论文地址
一.网络结构图示例
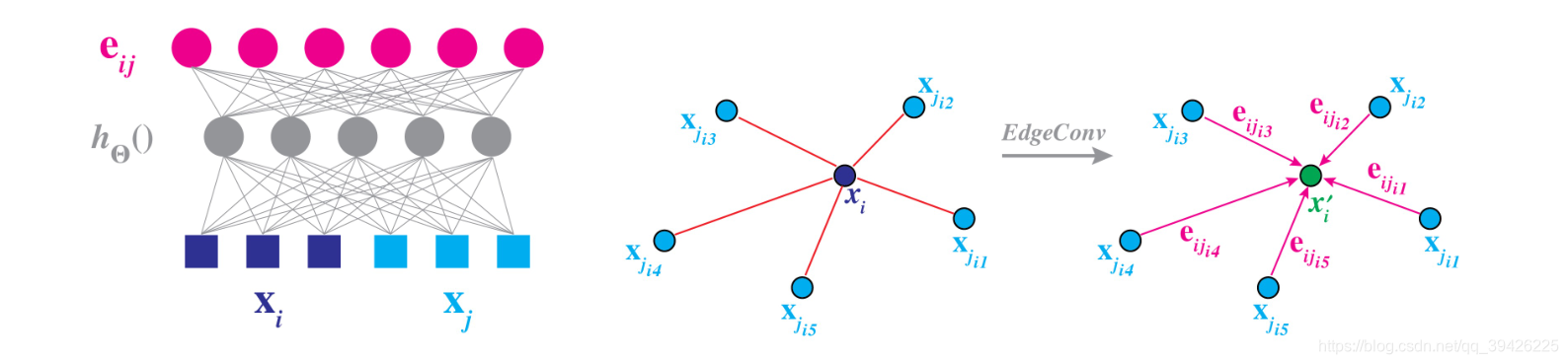
首先,本文开门见山给出网络结构图,以及non-local的思想,简单来说就是相似特征不一定是在local局域内,再来介绍了作者提出的核心方法EdgeConv,下面是EdgeConv的优点:
(1)它整合了当地的邻近点的信息
(2)它通过叠加当前点逐渐学习全局形状属性
(3)在经过多层迭代更好的捕捉到潜在的远距离相似特征
二.Introduction
1.考虑到网格重建和去噪的效率和不稳定性,所以最近的图形和视觉处理方法往往直接处理点云
2. 标准的深度神经网络模型需要具有规则结构的输入数据,点云数据是不规则的,所以使用深度学习模型常见的方法就是将点云数据转换为体积表示即3D网格
3. 本文贡献:
(1)本文提出了一个从点云学习的新操作,EdgeConv,在保持排列不变性的同时,更好地捕捉点云的局部几何特征。
(2)本文证明了该模型可以通过动态更新层与层之间的关系图来学习对点进行语义分组。
(3)本文演示了EdgeConv可以集成到多个现有工作中进行点云处理。
(4)我们对EdgeConv进行了广泛的分析和测试,并展示了我们的最新成果
三.Our Approach
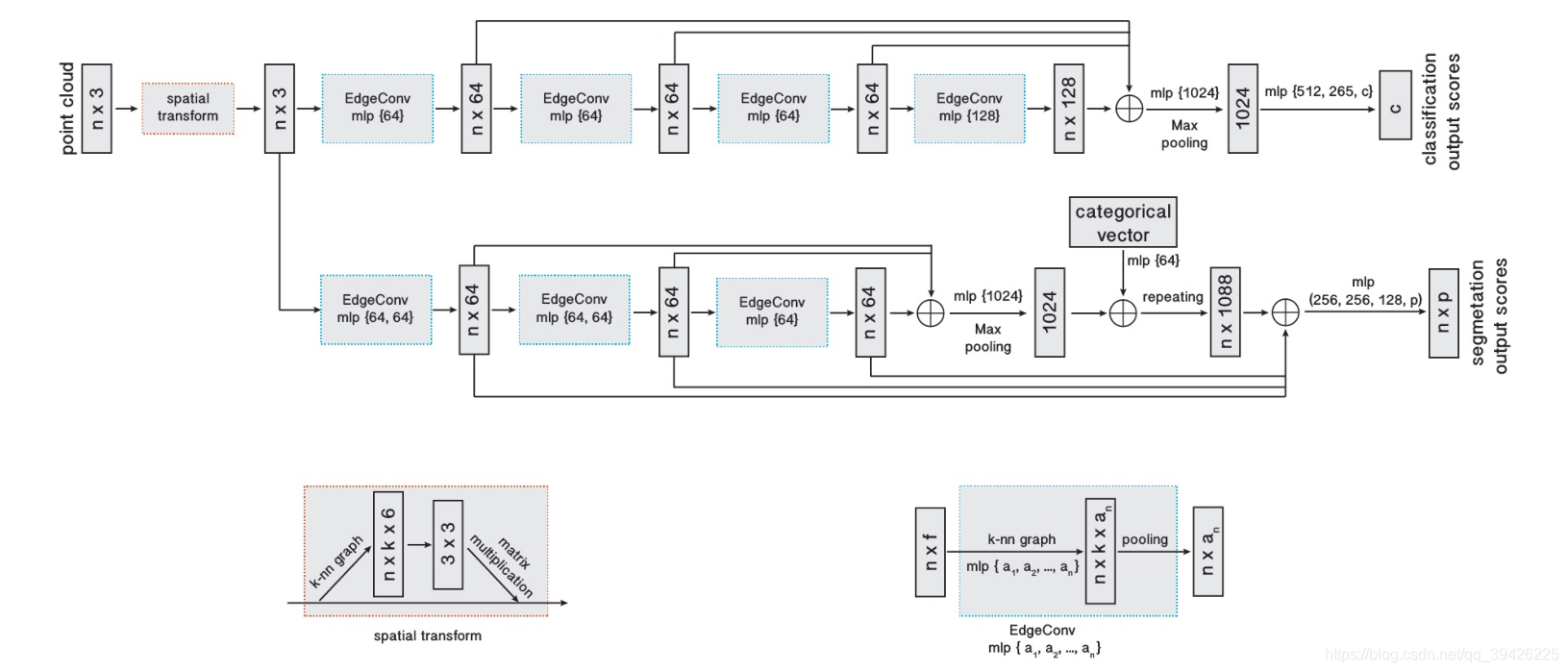
这里给出1个整体网络结构图和2个组件:
1.用于分类(顶部分支)和分割(底部分支)的模型体系结构。
(1)分类模型以n个点作为输入,计算EdgeConv层上每个点的大小为k的边缘特征集,并在每个集合内聚集特征,计算对应点的EdgeConv。最后一个EdgeConv层的输出特性被全局聚合,形成一个一维全局描述符,用于生成c类的分类分数。
(2)分割模型先进行EdgeConv然后通过前几次FeatureMap求和再经过mlp最终通过repeat形成n个全局特征和之前的特征相拼接进行分割
2.空间转换块
本文中通过33仿射矩阵,但代码和文章有所不同
# knn中k=20
k = 20
# 求得k个点的距离矩阵
adj_matrix = tf_util.pairwise_distance(point_cloud)
# 通过knn得到找到k个点
nn_idx = tf_util.knn(adj_matrix, k=k)
# 拿到边缘特征
edge_feature = tf_util.get_edge_feature(point_cloud, nn_idx=nn_idx, k=k)
with tf.variable_scope('transform_net1') as sc:
# 进行空间转换
transform = input_transform_net(edge_feature, is_training, bn_decay, K=3)
def input_transform_net(edge_feature, is_training, bn_decay=None, K=3, is_dist=False):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = edge_feature.get_shape()[0].value
num_point = edge_feature.get_shape()[1].value
# input_image = tf.expand_dims(point_cloud, -1)
net = tf_util.conv2d(edge_feature, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay, is_dist=is_dist)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay, is_dist=is_dist)
net = tf.reduce_max(net, axis=-2, keep_dims=True)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay, is_dist=is_dist)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay,is_dist=is_dist)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay,is_dist=is_dist)
with tf.variable_scope('transform_XYZ') as sc:
# assert(K==3)
with tf.device('/cpu:0'):
weights = tf.get_variable('weights', [256, K*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [K*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant(np.eye(K).flatten(), dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, K, K])
return transform
3.边缘卷积组件:
寻找knn,经过1次CNN和pooling,不断迭代
adj_matrix = tf_util.pairwise_distance(point_cloud_transformed)
nn_idx = tf_util.knn(adj_matrix, k=k)
edge_feature = tf_util.get_edge_feature(point_cloud_transformed, nn_idx=nn_idx, k=k)
net = tf_util.conv2d(edge_feature, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='dgcnn1', bn_decay=bn_decay)
net = tf.reduce_max(net, axis=-2, keep_dims=True)
net1 = net
adj_matrix = tf_util.pairwise_distance(net)
nn_idx = tf_util.knn(adj_matrix, k=k)
edge_feature = tf_util.get_edge_feature(net, nn_idx=nn_idx, k=k)
net = tf_util.conv2d(edge_feature, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='dgcnn2', bn_decay=bn_decay)
net = tf.reduce_max(net, axis=-2, keep_dims=True)
net2 = net
四.Edge Convolution
最后在EdgeConv操作上添加一个通道级的对称聚合操作
,完整公式为:
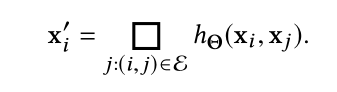
关于公式中的h和
有四种可能的选择:
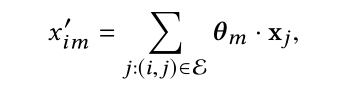
(1)直接使用权值乘以领近点信息求和
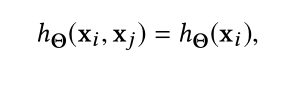
(2)只提取全局形状信息,而忽视了局部领域结构。这类网络实际上就是PointNet,因此PointNet中可以说使用了特殊的EdgeConv模块
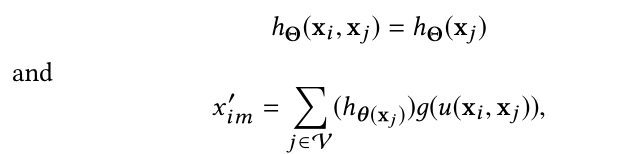
(3)这种方式只对局部信息进行编码,在本质上就是将原始点云看做一系列小块的集合,丢失了原始的全局形状结构信息
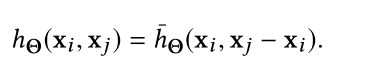
(4)这样的结构同时结合了全局形状信息以及局部领域信息
五.Dynamic graph update
1.置换不变性
通过对称函数max,不管点云输入的顺序如何经过max都为一个点
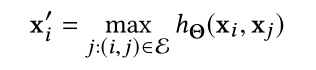
2.平移不变性
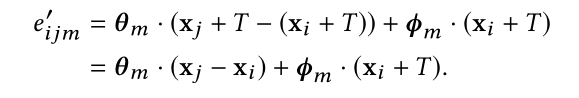
3.现有方法的比较

1.PointNet把每个点进行卷积然后经过pooling
2.PointNet++将邻近点通过CNN,maxpooling聚合
3.MoNet进过计算xi和xj的双向欧氏距离再经过高斯核映射到高维再与xj作哈达玛积再乘以权重进行求和,{w 1 ,… .,w N }编码了可学的高斯均值和方差参数,{θ 1 ,… .,θ M }是可学习的滤波器系数(与卷积核上权重w类似)
Q:哈达玛积
A:

4.PCNN可以看做MoNet的一种特殊情况:g为预定义的高斯核函数
5.DGCNN的优势:
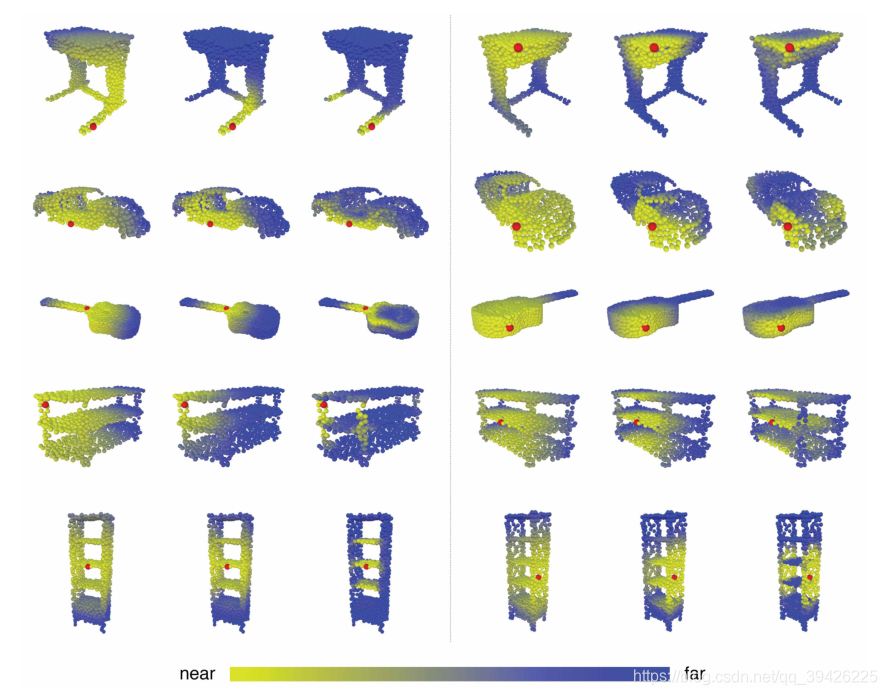
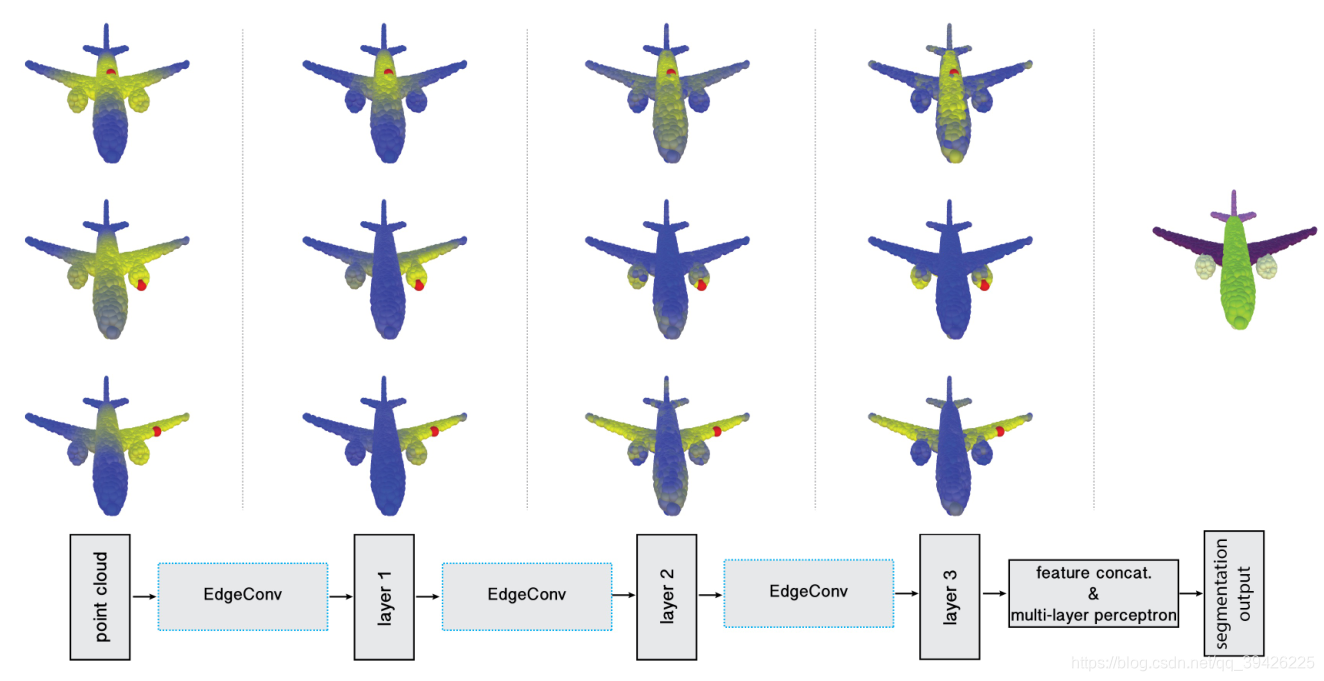
这张图片说明了DGCNN如何拉近原本语义信息相同的点即non-local的实现,本文的模型不仅学习了如何提取局部几何特征,而且还学习了如何在点云中对点进行分组。上图显示了不同特征空间的距离,说明在原始嵌入中,长距离内容携带了相同的语义信息。
六.Experiment
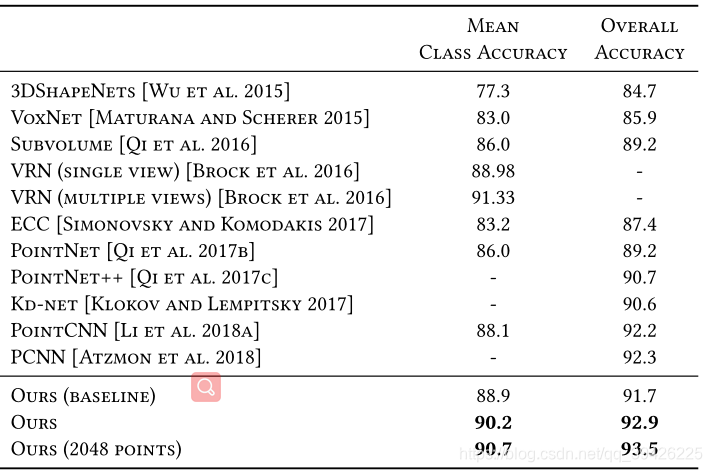
1.分类:
(1)数据集ModelNet-40:数据集包含40个类别的12311个网格化CAD模型。9843个模型用于训练和
2468个模型用于测试。对于每个模型,从网格面采样1024个点;点云被重新调整以适应单位球面。只有(x,y,z)坐标被使用,原始网格被丢弃。在训练过程中,我们通过随机缩放对象和扰动对象和点位置来增加数据