接上篇:【Paper】Deep Multimodal Representation Learning: A Survey (Part2)
文章目录
Deep Multimodal Representation Learning: A Survey
深度多模态表征学习研究综述
E. ATTENTION MECHANISM
Attention mechanism allows a model to focus on specific regions of a feature map or specific time steps of a feature sequence. Via attention mechanism, not only an improved performance can be achieved, but also better interpretability of feature representations can be seen. This mechanism mimics the human ability to extract the most discriminative information for recognition. Rather than using all of the information at once, the attention decision process prefers to concentrate on the part of the scene selectively which is needed [151]. Recently, this method has demonstrated its unique power in improving performance in many applications such as visual classification [152]–[154], neuralmachinetranslation [155], [156],speechrecognition [92], image captioning [13], [91], video description [42], [90], visual question-answering [24], [157], cross-modal retrieval [31], [158], and sentiment analysis [22].
注意力机制允许模型专注于特征图的特定区域或特征序列的特定时间步长。通过注意力机制,不仅可以提高性能,而且可以看到特征表示的更好的可解释性。这种机制模仿了人类提取最有区别的信息进行识别的能力。注意决策过程不是一次使用所有信息,而是选择性地将注意力集中在需要的场景部分[151]。最近,这种方法已经证明了其在许多应用中提高性能的独特能力,例如视觉分类[152]-[154],神经机器翻译[155],[156],语音识别[92],图像字幕[13],[91] ,视频描述[42],[90],视觉问答[24],[157],跨模式检索[31],[158]和情感分析[22]。
According to whether a key is used during selecting part of the features,attention mechanism can be categorized into two groups:key-based attention,and key less attention.Key-based attention used a key to search for salient localized features. Take image caption as an example [13], its typical structure can be illustrated as Fig. 8, where a CNN network encodes the image into a feature set {ai}, and then an RNN network decodes the input into hidden states {ht}. In time step t, the output yt is predicted based on htand ct, where ctis the salient feature summarized from {ai}. During the process of extracting the salient featurect, the current statehtin decoder plays as a key and the encoder states {ai} play as a source to be searched [159]. The computation method of attention mechanism [13], [156] can be defined as (26) to (28), and the compatibility scores between the key and the sources can be evaluated via one of the three different functions listed in (29).
根据选择部分特征时是否使用键,注意力机制可分为两类:基于键的注意力和较少键的注意力。基于键的注意力使用键来搜索突出的局部特征。以图像标题为例[13],其典型结构如图8所示,CNN网络将图像编码为特征集{ai},然后RNN网络将输入解码为隐藏状态{ht} 。在时间步t中,基于ht和ct预测输出yt,其中cti是从{ai}总结的显着特征。在提取显着特征的过程中,当前状态解码器充当键,编码器状态{ai}充当要搜索的源[159]。注意机制[13],[156]的计算方法可以定义为(26)至(28),并且可以通过(29)中列出的三个不同函数之一来评估密钥和源之间的兼容性分数。

Key-based attention is widespread in visual description applications [13], [90], [160], where an encoder-decoder network is commonly used. It brings us an approach to evaluate the importance of the features within a modality or among modalities. On the one hand, attention mechanism can be used to select the most salient features within a modality, on the other hand, it can be used to balance the contribution among modalities during fusing several modalities.
基于键的注意在视觉描述应用[13],[90],[160]中得到了广泛的应用,其中编码器-解码器网络通常被使用。它为我们带来了一种评估模态或模态之间特征重要性的方法。一方面,注意力机制可用于选择模态中最突出的特征,另一方面,注意力机制可用于在融合多个模态期间平衡模态之间的贡献。
In order to recognize and describe objects contained in the visual modality, a set of localized region features, which potentially encode different objects distinctly, would be more helpful than a single feature vector. By selecting the most salient regions in an image or time steps of a video sequence dynamically, both system performance and noise tolerance can be improved. For example, Xu et al. [13] adopted attention mechanism to detect salient objects in an image and fused them with text features in a decoder unit for captioning. In such a case, guided by current text generated in time step t, the attention module will be used to search local regions appropriate for predicting next word.
扫描二维码关注公众号,回复: 11102906 查看本文章
为了识别和描述视觉模态中包含的对象,一组可能局部地对不同对象进行编码的局部区域特征将比单个特征向量更有帮助。通过动态选择图像中的最显着区域或视频序列的时间步长,可以提高系统性能和噪声容限。例如,徐等。 [13]采用注意力机制来检测图像中的显着对象,并在解码器单元中将它们与文本特征融合以进行字幕。在这种情况下,在时间步骤t中生成的当前文本的指导下,注意力模块将用于搜索适合预测下一个单词的局部区域。
For locating local features more accurately, several attention models have been proposed. Y ang et al. [157] proposed a stacked attention network for searching image regions. They suggested that multiple steps of search or reasoning are helpful to locate to fine-grained regions. In the beginning, the model locates one or more local regions in the image by attention using language features as a key and then combines the attended visual and language features into a vector, which also plays as a key used for next iterator. After K steps, not only the appropriate local regions are located, but both features are fused. Zhu et al. [161] proposed a structured attention model to capture the semantic structure among image regions, and their experiments showed that this model is capable of inferring spatial relations and attending to the right region. Chen et al. [162] proposed to incorporate spatial and channel wise attentions in a CNN network. In their model, not only local regions but also channels of CNN features are filtered simultaneously.
为了更准确地定位局部特征,已经提出了几种注意力模型。扬等。 [157]提出了一种用于搜索图像区域的堆叠式注意力网络。他们认为,搜索或推理的多个步骤有助于找到细粒度的区域。首先,该模型通过使用语言特征作为键来吸引注意力来定位图像中的一个或多个局部区域,然后将参与的视觉和语言特征组合成向量,该向量也充当下一个迭代器的键。经过K步后,不仅找到了适当的局部区域,而且融合了两个要素。朱等。 [161]提出了一种结构化的注意力模型来捕获图像区域之间的语义结构,他们的实验表明,该模型能够推断空间关系并关注正确的区域。 Chen等。 [162]提出将空间和信道方面的注意力纳入CNN网络。在他们的模型中,不仅本地区域,而且CNN功能的通道也同时被过滤。
So far, attention models are mostly trained using indirect cues because of lacking explicit attention annotations. Alternatively, Gan et al. [163] trained the attention module using direct supervision. They collected link information between visual segments and words from several datasets and then utilized the link information to guide the training of attention module explicitly. The experiments showed that improved performance could be achieved.
到目前为止,由于缺少显式的注意力注释,注意力模型大多使用间接提示进行训练。另外,Gan等。 [163]使用直接监督训练了注意力模块。他们从多个数据集中收集了视觉片段和单词之间的链接信息,然后利用链接信息来明确指导注意模块的训练。实验表明可以提高性能。
Balancing the contribution of different modalities is a key issue that should be considered during fusing multimodal features. By contrast to concatenation or fixed weights fusion methods, an attention-based method can adaptively balance the contributions of different modalities. Several pieces of research [90], [91], [164] have been reported that dynamically assigning weights to modality-specific features condition on a context is helpful to improve application performance.
平衡不同模式的贡献是在融合多模式功能期间应考虑的关键问题。与级联或固定权重融合方法相比,基于注意力的方法可以自适应地平衡不同模式的贡献。已有几项研究[90],[91],[164]的研究表明,在上下文中将权重动态分配给特定于模态的特征条件有助于提高应用程序性能。
Horiet al. [90] proposed to tackle multimodal fusion based on attention for video description. In addition to attending on specific regions and time steps, the proposed method highlights attending on modality-specific information. After modality-specific features have been extracted, the attention module produces appropriate weights to combine features from different modalities based on the context. In a cross-modalretrievaltask,Chenet al. [164] adopted a similar strategy to adaptively fuse modalities and filter out unrelated information within each modality according to search keys.
霍里特等[90]提出解决基于注意力的视频描述多峰融合。除了参加特定区域和时间步骤之外,所提出的方法还强调了参加特定于情态的信息。在提取了特定于模态的特征之后,注意模块会根据上下文生成适当的权重,以合并来自不同模态的特征。 Chenet等人在跨模式检索任务中。 [164]采用了一种类似的策略来自适应融合模式,并根据搜索关键字过滤掉每个模式内不相关的信息。
Lu et al. [91] introduced an adaptive attention frame to determine whether including a visual feature or not during generating the caption. They argued that some words such as ‘‘the’’ are not related to any visual object. Therefore, no visual feature is needed in this case. Suppose that the visual feature is excluded, the decoder would just depend on the language features to predict a word.
Lu等。 [91]介绍了一种自适应注意力框架,以确定在生成字幕期间是否包括视觉特征。他们争辩说,诸如“ the”之类的词与任何视觉对象都不相关。因此,在这种情况下不需要视觉特征。假设视觉特征被排除,则解码器将仅依赖于语言特征来预测单词。
Keyless attentionis mostly used for classificationorregression task. In such an application scene, since the result is generated in a single step, it is hard to define a key to guide the attention module. Alternatively, the attention is applied directly on the localized features without any key involved. The computation functions can be illustrated as flow:
无钥匙注意力主要用于分类或回归任务。在这样的应用场景中,由于结果是在单个步骤中生成的,因此很难定义用于引导关注模块的键。可替代地,将注意力直接施加在局部特征上而无需任何关键。计算功能可以说明为流程:


Due to the nature to select prominent cues from raw input, keyless attention mechanism is suitable for a multimodal feature fusion task which suffers from issues such as semantic confliction, duplication, and noise. Through the attention mechanism, it provides us an approach to evaluate the relationship between parts of modalities, which may be complementary or supplementary. By selecting complementary features from different modalities and fusing them into a single representation, the semantic ambiguity could be eased.
由于从原始输入中选择突出提示的性质,无键注意机制适用于遭受语义冲突,重复和噪音等问题的多峰特征融合任务。通过注意力机制,它为我们提供了一种方法,可以评估模态各部分之间的关系,这可以是互补的,也可以是补充的。通过从不同的模态中选择互补特征并将其融合为单个表示,可以减轻语义上的歧义。
The advantage of attention mechanism in multimodal fusion has been proven in many applications. For example, Long et al. [165] compared four multimodal fusion methods and demonstrated that attention based method is the most effective one for addressing the video classification problem. They performed experiments in different setups: early fusion, middle-level fusion, attention-based fusion, and late fusion, which corresponding to different fusion points. The experimental result also shows that attention based fusion method is robust across various datasets. Some other researches also demonstrated the promising perspective of attention based methods for multimodal features fusion [166], [167].
注意机制在多峰融合中的优势已在许多应用中得到证明。例如,Long等。 [165]比较了四种多峰融合方法,并证明了基于注意力的方法是解决视频分类问题最有效的方法。他们以不同的设置进行了实验:早期融合,中级融合,基于注意力的融合和后期融合,它们对应于不同的融合点。实验结果还表明,基于注意力的融合方法在各种数据集中均具有鲁棒性。其他一些研究也证明了基于注意力的多模式特征融合方法的前景广阔[166],[167]。
A special issue on multimodal feature fusion is fusing features from several variable length sequences such as videos, audios, sentences or a set of localized features. A simple way to tackle this problem is fusing each sequence independently via the attention mechanism. After each sequence has been combined into a weighted representation with a fixed length, they will be concatenated or fused into a single vector. This way is beneficial for fusing several sequences, even in the case that their lengths are different, which is commonly seen in a multimodal dataset. However, such a simplified method does not explicitly consider the interaction between modalities, and thus may ignore the fine-grained cross-modal relationships.
关于多峰特征融合的一个特殊问题是融合来自多个可变长度序列的特征,例如视频,音频,句子或一组局部特征。解决此问题的一种简单方法是通过注意力机制独立地融合每个序列。在将每个序列组合成具有固定长度的加权表示后,它们将被串联或融合到单个向量中。即使在长度不同的情况下,这种方式也有利于融合多个序列,这在多模式数据集中通常会看到。但是,这种简化方法没有明确考虑模态之间的相互作用,因此可能会忽略细粒度的跨模态关系。
A solution to model the interactions between attention modules is constructing a shared context as an extra condition for the computation of modality-specific attention modules. For example, Lu et al. [24] proposed to construct a global context by calculating the similarity between visual and text features. Nam et al. [158] used an iterative strategy to update the shared context and modality-specific attention distribution. Firstly, modality-specific features will be summarized based on attention modules, then they are fused into a context used for next iterator.
对关注模块之间的交互进行建模的一种解决方案是构造一个共享上下文,作为计算特定于情态的关注模块的额外条件。例如,Lu等。 [24]提出通过计算视觉特征和文本特征之间的相似性来构建全局上下文。 Nam等。 [158]使用迭代策略来更新共享的上下文和特定于模式的注意力分布。首先,将基于注意模块总结特定于模式的功能,然后将其融合到用于下一个迭代器的上下文中。
Recently, a novel learning strategy named multi-attention mechanism, which utilizes several attention modules to extract different types of features from the same input data, has been exploited. Generally, each type of feature locates in a distinct subspace and reflects different semantics. Hence, the multi-attention mechanism is helpful in discovering different inter-modal dynamics. For example, Zadeh et al. [22] proposed to discovery diverse interactions between modalities using multi-attention mechanism. At each time step t,
最近,已经开发了一种新颖的名为多注意机制的学习策略,该策略利用多个注意模块从相同的输入数据中提取不同类型的特征。通常,每种类型的特征都位于不同的子空间中,并反映出不同的语义。因此,多注意机制有助于发现不同的联运方式动力学。例如,Zadeh等。 [22]提出使用多注意机制来发现模态之间的各种相互作用。在每个时间步t,
the hidden states hmt from all modalities were concatenated into vector ht, then multi-attentions will be applied on htto extract K different weighted vectors which reflect distinctive cross-modal relationships. After that, all the K vectors are fused into a single vector which represents the shared hidden state across modalities at time t.
将所有模态的隐藏状态hmt连接到向量ht中,然后对ht进行多注意,以提取K个不同的加权矢量,这些向量反映了独特的跨模态关系。之后,将所有K个向量融合为一个向量,该向量表示在时间t跨模态的共享隐藏状态。
Another example is the model form Zhou et al. [167], which fused heterogeneous features of user behavior based on multi-attention mechanism. Here, a user behavior type can be seen as a distinctive modal, because different types of behaviors have distinctive attributes. The author supposed that the semantics of user behavior can be affected by the context. Hence, the semantic intensity of that behavior also depends on the context. Firstly, the model project all types of behaviors into a concatenated vector denoted as S, which is a global feature and plays as the context in the attention module. Then, S is projected into K latent semantic sub-spaces to represent different semantics. After that, the model fuses K sub-spaces through attention module.
另一个例子是Zhou等人的模型。 [167],它融合了基于多注意机制的用户行为的异构特征。在这里,用户行为类型可以被视为独特的模态,因为不同类型的行为具有独特的属性。作者认为,用户行为的语义可能会受到上下文的影响。因此,该行为的语义强度也取决于上下文。首先,该模型将所有类型的行为投影到表示为S的级联向量中,该向量是全局特征,在关注模块中充当上下文。然后,将S投影到K个潜在语义子空间中以表示不同的语义。之后,模型通过注意力模块融合K个子空间。
One of the advantages of attention mechanism is its capability to select salient and discriminative localized features, which can not only improve the performance of multimodal representations but also lead to better interpretability. Additionally, by selecting prominent cues, this technique can also help to tackle issues such as noise and help to fuse complementary semantics into multimodal representations.
注意机制的优点之一是它能够选择显着和有区别的局部特征,这不仅可以提高多模式表示的性能,而且可以带来更好的解释性。另外,通过选择突出的提示,该技术还可以帮助解决诸如噪音之类的问题,并有助于将互补语义融合到多模式表示中。
IV. CONCLUSION AND FUTURE DIRECTIONS
TABLE 3. A summary of the key issues, advantages and disadvantages for each framework or typical model described in this paper. One thing should be mentioned is that both cross-modal similarity model and deep canonical correlation analysis (DCCA) are belonged to coordinated representation framework.
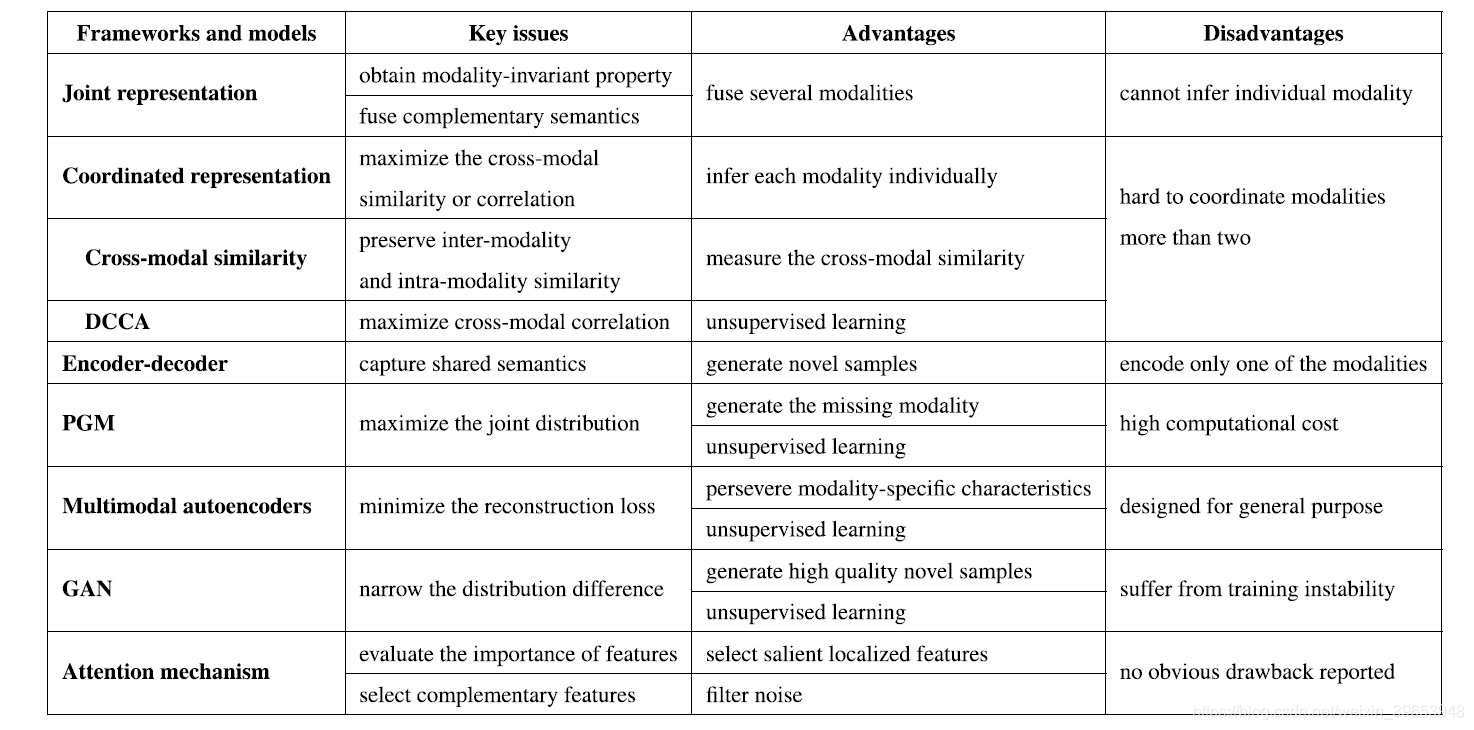
In this paper, we provided a comprehensive survey on deep multimodal representation learning. According to the underlying structures in which different modalities are integrated, we category deep multimodal representation learning methods into three groups of frameworks: joint representation, coordinated representation, and encoder-decoder. Additionally, we summarize some typical models in this area, which range from conventional models to newly developed technologies, including probabilistic graphical models, multimodal autoencoders, deep canonical correlation analysis, generative adversarial networks, and attention mechanism. For each framework or model, we describe its basic structure, learning objective, and application scenes. Additionally, we also discuss their key issues, advantages, and disadvantages which have been briefly summarized in Table 3.
在本文中,我们对深度多模式表示学习进行了全面的调查。根据集成了不同模态的基础结构,我们将深度多模态表示学习方法分为三类框架:联合表示,协调表示和编码器-解码器。此外,我们总结了该领域的一些典型模型,范围从传统模型到新开发的技术,包括概率图形模型,多模式自动编码器,深度典范相关分析,生成对抗网络和注意力机制。对于每个框架或模型,我们都描述其基本结构,学习目标和应用场景。此外,我们还讨论了它们的关键问题,优点和缺点,这些优点,缺点和缺点在表3中进行了简要总结。
When coming into the learning objectives and key issues in all kinds of learning frames or typical models, we can clearly see that the primary objective of multimodal representation learning is to narrow the distribution gap in a joint semantic subspace while keeping modality specific semantic intact. They achieve this objective in different ways: joint representation framework maps all modalities into a global common subspace; coordinated representation framework maximizes the similarity or correlation between modalities while keeping each modality independent; encoder-decoder framework maximizes the condition distribution among modalities and keep their semantics consistent; probabilistic graphical models maximize the joint probability distribution across modalities;multimodal auto encoders endeavor to keep modality specific distribution intact by minimizing the reconstruction errors; generative adversarial networks aims to narrow the distribution difference between modalities by an adversarial process; attention mechanism selects salient features from modalities,such that they are similar in local manifolds or such that they are complementary with each other.
当进入各种学习框架或典型模型的学习目标和关键问题时,我们可以清楚地看到,多峰表示学习的主要目标是缩小联合语义子空间中的分布差距,同时保持模态特定的语义完整。他们以不同的方式实现了这一目标:联合表示框架将所有模式映射到一个全局公共子空间中;协调的表示框架使模态之间的相似性或相关性最大化,同时使每个模态保持独立;编码器-解码器框架最大程度地提高了模态之间的条件分布并保持其语义的一致性;概率图形模型最大程度地提高了跨模态的联合概率分布;多模态自动编码器通过最小化重构误差,努力保持模态特定的分布完整;生成对抗网络旨在通过对抗过程缩小模式之间的分布差异;注意机制从模式中选择显着特征,使它们在局部流形中相似或彼此互补。
With the rapid development of deep multimodal representation learning methods, the need for much more training data is growing. However, the volume of the current multimodal datasets is limited because of the high cost of manual labeling. The acquirement of high-quality labeled datasets is extremely labor-consuming. A popular solution to address this problem is transfer learning, transferring general knowledge from the source domain with a large-scale dataset to target domain with insufficient data [168]. Transfer learning has been widely used in the multimodal representation learning area and has been shown to be effective in improving performance in many multimodal tasks. One of the examples is the reuse of pre-trained CNN network such as VGGNet [48], ResNet [49], which can be used for extracting image features in a multimodal system. The second example is word embeddings such as word2vec [50], Glove [51]. Although these representations of words are trained only on general-purpose language corpora, they can be transferred to other datasets directly even without fine-tuning.
随着深度多模态表示学习方法的迅速发展,对训练数据的需求也越来越大。然而,由于人工标注的高成本,目前的多模态数据集的容量有限。获取高质量的标记数据集是非常耗费人力的。解决这个问题的一个流行的解决方案是转移学习,将一般知识从具有大规模数据集的源域转移到数据不足的目标域[168]。转移学习在多模态表征学习领域得到了广泛的应用,并被证明能有效地提高多模态任务的性能。其中一个例子是预先训练的CNN网络的重用,例如VGGNet[48]、ResNet[49],它们可用于在多模式系统中提取图像特征。第二个例子是单词嵌入,比如word2vec[50],Glove[51]。尽管这些词的表示只能在通用语言语料库中训练,但即使没有微调,它们也可以直接传输到其他数据集。
In contrast to the widespread use of convenient and effective knowledge transfer strategy in image and language modality, similar methods are not yet available within audio or video modality. Hence, the deep networks used for extracting audio or video features would more easily suffer from overfitting due to the limited training instances. As a result, in many applications such as sentiment analysis and emotion recognition which based on fused multimodal features, it is relatively hard to improve the performance when only audio and video data are available. Alternatively, most works have to increasingly rely on a stronger language model. Although someeffortshavebeenmadetotransfercross-domainknowledge to audio and video modalities, in the multimodal representation learning area, more convenient and effective methods are still required.
与在图像和语言情态中广泛使用方便有效的知识转移策略相比,在音频或视频情态中还没有类似的方法。因此,由于训练实例有限,用于提取音频或视频特征的深层网络更容易遭受过度拟合的影响。因此,在基于融合多模态特征的情感分析和情感识别等应用中,仅利用音频和视频数据是很难提高性能的。另一方面,大多数作品不得不越来越依赖一种更强的语言模式。尽管在音频和视频模式的跨领域知识转换方面做了一些努力,但在多模态表示学习领域,仍然需要更方便有效的方法。
In Addition to the knowledge transferring within the same modality, cross-modal transfer learning which aims to transfer knowledge from one modality to another is also a significant research direction. For example, recent studies show that the knowledge transferred from images can help to improve the performance of video analysis tasks [169]. Besides, an alternative but the more challenging approach is the transfer learning between multimodal datasets. The advantage of this method is that the correlation information among different modalities in the source domain can also be exploited, while the weakness is its complexity, both modality difference and domain discrepancy should be tackled simultaneously.
除了在同一模态内进行知识转移外,旨在将知识从一种模态转移到另一种模态的跨模态转移学习也是一个重要的研究方向。例如,最近的研究表明,从图像中传输的知识有助于提高视频分析任务的性能[169]。此外,另一种更具挑战性的方法是多模态数据集之间的传递学习。该方法的优点是还可以利用源域中不同模态之间的相关信息,缺点是其复杂性,需要同时处理模态差异和域差异。
Another feasible future direction to tackle the problem of relying on large scale labeled datasets is unsupervised or weakly supervised learning, which can be trained using the ubiquitous multimodal data generated by internet users. Unsupervised learning has been widely used for dimensionality reduction and feature extraction on unlabeled datasets.
解决依赖大规模标签数据集的问题的另一个可行的未来方向是无监督学习或弱监督学习,可以使用互联网用户生成的无处不在的多峰数据进行训练。无监督学习已被广泛用于减少未标注数据集的维数和特征提取。
That is why conventional unsupervised learning methods such as multimodal autoencoders are still active today, although comparing to CNN or RNN features their performance are not so good. Due to a similar reason, generative adversarial nets has recently attracted much attention in the multimodal learning area.
这就是为什么传统的无监督学习方法(例如多模态自动编码器)今天仍然活跃的原因,尽管与CNN或RNN的功能相比,它们的性能还不是很好。由于类似的原因,生成对抗网络最近在多模式学习领域引起了很多关注。
Most recently, weakly supervised learning has demonstrated its potential in exploiting useful knowledge hidden behind the multimodal data. For example, given an image and its description, it is highly possible that a segment can be described by some words in the sentence. Although the oneto-one correspondences between them are fully unknown, the work proposed by Karpathy and Fei-Fei [76] shows that these hidden relationships can be discovered via weakly supervised learning. Potentially, a more promising application of these type of weak supervision based methods is video analysis, where different modalities such as actions, audios, languages have been roughly aligned in the timeline.
最近,弱监督学习证明了其在利用多模式数据背后隐藏的有用知识方面的潜力。例如,给定图像及其描述,很可能可以通过句子中的某些单词来描述一个句段。尽管它们之间的一对一对应关系是完全未知的,但Karpathy和Fei-Fei [76]提出的工作表明,可以通过弱监督学习来发现这些隐藏的关系。这些类型的基于弱监督的方法可能会更有前途的应用是视频分析,在这种视频分析中,不同的方式(例如动作,音频,语言)已在时间轴上大致对齐。
For a long time, multimodal representation learning suffers from issues such as semantic confliction, duplication, and noise. Although attention mechanism can be used to address these problems partially, they work implicitly and cannot be controlled actively. A more promising method for this problem is integrating reasoning ability into multimodal representation learning networks. Via the reasoning mechanism, a system would have the capability to select evidence actively which is sorely needed and could play an important role in mitigating the impact of these troubling issues. We believe thattheclosecombinationofrepresentationlearningandtheir reasoning mechanism will endow machines with intelligent cognitive capabilities.
长期以来,多模式表示学习遭受诸如语义冲突,重复和噪音等问题的困扰。尽管注意力机制可以用来部分解决这些问题,但是它们隐含地起作用并且不能被主动控制。解决此问题的一种更有希望的方法是将推理能力集成到多模式表示学习网络中。通过推理机制,系统将具有主动选择急需的证据的能力,并且可以在减轻这些令人困扰的问题的影响方面发挥重要作用。我们认为,表示学习的紧密结合及其推理机制将赋予机器智能的认知能力。
论文原文:点击此处
