如有错误,恳请指出。
这篇博客是一篇归纳总结性的博客,对几篇mlp结构文章进行汇总。
1. gMLP
MLP-Mixer的增强版,带gating的MLP。有两个版本,分别是gMLP和aMLP。
gmlp的g是“gate”的意思,简单来说gmlp就是将mlp-mixer跟门控机制结合起来。即将输入沿着特征维度分为两半,然后将其中一半传入mlp-mixer,作为另一半的gate。
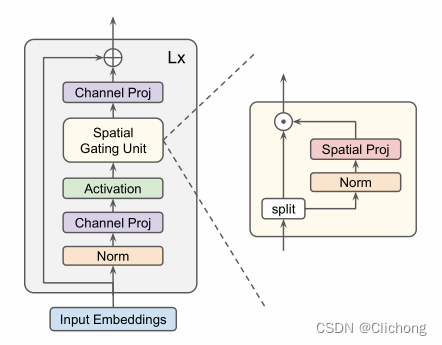
- 核心代码:
def gmlp_block(x, d_model, d_ffn):
shortcut = x
x = norm(x, axis="channel")
x = proj(x, d_ffn, axis="channel")
x = gelu(x)
x = spatial_gating_unit(x)
x = proj(x, d_model, axis="channel")
return x + shortcut
def spatial_gating_unit(x):
u, v = split(x, axis="channel")
v = norm(v, axis="channel")
n = get_dim(v, axis="spatial")
v = proj(v, n, axis="spatial", init_bias=1)
return u ∗ v
2. aMLP
amlp的a是“attention”的意思,它将一个简单的单头Self Attention结合进去作为gate
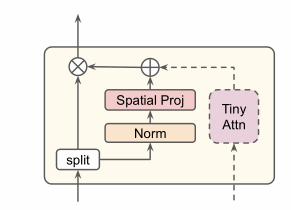
- 核心代码为:
def tiny_attn(x, d_out, d_attn=64):
qkv = proj(x, 3 ∗ d_attn, axis="channel")
q, k, v = split(qkv, 3, axis="channel")
w = einsum("bnd,bmd − >bnm", q, k)
a = softmax(w ∗ rsqrt(d_attn))
x = einsum("bnm,bmd − >bnd", a, v)
return proj(x, d_out, axis="channel")
3. ResMLP
这篇和前面的一些文章都很像,主要构建了一个残差架构,其残差块只由一个隐藏层的前馈网络和一个线性patch交互层组成。模型图如上,有两部分:
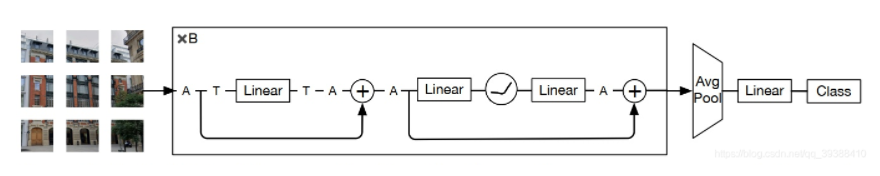
- 线性层Linear,其中图像 patches在通道之间独立且相同地交互
- 两层前馈网络,其中通道中的每个 patch独立地相互作用
其中Aff是类似LN的东西,GELU是激活函数。不过因为在深度学习中,层数的加深一般来说总是有好处的。所以这一启发性的行为,也对后续的工作很重要。
- 核心代码:
class Aff(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones([1, 1, hidden_dim])) # 1
self.beta = nn.Parameter(torch.zeros([1, 1, hidden_dim])) # 0
def forward(self, x):
x = x * self.alpha + self.beta
return x
class ResMLPBlock(nn.Module):
def __init__(self, hidden_dim, token_dim, expansion_factor):
super().__init__()
init_values = 0.1
self.pre_affine_trans = Aff(hidden_dim)
self.token_mixing = nn.Conv1d(token_dim, token_dim, kernel_size=1)
self.A = nn.Parameter(init_values * torch.ones((hidden_dim)), requires_grad=True)
self.post_affine_trans = Aff(hidden_dim)
self.channel_mixing = MLP(hidden_dim, expansion_factor)
self.B = nn.Parameter(init_values * torch.ones((hidden_dim)), requires_grad=True)
def forward(self, x):
x = self.pre_affine_trans(x) # like LayerNorm
z = x + self.A * self.token_mixing(x) # Token Mixing Operation
z = self.post_affine_trans(z) # like LayerNorm
y = z + self.B * self.channel_mixing(z) # Channel Mixing Operation
return y
4. RepMLP
CNN和MLP是否能够结合呢?
- CNN擅长捕捉局部的特征或模式识别,即归纳偏置或局部先验(local prior)。
- MLP更加擅长于建立特征的长依赖/全局关系与空间关系(所以 ViT 需要更大的训练集或数据扩增来训练模型)
那么两者可以结合吗?于是这篇清华的文章提出了 repmlp,巧妙利用“重参数”(re-parameterization)的方法,将局部的先验信息加进了全连接层。
- RepMLP结构图:
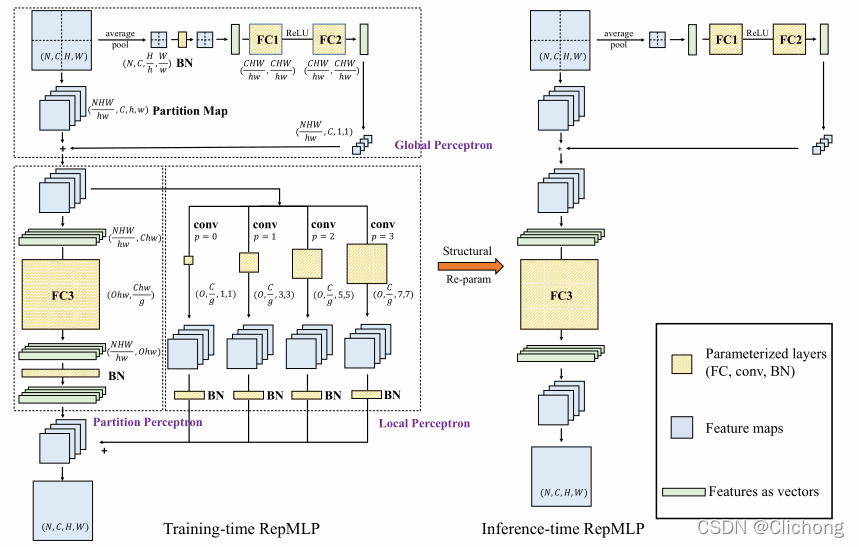
- RepMLPNet结构图(RepMLP的升级版):
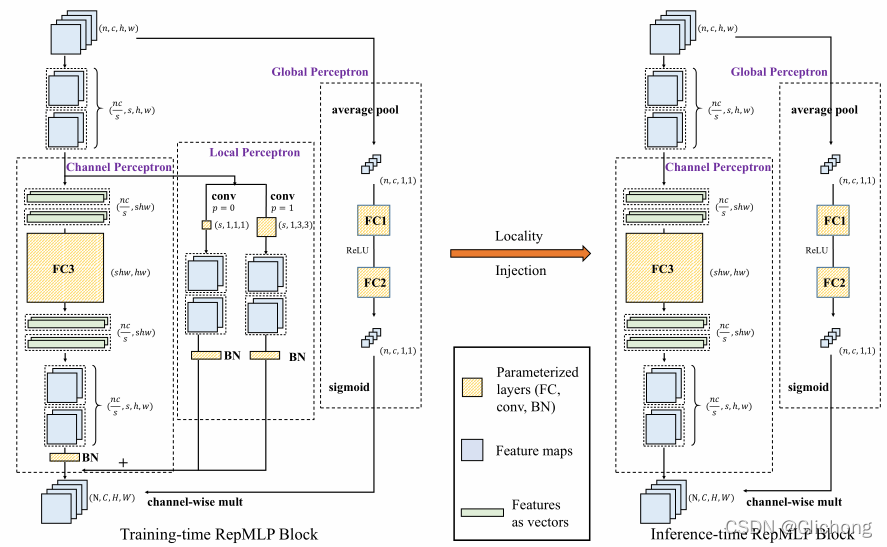
如上图,repmlp由三个部分组成,分别是Global Perceptron, Partition Perceptron and Local Perceptron。具体来说,其同时利用多层神经网络提取长期依赖关系与空间信息,并且利用结构化的重参数化,在网络训练时候将多个卷积模块与全连接并行,用其抽取对应的局部先验知识并最后进行信息融合汇总。
结构重参数的意思是:训练时的结构对应一组参数,推理时则对应另一组参数,而只要能把前者的参数等价转换为后者,就可以把前者的结果也等价转换。文章中公式太多了,核心就是如何把Conv+BN -> FC。
- 核心代码:
# get the weight and bias from cnn kernel or linear
def fuse_bn(conv_or_fc, bn):
std = (bn.running_var + bn.eps).sqrt()
t = bn.weight / std
t = t.reshape(-1, 1, 1, 1)
if len(t) == conv_or_fc.weight.size(0):
return conv_or_fc.weight * t, bn.bias - bn.running_mean * bn.weight / std
else:
repeat_times = conv_or_fc.weight.size(0) // len(t)
repeated = t.repeat_interleave(repeat_times, 0)
return conv_or_fc.weight * repeated, (bn.bias - bn.running_mean * bn.weight / std).repeat_interleave(
repeat_times, 0)
# convert repconv1/3 to fc
def _convert_conv_to_fc(self, conv_kernel, conv_bias):
I = torch.eye(self.h * self.w).repeat(1, self.S).reshape(self.h * self.w, self.S, self.h, self.w).to(conv_kernel.device)
fc_k = F.conv2d(I, conv_kernel, padding=(conv_kernel.size(2)//2,conv_kernel.size(3)//2), groups=self.S)
fc_k = fc_k.reshape(self.h * self.w, self.S * self.h * self.w).t()
fc_bias = conv_bias.repeat_interleave(self.h * self.w)
return fc_k, fc_bias
# the major block
class RepMLPBlock(nn.Module):
def __init__(self, in_channels, out_channels,
h, w,
reparam_conv_k=None,
globalperceptron_reduce=4,
num_sharesets=1,
deploy=False):
super().__init__()
self.C = in_channels
self.O = out_channels
self.S = num_sharesets
self.h, self.w = h, w
self.deploy = deploy
assert in_channels == out_channels
self.gp = GlobalPerceptron(input_channels=in_channels, internal_neurons=in_channels // globalperceptron_reduce)
self.fc3 = nn.Conv2d(self.h * self.w * num_sharesets, self.h * self.w * num_sharesets, 1, 1, 0, bias=deploy, groups=num_sharesets)
if deploy:
self.fc3_bn = nn.Identity()
else:
self.fc3_bn = nn.BatchNorm2d(num_sharesets)
self.reparam_conv_k = reparam_conv_k
if not deploy and reparam_conv_k is not None:
for k in reparam_conv_k:
conv_branch = conv_bn(num_sharesets, num_sharesets, kernel_size=k, stride=1, padding=k//2, groups=num_sharesets)
self.__setattr__('repconv{}'.format(k), conv_branch)
def partition(self, x, h_parts, w_parts):
x = x.reshape(-1, self.C, h_parts, self.h, w_parts, self.w)
x = x.permute(0, 2, 4, 1, 3, 5)
return x
def partition_affine(self, x, h_parts, w_parts):
fc_inputs = x.reshape(-1, self.S * self.h * self.w, 1, 1)
out = self.fc3(fc_inputs)
out = out.reshape(-1, self.S, self.h, self.w)
out = self.fc3_bn(out)
out = out.reshape(-1, h_parts, w_parts, self.S, self.h, self.w)
return out
def forward(self, inputs):
# Global Perceptron
global_vec = self.gp(inputs)
origin_shape = inputs.size()
h_parts = origin_shape[2] // self.h
w_parts = origin_shape[3] // self.w
partitions = self.partition(inputs, h_parts, w_parts)
# Channel Perceptron
fc3_out = self.partition_affine(partitions, h_parts, w_parts)
# Local Perceptron
if self.reparam_conv_k is not None and not self.deploy:
conv_inputs = partitions.reshape(-1, self.S, self.h, self.w)
conv_out = 0
for k in self.reparam_conv_k:
conv_branch = self.__getattr__('repconv{}'.format(k))
conv_out += conv_branch(conv_inputs)
conv_out = conv_out.reshape(-1, h_parts, w_parts, self.S, self.h, self.w)
fc3_out += conv_out
fc3_out = fc3_out.permute(0, 3, 1, 4, 2, 5) # N, O, h_parts, out_h, w_parts, out_w
out = fc3_out.reshape(*origin_shape)
out = out * global_vec
return out
def get_equivalent_fc3(self):
fc_weight, fc_bias = fuse_bn(self.fc3, self.fc3_bn)
if self.reparam_conv_k is not None:
largest_k = max(self.reparam_conv_k)
largest_branch = self.__getattr__('repconv{}'.format(largest_k))
total_kernel, total_bias = fuse_bn(largest_branch.conv, largest_branch.bn)
for k in self.reparam_conv_k:
if k != largest_k:
k_branch = self.__getattr__('repconv{}'.format(k))
kernel, bias = fuse_bn(k_branch.conv, k_branch.bn)
total_kernel += F.pad(kernel, [(largest_k - k) // 2] * 4)
total_bias += bias
rep_weight, rep_bias = self._convert_conv_to_fc(total_kernel, total_bias)
final_fc3_weight = rep_weight.reshape_as(fc_weight) + fc_weight
final_fc3_bias = rep_bias + fc_bias
else:
final_fc3_weight = fc_weight
final_fc3_bias = fc_bias
return final_fc3_weight, final_fc3_bias
def local_inject(self):
self.deploy = True
# Locality Injection
fc3_weight, fc3_bias = self.get_equivalent_fc3()
# Remove Local Perceptron
if self.reparam_conv_k is not None:
for k in self.reparam_conv_k:
self.__delattr__('repconv{}'.format(k))
self.__delattr__('fc3')
self.__delattr__('fc3_bn')
self.fc3 = nn.Conv2d(self.S * self.h * self.w, self.S * self.h * self.w, 1, 1, 0, bias=True, groups=self.S)
self.fc3_bn = nn.Identity()
self.fc3.weight.data = fc3_weight
self.fc3.bias.data = fc3_bias
def _convert_conv_to_fc(self, conv_kernel, conv_bias):
I = torch.eye(self.h * self.w).repeat(1, self.S).reshape(self.h * self.w, self.S, self.h, self.w).to(conv_kernel.device)
fc_k = F.conv2d(I, conv_kernel, padding=(conv_kernel.size(2)//2,conv_kernel.size(3)//2), groups=self.S)
fc_k = fc_k.reshape(self.h * self.w, self.S * self.h * self.w).t()
fc_bias = conv_bias.repeat_interleave(self.h * self.w)
return fc_k, fc_bias
参考链接:
https://blog.csdn.net/qq_39388410/article/details/118878384