版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_33434901/article/details/82259308
1 回归度量
继房价预测后,导入糖尿病数据集diabetes进行回归预测。这次观察的超参数除了stddev和lr外还观察了隐藏层神经元个数的影响,并应魏聪明的要求加入了公式化的评价指标,主要使用sklearn.metrics库里的回归度量函数。sklearn.metrics里共有5个回归度量函数,以下为各个回归度量的维基百科解释和sklearn中英文官方文档截图:
1.1 解释方差分数(explained_variance_score)
维基百科:https://en.wikipedia.org/wiki/Explained_variation


1.2 平均绝对误差(mean_absolute_error)
维基百科:https://en.wikipedia.org/wiki/Mean_absolute_error
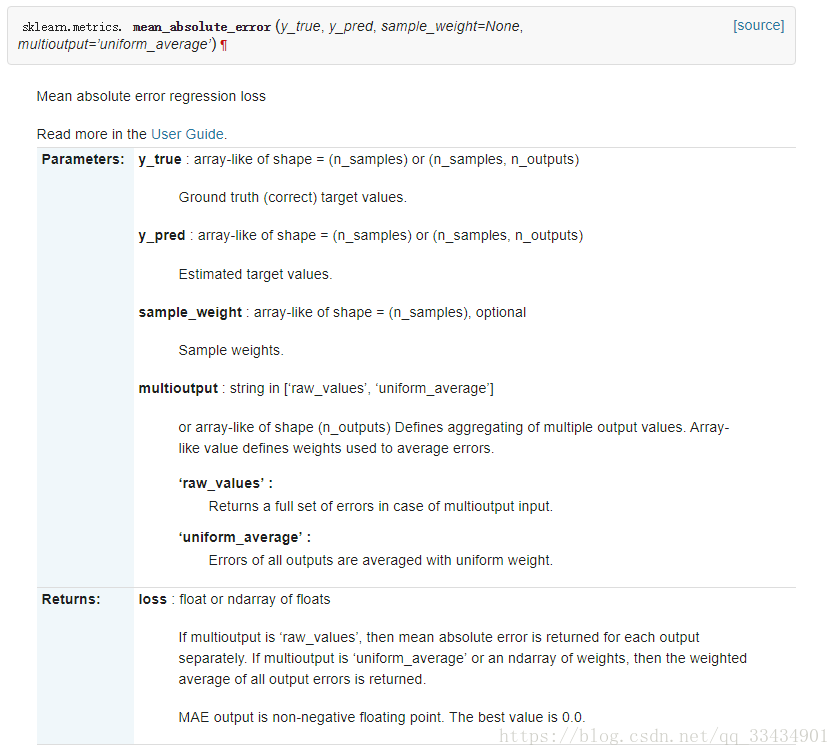

1.3 均方误差(mean_squared_error)
维基百科:https://en.wikipedia.org/wiki/Mean_squared_error


1.4 中间绝对误差(median_absolute_error)


1.5 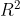 系数
系数
维基百科:https://en.wikipedia.org/wiki/Coefficient_of_determination

2 糖尿病预测
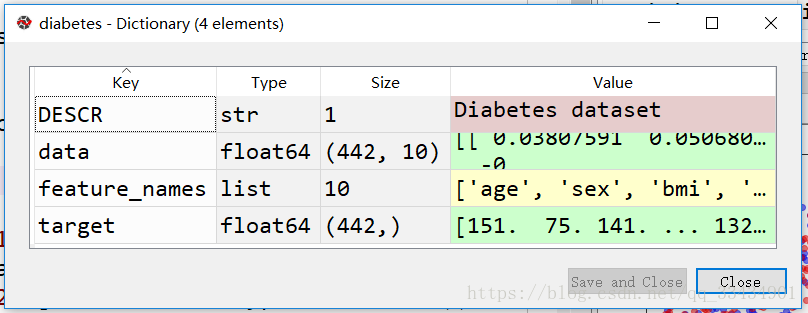
仍然使用sklearn里自带的数据集,训练diabetes这个数据集的目标是预测一年后患糖尿病的可能性。数据集如下(共10个特征,442条数据):
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 29 16:40:57 2018
@author: Zheng
"""
#这次要对神经元个数进行观察,继续观察stddev和lr,同时加入公式化评价指标
import tensorflow as tf
from sklearn.datasets import load_diabetes
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
#diabetes=load_diabetes()
w1 = tf.Variable(tf.random_normal(shape=[10,2],stddev=0.1,dtype=tf.float64))
b1 = tf.Variable(tf.constant(value=0.0,shape=[2,],dtype=tf.float64))
w2 = tf.Variable(tf.random_normal(shape=[2,1],stddev=0.1,dtype=tf.float64))
b2 = tf.Variable(tf.constant(value=0.0,shape=[1,],dtype=tf.float64))
def inference(X):
a = tf.nn.relu(tf.matmul(X,w1)+b1)
return tf.matmul(a,w2)+b2
def loss(X,Y):
Y_predict = inference(X)
total_loss = tf.reduce_mean(tf.squared_difference(Y,Y_predict))
return Y_predict,total_loss
def inputs():
diabetes = load_diabetes()
MinMax = MinMaxScaler()
X = MinMax.fit_transform(diabetes.data)
target = diabetes.target.reshape(-1,1)
Y = MinMax.fit_transform(target)
return X,Y
def train(total_loss):
lr = 0.1
return tf.train.GradientDescentOptimizer(lr).minimize(total_loss)
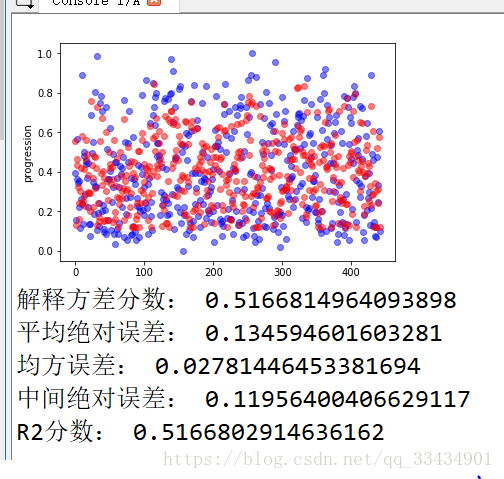
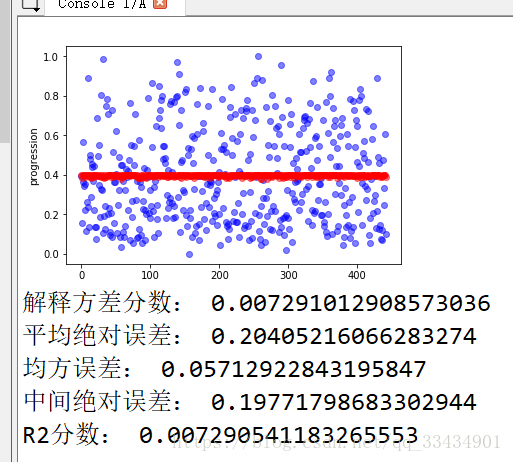
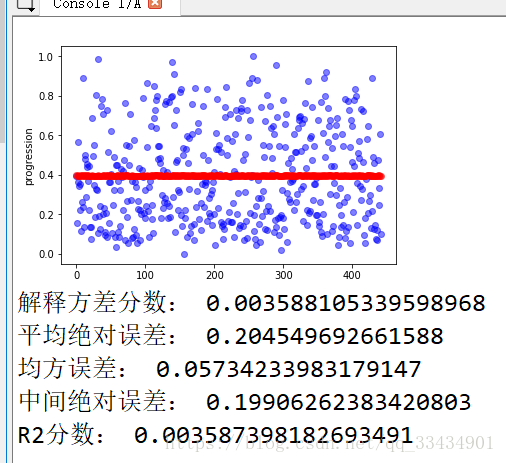
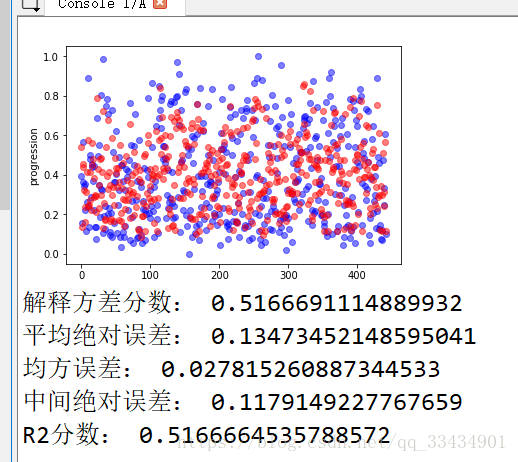
def evaluate(Y,Y_p):
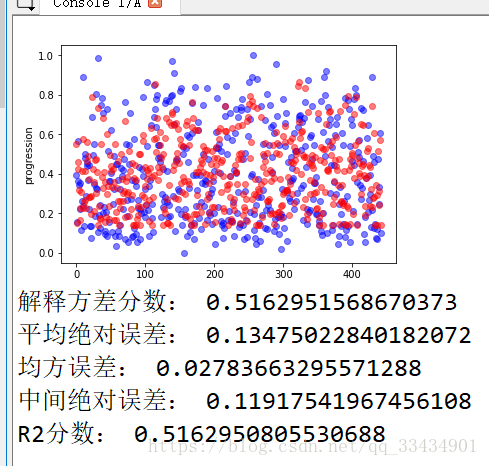
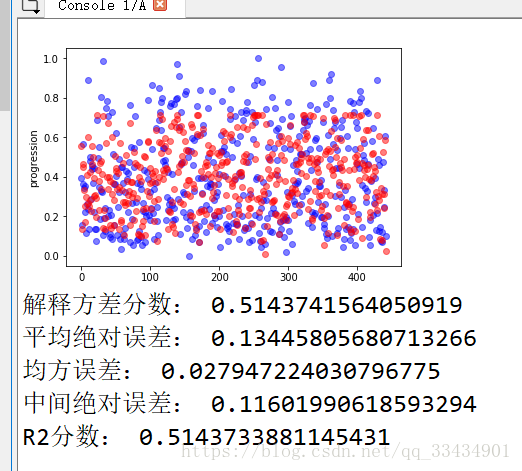
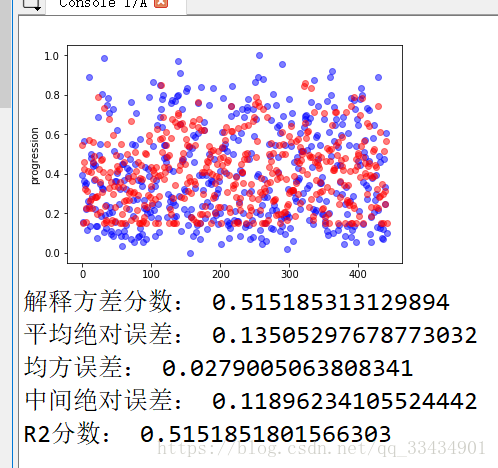
print("解释方差分数:",metrics.explained_variance_score(Y,Y_p))
print("平均绝对误差:",metrics.mean_absolute_error(Y,Y_p))
print("均方误差:",metrics.mean_squared_error(Y,Y_p))
print("中间绝对误差:",metrics.median_absolute_error(Y,Y_p))
print("R2分数:",metrics.r2_score(Y,Y_p))
def plot_fun(Y,Y_p):
plt.figure()
plt.plot(Y,'bo',alpha=0.5)
plt.plot(Y_p,'ro',alpha=0.5)
plt.ylabel('progression')
plt.show()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
X,Y = inputs()
Y_predict,total_loss = loss(X,Y)
train_op = train(total_loss)
training_steps = 1000
for i in range(training_steps):
sess.run(train_op)
if i % 10 == 0:
print("loss:",sess.run(total_loss))
Y_p = sess.run(Y_predict)
plot_fun(Y,Y_p)
evaluate(Y,Y_p)
sess.close()