前面的笔记中我们讨论了线性回归和softmax分类,都可以看作是一层的全连接层,其中线性回归的输出是一个神经元,softmax的输出是多个神经元,softmax主要作用在损失函数的计算部分,相应地模型也需要学习到更多的权重。今天我们来看一下感知机(perceptron)以及感知机的进化版本,多层感知机(MLP)。
开始之前给大家安利一下我之前写的使用tensorflow2构建物体分类模型的博客,我在博客中详细介绍了数据集收集、模型构建和模型使用三个方面,结合视频你也可以快速构建自己的物体分类模型,快去试试吧!
手把手教你用tensorflow2.3训练自己的分类数据集_dejahu的博客-CSDN博客
感知机
感知机的基本概念
感知机主要是为了解决二分类的问题,给定输入x,权重w和偏移b,感知通过激活函数可以得到一个二分类的输出
o = σ ( < w , x > + b ) o = \sigma(<w,x> + b) o=σ(<w,x>+b)
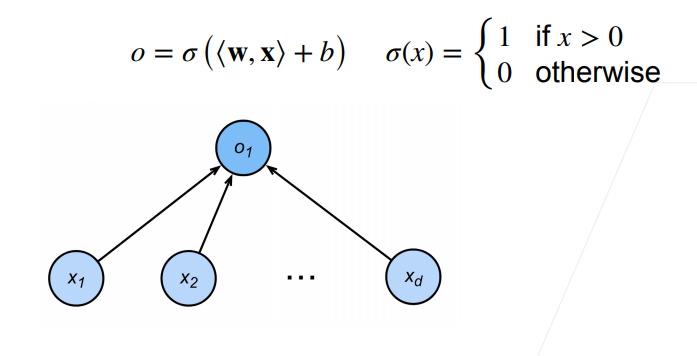
感知机和之前的线性回归和softmax比较相似,都是这种一层的全连接网络,不同的是线性回归通过回归输出实数,softmax则通过回归输出概率,感知机是通过激活函数来输出01的二进制数。
感知机是在19实际60年代提出的,当时的设备比较简陋,不像现在动辄就1tb、2tb的数据,那时构建的感知机真的是一个机器,如下图所示,我们在示意图中看到的权重是真的一根根的导线。

感知机的训练过程
感知机的训练过程也比较简单,使用的是batch为1的随机梯度下降,当分类出现错误的时候,模型使用梯度下降来更新权重参数,具体过程如下所示:

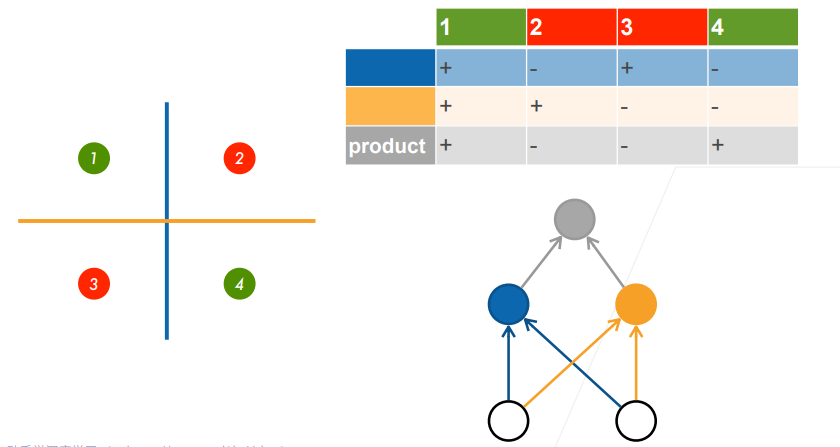
但是感知机存在一个致命的缺陷是感知机不能拟合XOR函数,只能产生线性的分割面,这也导致了第一个AI寒冬。在很长的一段时间感知机这个东西都没有再被研究。
多层感知机(MLP)
MLP的基本概念
出现问题不可怕,出现问题就意味着可以去解决问题。大家也可以看到初代的感知机结构比较简单,只有一个输出的神经元,有的时候研究和生活很像,比如我们遇到难题的时候,可以将难题拆分为细小的问题来解决,逐步击破。这里同样也是,一开始的感知机只有一层,那就把感知机的层数增加,这样XOR的问题就拆分成了两步来做,整个问题就变成了下面这种形式。
加一层是可以的,那么举一反三,加多层也是可以的,所以除去问题的输入输出,中间的层我们给他一个新的名字,隐藏层(hidden layer),隐藏层的大小是超参数,和学习率,batchsize这些一样,示意图如下:
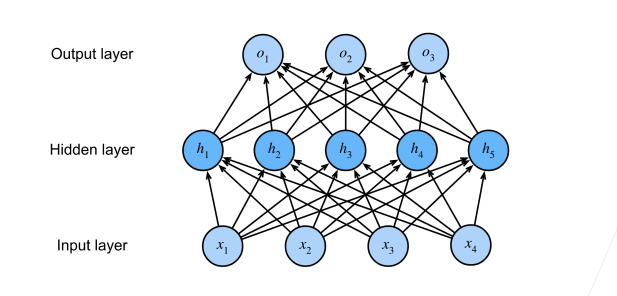
如果只是做wx+b这种操作那么整个模型就还是线性的,在面对很多非线性的问题上还是比较棘手,为了能够解决这个问题,我们需要在线性操作之后添加激活函数使得网络具有非线性学习的能力,之后也是通过梯度下降来学习模型的权重参数。
激活函数
MLP是深度卷积神经网络的雏形,后面通过添加卷积和池化出来了卷积神经网络,所以理解MLP的基本原理对后面理解CNN有很大的帮助。在之前的博客中也有提到,神经网络参数众多,主要是通过梯度下降来学习权重参数,梯度的求解非常重要,并且由于链式法则的存在,有的时候可能会一石激起千层浪,导致梯度消失或者梯度爆炸的情况出现,所以一个好的激活函数在参数学习中起到了重要的作用,下面是几个常用的激活函数。
-
Sigmoid激活函数
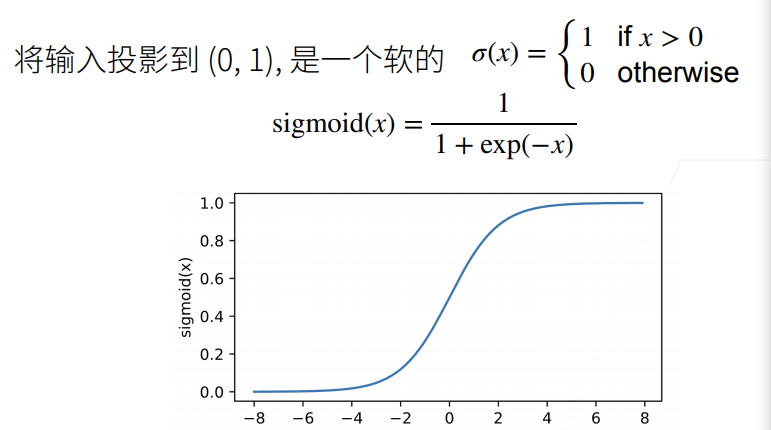
-
ReLU激活函数
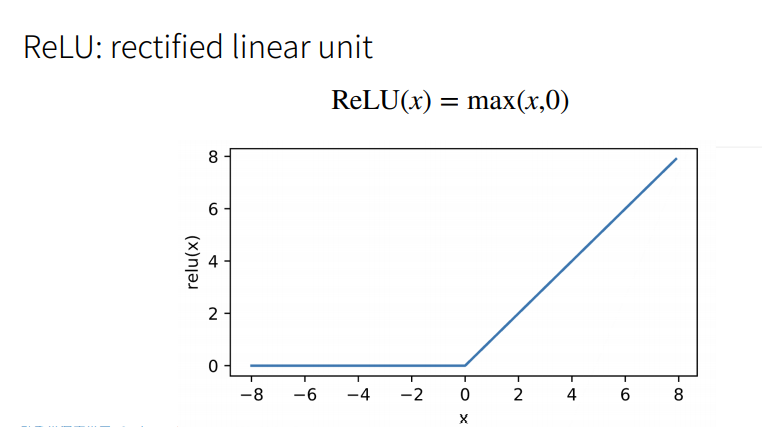
-
Tanh激活函数
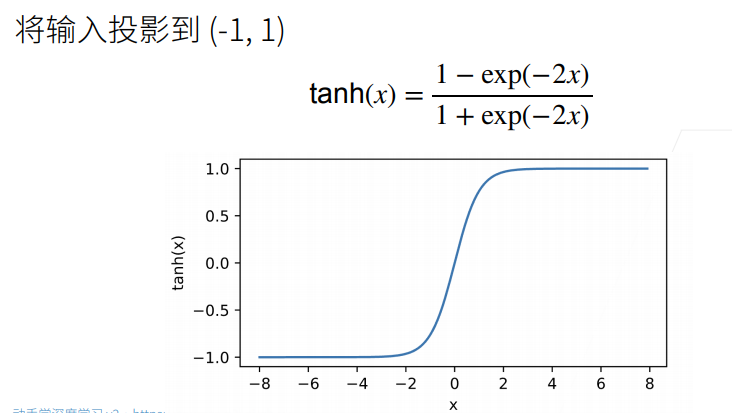
注意Relu是个很好的激活函数,但是在转折点那块是不可导的,所以后面就有个ReLU的soft版本。
Pytorch代码实现
Pytorch可以方便的实现MLP,这个时候我们依然还没有进入到卷积神经网络的内容中,代码主要通过Sequential来进行构建,首先是将图片数据拉平,之后送到全连接层中,中间添加relu激活函数,详细代码如下:
import torch
from torch import nn
from d2l import torch as d2l
# 隐藏层 包含256个隐藏单元并使用了ReLU激活函数
# 注:最后一层使用softmax的话是在损失函数里面,而不是在模型里面
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
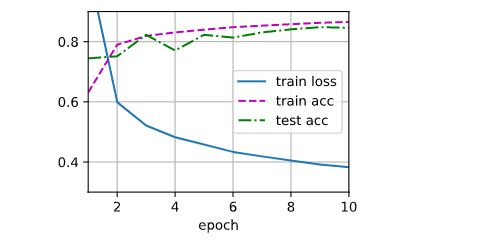
结果如下: