目录
1.作者介绍
侯青山,男,西安工程大学电子信息学院,2021级研究生
研究方向:烟雾图像分割
电子邮件:[email protected]
刘帅波,男,西安工程大学电子信息学院,2021级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:[email protected]
2.关于理论方面的知识介绍
2.1决策树原理介绍
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
近来的调查表明决策树也是最经常使用的数据挖掘算法,它的概念非常简单。决策树算法之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。直观看上去,决策树分类器就像判断模块和终止块组成的流程图,终止块表示分类结果(也就是树的叶子)。判断模块表示对一个特征取值的判断(该特征有几个值,判断模块就有几个分支)。
如果不考虑效率等,那么样本所有特征的判断级联起来终会将某一个样本分到一个类终止块上。实际上,样本所有特征中有一些特征在分类时起到决定性作用,决策树的构造过程就是找到这些具有决定性作用的特征,根据其决定性程度来构造一个倒立的树–决定性作用最大的那个特征作为根节点,然后递归找到各分支下子数据集中次大的决定性特征,直至子数据集中所有数据都属于同一类。所以,构造决策树的过程本质上就是根据数据特征将数据集分类的递归过程,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。
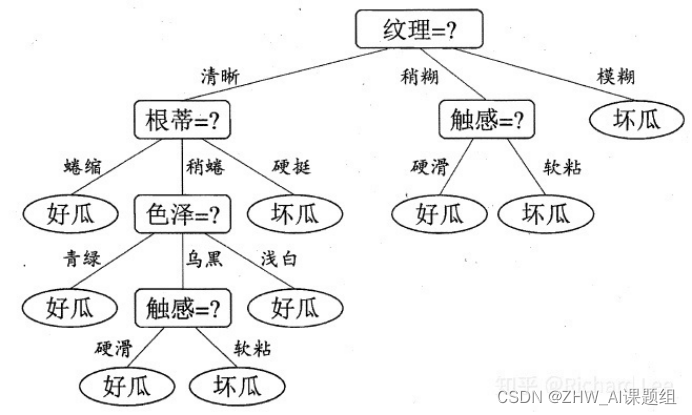
2.2决策树的生成过程
一棵决策树的生成过程主要分为以下3个部分:
-
特征选择:特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
-
决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
-
剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
扫描二维码关注公众号,回复: 13752790 查看本文章
2.3基于信息论的三种决策树
划分数据集的最大原则是:使无序的数据变的有序。如果一个训练数据中有20个特征,那么选取哪个做划分依据?这就必须采用量化的方法来判断,量化划分方法有多重,其中一项就是“信息论度量信息分类”。基于信息论的决策树算法有ID3、CART和C4.5等算法,其中C4.5和CART两种算法从ID3算法中衍生而来。
CART和C4.5支持数据特征为连续分布时的处理,主要通过使用二元切分来处理连续型变量,即求一个特定的值-分裂值:特征值大于分裂值就走左子树,或者就走右子树。这个分裂值的选取的原则是使得划分后的子树中的“混乱程度”降低,具体到C4.5和CART算法则有不同的定义方式。
ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。ID3算法中根据信息论的信息增益评估和选择特征,每次选择信息增益最大的特征做判断模块。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性–就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
C4.5是ID3的一个改进算法,继承了ID3算法的优点。C4.5算法用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足在树构造过程中进行剪枝;能够完成对连续属性的离散化处理;能够对不完整数据进行处理。C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。
CART算法的全称是Classification And Regression Tree,**采用的是Gini指数(选Gini指数最小的特征s)**作为分裂标准,同时它也是包含后剪枝操作。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大。为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART。
本文用的是ID3算法,调用的是sklearn.DecisionTreeClassifier()这个构建好的决策树,我们只需要调整一些参数即可。
2.4决策树及参数解释
classifier =tree.DecisionTreeClassifier(criterion='entropy', splitter='random',
max_depth=None,
min_samples_split=3,
min_samples_leaf=2,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,class_weight=None,)

标黄是一些常用调节参数
链接:sklearn.tree.DecisionTreeClassifier-scikit-learn中文社区
我们这里用的是ID3构建的决策树,所以在criterion里选用’entropy’。
3. 基于决策树的手写数字分类
3.1实验代码
##基于决策树的手写数字分类
from sklearn import tree
import numpy as np
from sklearn.datasets import load_digits
dataset = np.load('C:\\Users\\asus\\Desktop\\dateset\\mnist.npz')##获取数据集
x_train = dataset['x_train']#所有自变量,用于训练的自变量。
y_train = dataset['y_train']#这是训练数据的类别标签。
x_test = dataset['x_test']#这是剩下的数据部分,用来测试训练好的决策树的模型。
y_test = dataset['y_test']#这是测试数据的类别标签,用于区别实际类型和预测类型的准确性。
classifier = tree.DecisionTreeClassifier(criterion='entropy', splitter='random', max_depth=21, min_samples_split=3,random_state=40,)
#classifier = tree.DecisionTreeClassifier(criterion='entropy',splitter='random',max_depth=None,min_samples_split=3,min_samples_leaf=2,min_weight_fraction_leaf=0.0,max_features=None,random_state=None,max_leaf_nodes=None,min_impurity_decrease=0.0,min_impurity_split=None,class_weight=None,)
x_train = x_train.reshape(60000, 784)#第一个数字是用来索引图片,第二个数字是索引每张图片的像素点
x_test = x_test.reshape(10000, 784)
classifier.fit(x_train, y_train)
score = classifier.score(x_test, y_test)
print(score)
#tree.plot_tree(classifier)
#import matplotlib.pyplot as plt
#plt.show()
#后三行是画出决策树
3.2试验过程
以下是我个人测试结果最好的参数
criterion='entropy',
splitter='random',
max_depth=21,
min_samples_split=3,
random_state=40
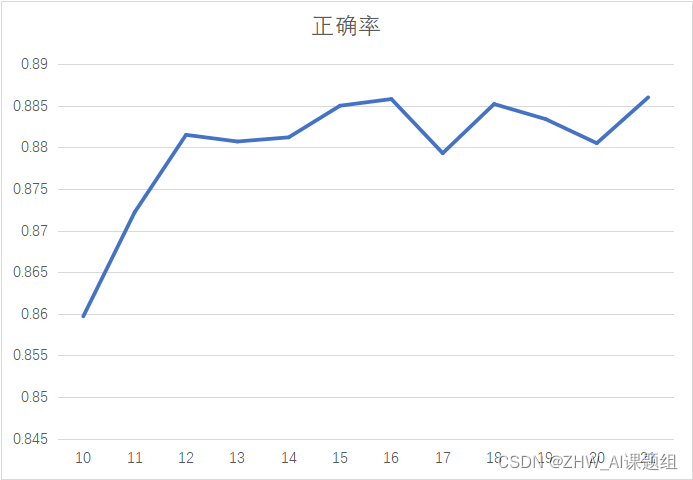
图三是max_depth的参数调试曲线,可以看到测试的正确率在86%~88%之间,当max_depth大于21时
正确率将稳定在88.6%,不再发生任何波动。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tpO2Kacz-1647868130461)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20220321105438659.png)]](https://img-blog.csdnimg.cn/1242bd62f48a4d1c9b8e0d5dd993d0b4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAWkhXX0FJ6K--6aKY57uE,size_18,color_FFFFFF,t_70,g_se,x_16#pic_center)
4.注意
4.1MNIST数据集介绍
MNIST数据集来自美国国家标准与技术研究所
National Institute of Standards and Technology (NIST)
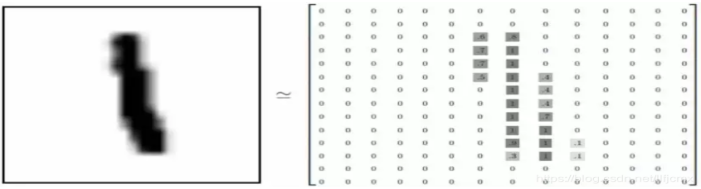
包括60000张训练图片和10000张测试图片
每张图片大小为28*28=784
在python3.6环境下需要安装以下包
pip install sklearn
pip install numpy
pip install matplotlib#这个包是画图用的
4.2MNIST数据集获取
4.2.1通过函数调用
from sklearn.datasets import load_digits
mnist = load_digits()
4.2.2下载到本地文件夹,再调用
我这里是下载到本地再调用的
下载地址1:mnist.npz 数据集 免费_小老弟偶的博客-CSDN博客
下载地址2:mnist数据集下载——mnist数据集提供百度网盘下载地址_bigcindy的博客-CSDN博客_mnist数据集
dataset = np.load('你的数据集位置')##获取数据集
#这里建议适用绝对路径位置
数据集下载——mnist数据集提供百度网盘下载地址_bigcindy的博客-CSDN博客_mnist数据集](https://blog.csdn.net/Jwenxue/article/details/89847251)
```python
dataset = np.load('你的数据集位置')##获取数据集
#这里建议适用绝对路径位置