朴素贝叶斯分类器需要通过拉普拉斯修正来提高其鲁棒性。
本文需要上一篇博文的基础:【AI数学原理】概率机器学习(二):朴素贝叶斯分类器
为什么不用拉普拉斯修正的NB分类器鲁棒性不理想呢?主要还是疏于考虑这种情况:
某个属性值在训练集中没有与某个类同时出现过。
当然,你可以说这是训练集的锅,但现实中的训练集就是逐渐增大的过程,你不能说训练集不够你这分类器就不行。记住:男人,不能说不行。
举个例子来说明原因:当某个属性‘才华’(取值有‘高’,‘中’,‘低’)和分类结果‘渣男’,而在训练数据中并没有‘才华’ = ‘中’和分类结果=‘渣男’的数据。所以用朴素贝叶斯分类器的时候,就会有:
如 上一篇博文所说,朴素贝叶斯公式就是一个累乘的公式,当因子中有一个为0,那结果就变为0了。这就是朴素贝叶斯鲁棒性不高的究极原因。
如果认真揣摸过上一篇博文的话,可以知道这种不稳定性只出现在离散取值属性中。当离散属性的每个取值没有被训练数据遍历到,就会出现这种问题。
拉普拉斯修正就解决了这个问题:
令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数,把P(c)和P(xi|c)的公式分别修正为:
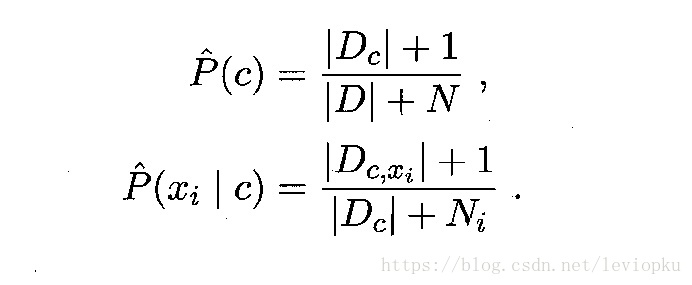
这样就算|Dc,xi| = 0,最后的P(xi|c)=1/(Dc+Ni),不会变成0从而使全局归零。有效避免了因训练样本不充分而导致概率估值为0的问题。