1、通过问一系列问题,通过答案进行预测
2、推荐
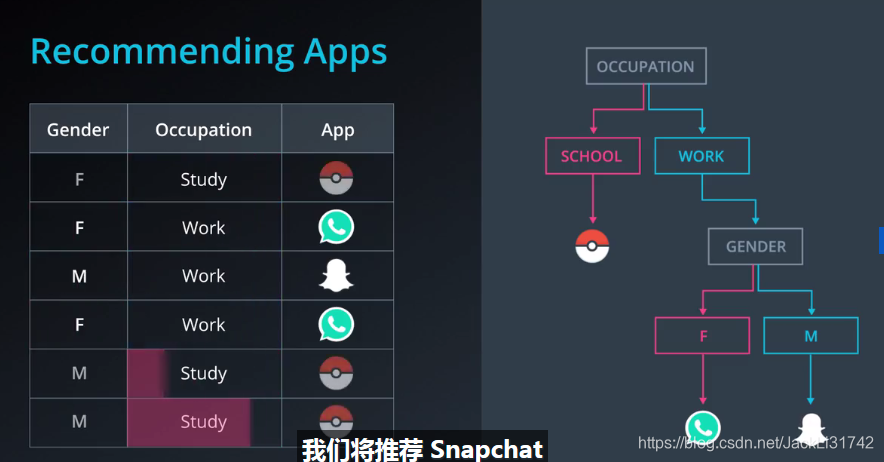
3、
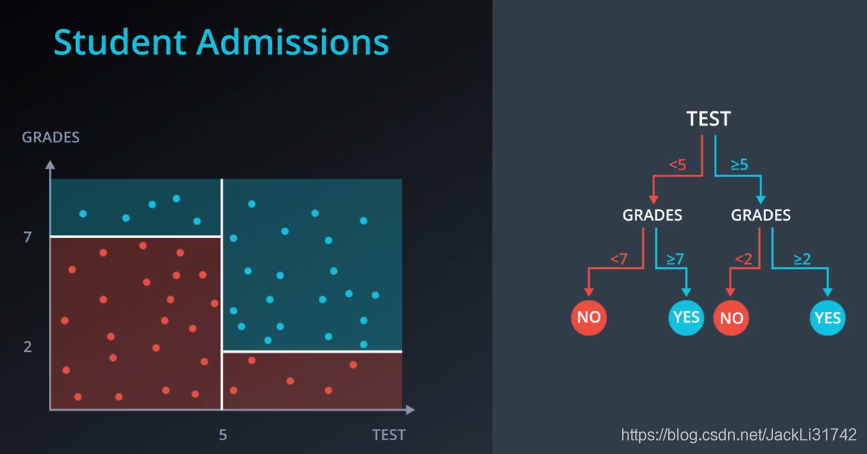 4、超参数
4、超参数
(1)最大深度
决策树的最大深度就是从根到叶之间可能的最大长度。一个最大深度为 k 的决策树最多有 2^k 个叶子。
(2)最少样本分割数
一个节点必须至少有min_samples_split个样本才能足够大以进行拆分。如果一个节点的样本数少于 min_samples_split 个, 则分割过程停止,该节点不会被分割。
然而 min_samples_split 不会控制叶的最小尺寸。正如你在上面右边的示例中看到的,父节点有20个样本,大于min_samples_split = 11,因此这个节点被拆分。但在此节点被拆分后,有一个子节点的样本数为5,小于min_samples_split = 11。
(3)每片叶子的最小样本数
当分割一个节点时,可能会遇到的一个问题是分割不均匀,例如某个子节点有99个样本,另一个子节点可能只有1个样本。这会影响决策树的生成,也浪费计算资源和时间。为避免这种情况,我们可以为每个叶子上允许的样本数设置一个最小值。
这个数字可以被指定为一个整数,也可以是一个浮点数。如果它是整数,它将表示这片叶子上的最小样本数。如果它是个浮点数,它将被视作每片叶子上的最小样本比例。比如,0.1 或 10% 表示如果一片叶子上的样本数量小于该节点中样本数量的 10%,这种分裂将不被允许
(4)每次分裂的最小样本数
这个参数与每片叶子上的最小样本树相同,只不过是应用在节点的分裂当中。
(5)最大特征数
有时,我们会遇到特征数量过于庞大,而无法建立决策树的情况。在这种状况下,对于每一个分裂,我们都需要检查整个数据集中的每一个特征。这种过程极为繁琐。而解决方案之一是限制每个分裂中查找的特征数。如果这个数字足够庞大,我们很有可能在查找的特征中找到良好特征(尽管也许并不是完美特征)。然而,如果这个数字小于特征数,这将极大加快我们的计算速度。
5、
>>> from sklearn.tree import DecisionTreeClassifier
>>> model = DecisionTreeClassifier()
>>> model.fit(x_values, y_values)
在上述示例中,model 变量是一个拟合到数据 x_values 和 y_values 的决策树模型。拟合模型是指寻找拟合训练数据的最佳线条。我们使用模型的 predict() 函数进行两项预测。
>>> print(model.predict([ [0.2, 0.8], [0.5, 0.4] ]))
[[ 0., 1.]]
该模型返回了一个预测结果数组,每个输入数组一个预测结果。第一个输入 [0.2, 0.8] 的预测结果为 0.。第二个输入 [0.5, 0.4] 的预测结果为 1.。
超参数
当我们定义模型时,可以指定超参数。在实践中,最常见的超参数包括:
max_depth:树中的最大层级数量。
min_samples_leaf:叶子允许的最低样本数量。
min_samples_split:拆分内部节点所需的最低样本数量。
max_features:寻找最佳拆分方法时要考虑的特征数量。
例如,在此例中,我们定义了一个模型:树的最大深度 max_depth 为7,每个叶子的最低元素数量 min_samples_leaf 是 10。
>>> model = DecisionTreeClassifier(max_depth = 7, min_samples_leaf = 10)
6、
你可以在以下练习的“data.csv”标签页中找到数据文件。它包含三列,前两列由点的坐标组成,第三列为标签。
我们将为你加载数据并将数据拆分为特征 X 和标签 y。
你需要完成以下每步:
1.构建决策树模型 *使用 scikit-learn 的 DecisionTree 构建决策树分类模型,并将其赋值给变量 model。
2.将模型与数据进行拟合
你不需要指定任何超参数,因为默认的超参数将以 100% 的准确率拟合数据。但是,建议你实验这些超参数,例如 max_depth 和 min_samples_leaf,并尝试找到最简单的潜在模型,即最不太可能过拟合的模型!
3.使用模型进行预测
预测训练集的标签,并将此列表赋值给变量 y_pred。
4.计算模型的准确率
为此,使用 sklearn 函数 accuracy_score。
# Import statements
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
# Read the data.
data = np.asarray(pd.read_csv('data.csv', header=None))
# Assign the features to the variable X, and the labels to the variable y.
X = data[:,0:2]
y = data[:,2]
# TODO: Create the decision tree model and assign it to the variable model.
model = DecisionTreeClassifier()
# TODO: Fit the model.
model.fit(X,y)
# TODO: Make predictions. Store them in the variable y_pred.
y_pred = model.predict(X)
# TODO: Calculate the accuracy and assign it to the variable acc.
acc = accuracy_score(y, y_pred)
0.24539,0.81725,0
0.21774,0.76462,0
0.20161,0.69737,0
0.20161,0.58041,0
0.2477,0.49561,0
0.32834,0.44883,0
0.39516,0.48099,0
0.39286,0.57164,0
0.33525,0.62135,0
0.33986,0.71199,0
0.34447,0.81433,0
0.28226,0.82602,0
0.26613,0.75,0
0.26613,0.63596,0
0.32604,0.54825,0
0.28917,0.65643,0
0.80069,0.71491,0
0.80069,0.64181,0
0.80069,0.50146,0
0.79839,0.36988,0
0.73157,0.25,0
0.63249,0.18275,0
0.60023,0.27047,0
0.66014,0.34649,0
0.70161,0.42251,0
0.70853,0.53947,0
0.71544,0.63304,0
0.74309,0.72076,0
0.75,0.63596,0
0.75,0.46345,0
0.72235,0.35526,0
0.66935,0.28509,0
0.20622,0.94298,1
0.26613,0.8962,1
0.38134,0.8962,1
0.42051,0.94591,1
0.49885,0.86404,1
0.31452,0.93421,1
0.53111,0.72076,1
0.45276,0.74415,1
0.53571,0.6038,1
0.60484,0.71491,1
0.60945,0.58333,1
0.51267,0.47807,1
0.50806,0.59211,1
0.46198,0.30556,1
0.5288,0.41082,1
0.38594,0.35819,1
0.31682,0.31433,1
0.29608,0.20906,1
0.36982,0.27632,1
0.42972,0.18275,1
0.51498,0.10965,1
0.53111,0.20906,1
0.59793,0.095029,1
0.73848,0.086257,1
0.83065,0.18275,1
0.8629,0.10965,1
0.88364,0.27924,1
0.93433,0.30848,1
0.93433,0.19444,1
0.92512,0.43421,1
0.87903,0.43421,1
0.87903,0.58626,1
0.9182,0.71491,1
0.85138,0.8348,1
0.85599,0.94006,1
0.70853,0.94298,1
0.70853,0.87281,1
0.59793,0.93129,1
0.61175,0.83187,1
0.78226,0.82895,1
0.78917,0.8962,1
0.90668,0.89912,1
0.14862,0.92251,1
0.15092,0.85819,1
0.097926,0.85819,1
0.079493,0.91374,1
0.079493,0.77632,1
0.10945,0.79678,1
0.12327,0.67982,1
0.077189,0.6886,1
0.081797,0.58626,1
0.14862,0.58041,1
0.14862,0.5307,1
0.14171,0.41959,1
0.08871,0.49269,1
0.095622,0.36696,1
0.24539,0.3962,1
0.1947,0.29678,1
0.16935,0.22368,1
0.15553,0.13596,1
0.23848,0.12427,1
0.33065,0.12427,1
0.095622,0.2617,1
0.091014,0.20322,1
