决策树分类
决策树分类归类于监督学习,能够根据特征值一层一层的将数据集进行分类。它的有点在于计算复杂度不高,分类出的结果能够很直观的呈现,但是也会出现过度匹配的问题。使用ID3算法的决策树分类第一步需要挑选出一个特征值,能够将数据集最好的分类,之后递归构成分类树。使用信息增益,来得到最佳的分类特制。
信息增益
根据某一特征划分数据集之后,信息发生的变化就叫做信息增益,计算出根据哪一个特征值划分之后数据集的信息增益值最大,那个该特制就是当前划分数据集的最好特征。可以用下面的公式计算得到信息增益值:
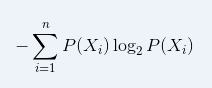
 为同一类别的概率值。例如一个数据集有10条记录 3条记录类别属于A类, 7条记录类别属于B类 根据公式就有 信息增益值为 -(0.3*log2(0.3) + 0.7*log2(0.7))。
为同一类别的概率值。例如一个数据集有10条记录 3条记录类别属于A类, 7条记录类别属于B类 根据公式就有 信息增益值为 -(0.3*log2(0.3) + 0.7*log2(0.7))。
定义一个函数的计算该值
def calcuShannon(dataset): dataset_row = len(dataset) #得到数据集的行数 labels = {} #声明一个标签字典 for featVec in dataset: lable = featVec[-1] #得到每一行最后的标签归类 if label not in labels.keys(): labels[lable] = 0 labels[lable] += 1 #得到每一个分类标签的数量 shannon = 0.0 for key in labels: pro = float(labels[key])/dataset_row Shannon -= pro *log(pro, 2) return shannon #返回 信息增益值
举一个实际运用的例子,有如下数据集 有四个特征 X1, X2, X3, X4

接下来计算一下以X2特征作为划分的之后信息增益值。
X2的取值有1,0,按1 切割矩阵后得到

计算 S1 = -((2/3) * log2 (2/3) + (1/3)*log2(1/3))
按0切割矩阵后得到

计算 S2 = -(1 * log21 )
总得信息增益值 S = (3/6)*S1 + (3/6)*S2
上面是以X2划分得到的信息增益值 ,循环计算得到 所有特征的该值,最后取出最大的一个,那么该特征就是最佳的分类特征,得到之后的子数据集矩阵,重复这一过程,当所有的特征都划分完毕,或者子集中的数据都属于同一类,停止划分 比如。
# 某一列 指定的值 划分出 数据矩阵 def splitdataset(dataset, axis, value): redataset = [] for featVec in dataset: if featVec[axis] == value: reduecfeatVec = featVec[:, axis] reduecfeatVec.extend(featVec[axis, :]) redataset.append(reduecfeatVec) return redataset
#传入数据 输入最佳的划分特征 def getbestfeature(dataset): numfeature = len(dataset[0]) - 1 #得到特征数量 baseEntropy = caluShannonent(dataset) #计算数据集的基础信息增益值 bestinfoGain = 0.0 bestfeature = -1 for i in range(numfeature): featlist = [] for data_row in dataset: featlist.extend(data_row[i]) #得到第i列的特征量 uniqueVals = set(featlist) #构造一个list,去除掉重复值 newEntropy = 0.0 for value in uniqueVals: #根据第i列以及取值划分数据集 subdataset = splitdataset(dataset, i, value) #得到子数据集 prob =len(subdataset)/float(len(dataset)) newEntropy += prob *calcuShannon(subdataset) #得到第i的信息增益值 infoGain = baseEntropy - newEntropy if infoGain > bestinfoGain : bestinfoGain = infoGain bestfeature = i return bestfeature #返回最佳划分特征 列号
递归生成分分类树:
#所有特征都划分完成,最后的标签中若并不是所有都是属于同一类,调用该函数返回最多哪一类 def majorityCnt(classlist): classcount = {} for vote in classlist: if vote in classlist: classcount[vote] = 0 classcount[vote] += 1 sortedclasscount = sorted(classcount.iteritems(), key = operator.itemgetter(1), reverse= True) return sortedclasscount[0][0] def createTree(dataset, lables): classList = [example[-1] for example in dataset] #生成分类列 if classList.count(classList[0]) == len(classList): #所有标签属于同一类 return classList[0] if len(dataset[0]) == 1:#只存在标签列 return majorityCnt(classList) bestfeat = getbestfeature(dataset)#返回最佳分类特征索引 bestfeatlabel = lables[bestfeat] #返回特征值 del(lables[bestfeat])#删除该最佳分类特征 classifyTree = {bestfeatlabel: {}} bestfeatColValue = [example[bestfeat] for example in dataset] uniqueValue = set(bestfeatColValue) for value in uniqueValue: sublabels = lables[:] classifyTree = createTree(splitdataset(dataset, bestfeat, value), sublabels)#递归调用生成分类树 return classifyTree