
if __name__ == '__main__':
dataSet,labels=loadData('watermelon1.txt')
testData,tlabel = loadData('testData.txt')
SPODE(dataSet,labels,testData)
TAN(dataSet,labels,testData)