采用ndarray和autograd实现线性回归
虽然现在有很多深度学习框架,但它们大多继承了所有的回归/分类任务,我们也只能使用它,无法了解其原理,所以,本文只用ndarray和autograd从0开始实现一个简单的线性回归。
对于学习机器学习或深度学习的开发者来说,线性回归是最基础最入门的一课内容,本文重点将介绍放在代码部分,原理部分需查阅其余文献。一般地,线性回归的方程可写成:
其中,
为集合点,
为权重矩阵,
为偏置量。求线性回归其实就是求
和
的值。并且还要最小化集合点上的平方误差:
其中,
为实际值,
为预测值。
线性回归模型训练:
1、要训练一个线性回归,首先需要有一个数据集,这里我们可以自定义一个数据集:
具体采用此方法来产生一个带有噪声的一系列数据点:
上式中,
有两个维度,
表示第
个样本,2和-3.4为权重,4.2表示偏置量
,
表示噪声,服从均值为0方差为1的正太分布。
true_w=[2,-3.4]
true_b=4.2
x=nd.random_normal(shape=(num_example,num_input)) # 随机生成的数据点x(1000行2列)
y=true_w[0]*x[:,0]+true_w[1]*x[:,1]+true_b
noise=0.01*nd.random_normal(shape=y.shape) # 按照公式写出代码
y=y+noise
# print(y.shape)
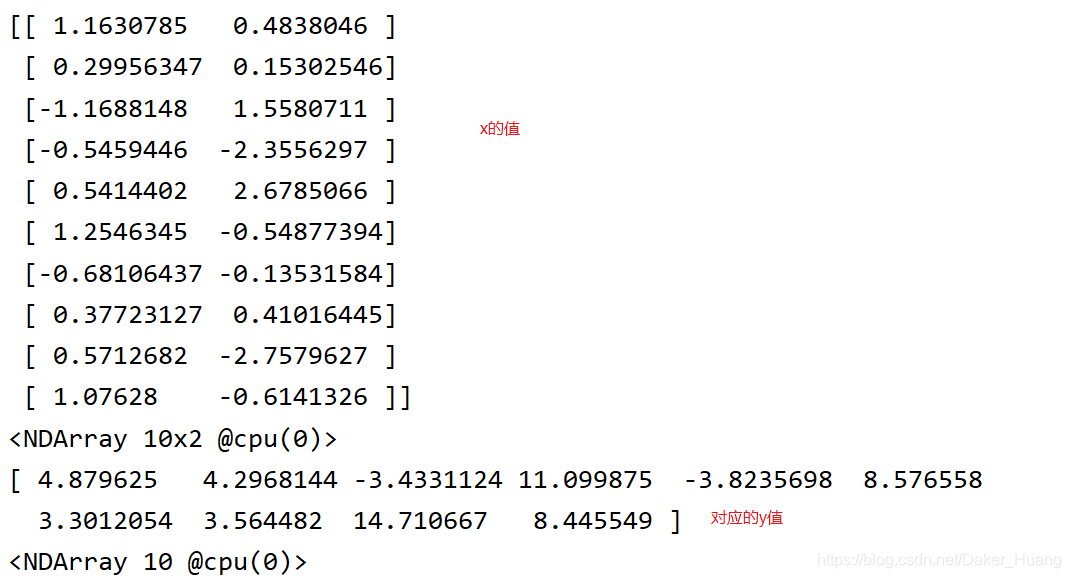
print(x[:10],y[:10]) # 打印前10组数据进行查看
运行结果:
2、数据读取
batch_size=10
def data_iter():
idx=list(range(num_example)) # 产生索引
random.shuffle(idx) # 打乱数据
for i in range(0,num_example,batch_size):
j=nd.array(idx[i:min(i+batch_size,num_example)])
yield nd.take(x,j),nd.take(y,j) # nd.take(x,j),从数据中取出相关索引的数据,并返回
那么现在我们读取第一个随机数据块看看:
for data,label in data_iter(): # 读取第一个batch size看看
print("batch size:",data,label)
break
运行结果:

因为我们有1000个样本,那么我们多少次取完?
n=0
for data,label in data_iter(): # 读取第一个batch size看看
n+=1
print(n)
运行结果:
正好100次取完(1000/10)。
3、初始化模型参数
设置完数据样本之后,就能开始定义模型,训练参数了。首先我们定义模型参数:
# 初始化模型参数
w=nd.random_normal(shape=(num_input,1))
b=nd.zeros(1,)
params=[w,b]
# 之后会不断训练更新w和b的值,所以我们要创建梯度来进行求导
for param in params: # 对w和b开辟一个临时空间
params.attach_grad()
4、定义网络
根据公式:
可得:
def net(X): # 根据公式:f(x)=xw+b
return nd.dot(X,w)+b
5、定义损失函数
def loss_function(y_true,y_pre): # 常使用平方误差来衡量预测值和真实值之间的差距
return (y_pre-y_true.reshape(y_pre.shape))**2 # 把真实值与预测值的维度变成一样,否则会广播
6、梯度优化器
def SGD(params,lr):
for pa in params:
pa[:]=pa-lr*pa.grad # 参数沿着梯度的反方向走特定距离
7、训练模型
epochs=5
lr=0.001
for e in range(0,epochs):
total_loss=0
for data, label in data_iter(): # 读取第一个batch size看看
with ag.record():
output=net(data)
loss=loss_function(label,output)
loss.backward() # 对loss求导
SGD(params,lr) # 沿着导数的反方向走是可以把loss变低的
total_loss+=nd.sum(loss).asscalar()
print("Epoch: %d,average loss: %f"%(e,total_loss/num_example))
运行结果:

最后我们打印w,b查看一下更新结果:
print(w,b)
运行结果:

可以看到,w非常接近[2,-3.4],b非常接近4.2,可以说非常准了,模型效果也非常好。
至此,一个完整的线性回归模型就训练完成啦!
附上所有源码:
import mxnet.ndarray as nd
import mxnet.autograd as ag
import random
num_input=2
num_example=1000
'''---生成数据---'''
true_w=[2,-3.4]
true_b=4.2
x=nd.random_normal(shape=(num_example,num_input)) # 随机生成的数据点x(1000行2列)
y=true_w[0]*x[:,0]+true_w[1]*x[:,1]+true_b
noise=0.01*nd.random_normal(shape=y.shape) # 按照公式写出代码
y=y+noise
# print(y.shape)
print(x[:10],y[:10]) # 打印前10组数据进行查看
'''---数据读取---'''
# 定义一个函数让它每批次读取数据(batch_size)
batch_size=10
def data_iter():
idx=list(range(num_example)) # 产生索引
random.shuffle(idx) # 打乱数据
for i in range(0,num_example,batch_size):
j=nd.array(idx[i:min(i+batch_size,num_example)])
yield nd.take(x,j),nd.take(y,j) # nd.take(x,j),从数据中取出相关索引的数据,并返回
for data,label in data_iter(): # 读取第一个batch size看看
print("batch size:",data,label)
break
'''---取多少次样本?---'''
# n=0
# for data,label in data_iter(): # 读取第一个batch size看看
# n+=1
# print(n)
'''--------------------定义模型---------------------'''
# 初始化模型参数
w=nd.random_normal(shape=(num_input,1))
b=nd.zeros(1,)
params=[w,b]
# 之后会不断训练更新w和b的值,所以我们要创建梯度来进行求导
for param in params: # 对w和b开辟一个临时空间
param.attach_grad()
# 网络定义
def net(X): # 根据公式:f(x)=xw+b
return nd.dot(X,w)+b
# 损失函数定义
def loss_function(y_true,y_pre): # 常使用平方误差来衡量预测值和真实值之间的差距
return (y_pre-y_true.reshape(y_pre.shape))**2 # 把真实值与预测值的维度变成一样,否则会广播
# 优化
def SGD(params,lr):
for pa in params:
pa[:]=pa-lr*pa.grad # 参数沿着梯度的反方向走特定距离
'''-----训练-----'''
epochs=5
lr=0.001
for e in range(0,epochs):
total_loss=0
for data, label in data_iter(): # 读取第一个batch size看看
with ag.record():
output=net(data)
loss=loss_function(label,output)
loss.backward() # 对loss求导
SGD(params,lr) # 沿着导数的反方向走是可以把loss变低的
total_loss+=nd.sum(loss).asscalar()
print("Epoch: %d,average loss: %f"%(e,total_loss/num_example))
print(w,b)
