最近在看李沐老师的动手学深度学习教程,强烈安利大家去看,讲的非常通透,他会从一个常人的角度给你分析深度学习的原理,另外最近老师录制的视频是Pytorch版本的,在学习基本原理的同时还是学习到Pytorch的使用,真的是太棒了!
这期专栏我就按照我自己的理解把其中一些重点的知识做个记录,方便自己回顾,另外也会附上Python的代码,结合代码一块理解原理。
深度学习的历史
深度学习这个概念在上个世纪50年代那会就已经有了,一开始有人提出了感知机的模型,可以说是现在深度学习网络的一个雏形了,但是当时的MLP解决不了XOR的问题,就导致了第一次的AI寒冬,后面又有人提出了多层感知机解决了这个问题,并在这个基础上衍生出一系列的算法和模型,不过受限于当时计算资源的影响以及诸如卷积神经网络这些模型不具有解释性,不像svm有着很好的数学性质,在很长一段时间中,大家更喜欢研究svm而不是这些神经网络,甚至我在2016年,也是大一的时候,大家还都在研究svm,这里要吐槽一个百度,百度很多教程都比较老,大家看的时候其实有些算法和框架都过时了,但是由于那些教程的点击量比较高所以长期在搜索结果前列,导致了一个恶行循环,所以还是推荐大家通过论文啥的来关注一下你的研究领域的最新进展。
AI从低到高可以分为规划、知识、感知和地图,比较重要的应用有自然语言处理和计算机视觉,尤其是计算机视觉,比如图像分类、物体检测与分割、风格迁移、人脸合成、文字生成图片、文字生成,还有最近很火的换脸应用。我好像在b站上见过几个UP主,就是专门利用图像修复技术来修复老照片,老的视频这些。
数据操作-数组
数组的维度
数组是由维度的,可以分为下面几种:
- 0-d 标量
- 1-d vector 向量
- 2-d matrix 矩阵
- 3-d 图片,3个通道构成的彩色图片
- 4-d 图片的批量,在上面的基础上添加了batch_size
- 5-d 视频的批量,在视频的基础上添加了batch_size
数组的索引
比如这里的例子是对一个矩阵进行索引,第一个位置对应的是行,第二个位置对应的是列
matrix[行索引:列索引]
其中索引依次是start: stop :step
一些代码
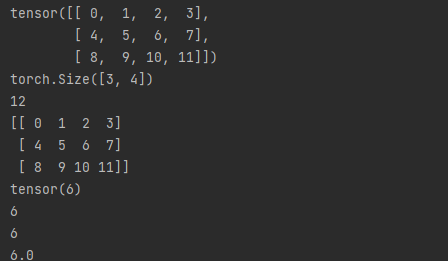
查看torch中张量的基本信息
import torch
x = torch.arange(12) # 产生一个张量
x = x.reshape(-1, 4) # 改变数组的形状
print(x) # 输出x
print(x.shape) # 输出x的形状
print(x.numel()) # 输出x的元素数量
print(x.numpy()) # 将张量转化为numpy
# 将一个标量形式的张量转化为张量,也就是0维的张量数据,这个在计算loss的时候会使用到
a = torch.tensor(6)
print(a)
print(a.item())
print(int(a))
print(float(a))
对两个张量进行合并

# 张量之间的合并
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
result_0, result_1 = torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
print(X.shape)
print(Y.shape)
print(result_0.shape)
print(result_1.shape)
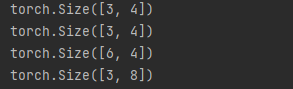
一个比较有意思的现象是,当对两个张量进行合并的时候,这里的dim表示的就是合并的方向,如果dim为0则表示按照行的方向对张量进行合并,也就是3+3,新合成的向量结果是[6,4],如果是dim=1则结果是[3, 8]
注:在学习Pyorch的同时,matplotlib和pandas也是需要掌握的两个库,这个在pytorch学习之后需要补充一下这部分的知识。
线性代数
线性代数是卷积神经网络的基础,不过在pytorch的实际使用的时候涉及的不是很多,所以这里我就记录一些重点的概念。
需要了解的概念
-
哈达玛乘积
两个矩阵按元素乘法成为哈达玛积,数学符号是圈点。两个张量直接相乘,那就是哈达玛乘积。
-
转置矩阵
A_ij = A_ji 元素按照对角线的位置调换一下
-
内积
矩阵乘法,点积。torch中的mv是矩阵和向量乘积,mm是矩阵和矩阵的乘积,比如一个4*3的矩阵和3*4的矩阵相乘可以得到一个4*4的矩阵
-
L2范数
在求解距离的时候常会用到,在权重衰减的时候也会用到,就平方和然后开根号就可以,公式如下:
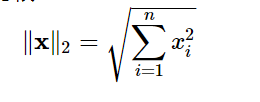
同样还有L1范数,那就是绝对值之和。
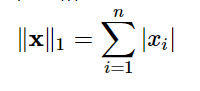
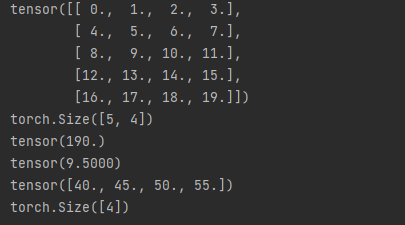
按轴求和
axis是numpy和torch中一个比较神奇的概念,很容易让人搞混,比如一张张量的shape是[2, 5, 6],这个张量其实就有3个轴,如果按照0轴进行求和,得到的新的结果的shape是[5, 6]。同理,如果你按照第1个轴进行求和,得到的新的结果的shape应该是[2, 6]。嗯,大概就是按照哪个轴进行求和,就会把哪个位置给消去。所以,这也会导致一个问题,就是当我们使用到广播机制的时候,应该保持求和之后新数组的维度不变。以下是代码示范。
# 按轴求和
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
print(A.shape)
print(A.sum()) # 求和
print(A.mean()) # 求平均值
A_0 = A.sum(axis=0) # 按行求和
print(A_0)
print(A_0.shape)
链式法则
前面在提到感知机的时候,说到他不能解决xor的问题,后面的解决方案是从单层的感知机变成了多层的感知机,也就是我们不能一口吃成胖子,需要先把大问题拆解为小问题然后一步步得到结果。卷积神经网络大概也是这样,卷积神经网络基于链式法则进行推导,正向传播之后反向传播求解梯度,后面的层就变成了求解梯度的梯度,他们不需要转化为具体的公式,只对具体的值负责,链式法则如下:

在具体实现的时候,首先会将代码分解成操作子,然后将计算表示成一个无环图,显示或者隐式构造。下面是正向和反向的过程。

下期来一起说下线性回归(回归解决的是连续的问题,比如房价的预测)