目录
一、决策树模型
决策树(Decision Tree)是一类常见的机器学习方法,可应用于分类与回归任务,这里主要讨论分类决策树。决策树是基于树结构来进行决策的。下图是使用决策树来决定是否见对象,可以把决策树看作根据要回答的一系列问题,做出决策来进行数据分类。
一般地,决策树由结点(Node)和有向边(Directed Edge)组成。一棵决策树包含一个根结点(Root Node)、若干内部结点(Internal Node)和若干叶节点(Leaf Node);叶结点对应于决策结果,其他结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;如此,从根节点到叶节点的每条路径都对应了一个判定测试序列。
在分类问题中,决策树表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。决策树学习一般包括三个步骤:特征选择、决策树的生成和决策树的修剪。
二、数据集
鸢尾花数据集是Python中sklearn自带的数据集。此处首先按3:7的比例划分了测试集和训练集,由于数据本身是四维特征,此处采用数据降维技术将数据降至二维。代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 对训练数据进行降维
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)三、构建决策树
决策树可以通过将特征空间划分成不同的矩形来构建复杂的决策边界。然而在实践中,需要注意的是,决策树越深,其决策边界就越复杂,从而越容易导致过拟合。下面的代码使用sklearn来训练决策树模型,假设最大深度为4,并且使用基尼指数作为纯度度量的标准。为了呈现较好的可视化效果,实例调整了样本特征数据的比例。生成决策树的代码如下:
from sklearn.tree import DecisionTreeClassifier
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
tree_model = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=1)
tree_model.fit(X_train_pca, y_train)
x_combined = np.vstack((X_train_pca,X_test_pca))
y_combined = np.hstack((y_train,y_test))
plt.subplot(121)
plot_decision_regions(x_combined, y_combined, clf=tree_model)
plt.xlabel("petal length(cm)")
plt.ylabel("petal width(cm)")
plt.legend(loc='upper center')
plt.title('Train & Test Data')
plt.subplot(122)
plot_decision_regions(X_test_pca, y_test, clf=tree_model)
plt.xlabel("petal length(cm)")
plt.ylabel("petal width(cm)")
plt.legend(loc='upper center')
plt.title('Test Data')
plt.tight_layout()
plt.show()注意:如果没有安装mlxtend模块的话,请安装,安装代码如下:
!pip install --upgrade mlxtend
之所以要按照最新版本,是为了防止版本不同而导致的参数名错误。
四、案例结果及分析
1)决策树的决策区域图

执行代码后,得到的决策树的决策区域如上图所示,可见其决策边界与坐标轴平行。
注意:这段代码的横纵坐标是通过PCA降维后的前两个主成分(principal components)得到的。在这个例子中,原始数据集有4个特征,但是经过PCA降维后,只保留了前两个主成分,因此横纵坐标分别代表了前两个主成分的值。这样做的好处是可以将高维数据可视化成二维平面上的点,并通过不同的颜色和形状来表示它们的类别信息。因此,横纵坐标出现负数我们也就能够理解了。为了方便,最后分析的时候,我们就按照对应的坐标值来进行分析。
2)决策树决策过程的可视化
sklearn库提供了在模型训练后,把决策树以.dot文件的格式导出(下面的代码没有导出.dot格式的文件,如果要导出该类文件,只需将代码'out_file=None'中的'None'改成你想要的文件名即可)。接着调用Graphviz程序即可完成决策树决策过程的可视化。
可以从Graphviz官方网站(网址:Graphviz)下载,它支持Linux、Windows、Solaris已经FreeBSD。除了Graphviz以为,还需要使用一个名为pydotplus的Python库,其功能与Graphviz类似,该库允许把.dot数据文件转换为决策树的图像。
安装Graphviz的教程:给小白准备的graphviz图文安装教程(2021最新)_实在人dx的博客-CSDN博客
安装pydotplus的代码:
pip install pydotplus3)将决策树图像保存在本地目录的代码:
from sklearn.tree import export_graphviz
from pydotplus import graph_from_dot_data
# 导出决策树
# out_file参数指定导出的文件名及路径,feature_names参数指定特征名称(如果有的话),filled和rounded参数用于美化决策树。
dot_data = export_graphviz(tree_model, out_file=None, feature_names=['petal length', 'petal width'], class_names=['Setosa', 'Versicolor', 'Virginica'], filled=True, rounded=True, special_characters=True)
# 把.dot文件转成png图片
graph = graph_from_dot_data(dot_data)
graph.write_png('tree.png')通过设置out_file=None,可以把数据赋给dot_data。参数filled、rounded、class_names和feature_names为可选项,添加颜色、框的边缘圆角会使图像呈现的视觉效果更好。在每个结点上显示大多数分类标签以及分类标准的特征。
4)决策树图像
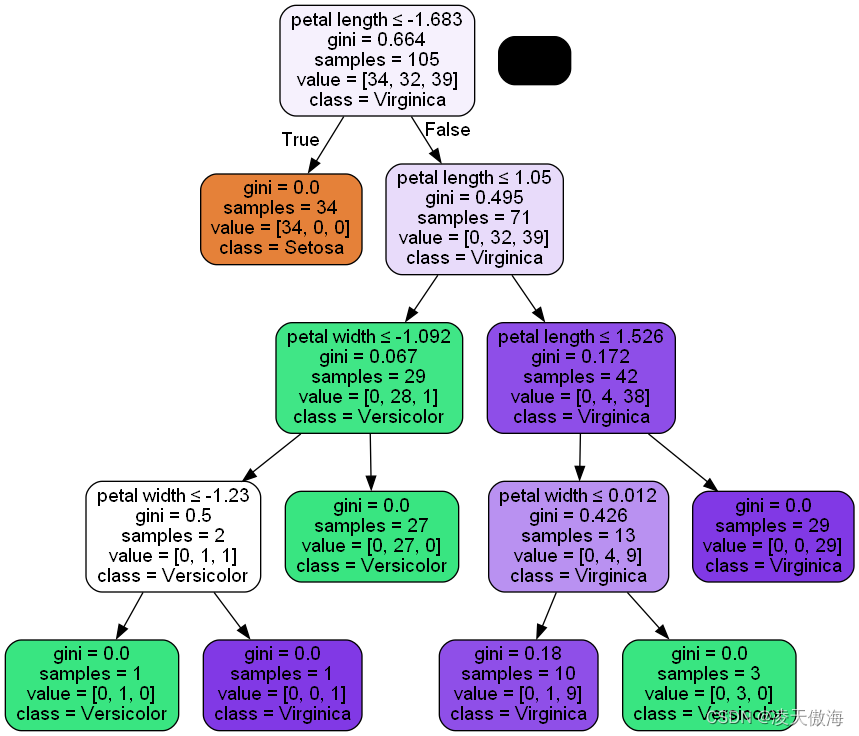
5)结果分析
将一个决策过程进行可视化后得到如上图所示的决策树,在决策树上可以很好地追溯训练集的结点分裂过程。从包含全部105个样本的根结点开始,以花瓣宽度-1.683cm(注:是负数的原因在1)处进行了解释)作为决策条件,将所有样本分割为34个样本和71个样本的两个子结点。由上图可知,左边子结点的纯度已经达到较高的程度,只包含Iris-setosa样本(基尼指数=0),因此成为叶结点。而右边的子结点的基尼指数为0.495,还需进一步分裂成Iris-versicolor和Iris-virginca两类。
从决策树的决策区域图中可以看到决策树在鸢尾花花朵分类上的表现不错。虽然sklearn目前还没有提供有关于手动修剪决策树的功能。但是,在前面决策树构建的代码中,只需要把决策树的参数max_depth修改为3,就能够做到预先限制决策树深度的作用,如下图所示。
