paper
论文阅读笔记
目录
TPU
基本信息:
- 论文名称:In-Datacenter Performance Analysis of a Tensor Processing Unit TM
- 作者:Norman P. Jouppi, Cliff Young等60+位
- 发表时间:ISCA(International Symposium on Computer Architecture),Toronto, Canada, June 26, 2017.
主要内容:
-
TPU:张量处理器
早至2006年,Google已经讨论在数据中心中部署GPU,FPGA或者定制的ASIC芯片。当时的结论是:极少有在专门硬件上运行的应用可以利用google丰富强大的数据中心能力,并且很难用很小代价进行性能提升。因此Google启动了一个高优先级的项目:为推理投产一个定制的ASIC芯片(并购买市售的GPU用于训练),就是TPU[4]。 -
架构
与其选择与一个CPU紧密集成,为了降低可能对部署造成的拖延,TPU被设计为通过PCIE总线连接的协处理器,这使得它能够像GPU一样直接插入到现有服务器中使用。进一步,为了简化硬件设计和调试,由服务器主机向TPU发送它需要执行的指令,而不是由TPU自行取指。因此,在这一原则上,TPU更像是一个浮点协处理器(FPU)而不是GPU。
设计目标是在TPU上运行整个推理过程,以减少与主机CPU的交互。并且TPU要足够灵活以能够符合2015年以及之后的神经网络NN需求,而不是仅满足2013年的NN需求。图1显示了TPU的模块图。主要的计算部件是右上角的黄色矩阵乘单元。其输入是蓝色的权重数据队列FIFO和蓝色的统一缓冲(UB:Unified Buffer),而其输出是蓝色的累加器(Acc: Accumulators)。黄色的激活单元在累加之后执行非线性函数,然后数据返回统一缓冲。
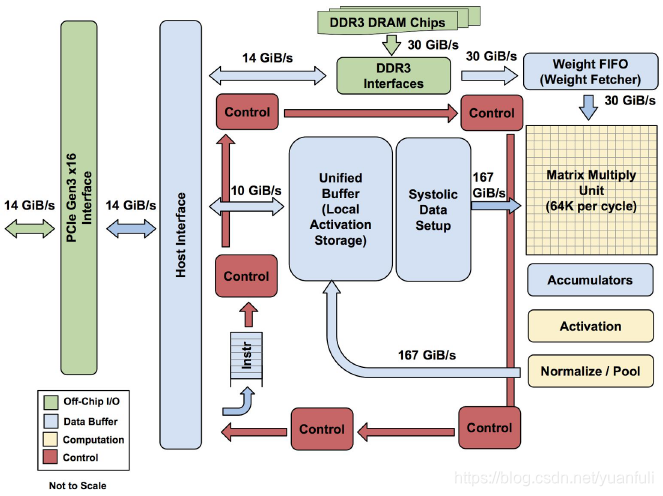
TPU的指令由主机通过PCIE Gen3 ⅹ16总线送入一个指令缓冲区。所有的内部模块通常用一个256字节宽(即1024位宽)的通路相连。从右上角开始,矩阵乘单元(Matrix Multiply Unit)是TPU的中心。它包含256x256个MAC部件,每一个能够执行有符号或者无符号的8位乘加操作。16位结果被收集并传递到位于矩阵单元下方的4MiB 32位累加器中。4MiB代表的是4096,但实际是256个32位累加器。矩阵单元每个时钟周期产生1个256个元素的部分和。
TPU微体系结构的设计哲学是保持矩阵单元在忙碌状态。TPU为这些CISC指令使用了4级流水线,而每条指令都在一个分离的流水段执行。原来计划是通过与矩阵乘指令的重叠来隐藏其他指令的执行。TPU并没有清晰的流水线重叠框图,因为其CISC指令可以占据一个流水段数千个时钟周期,而不像传统的RISC流水线一样只在每个流水段上占据一个时钟周期。当一个网络层次的激活操作,必需在下一个网络的矩阵乘开始之前完成时,就会产生有趣的现象;看起来和传统CPU中的“延迟槽”类似,矩阵单元必须等待明确的同步操作,然后安全地从统一缓冲区读取。 -
脉动阵列
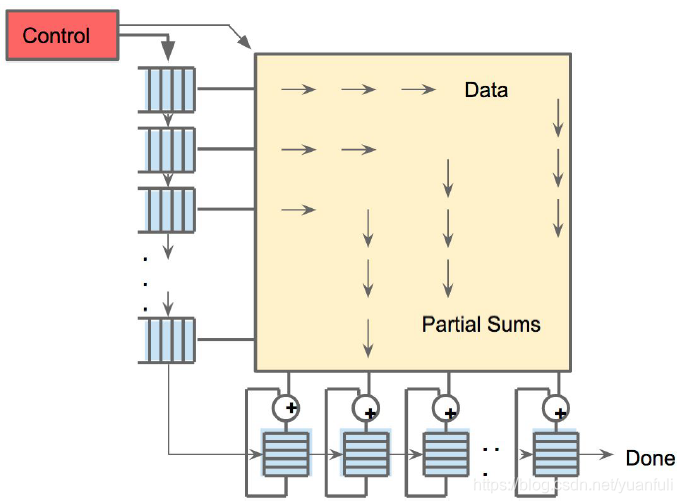
由于读取一个大尺寸SRAM耗费的功耗超过算术逻辑,矩阵单元通过减少对统一缓冲读和写的脉动执行(systolic exectution)来节约能耗[5]。图2显示从左边流入的数据,而权值则从上部载入。一个给定的256元素乘-累加操作以对角波diagonal wavefront的方式通过矩阵。权值被预先载入,并与一个新数据库中第一组数据的先行波产生效应。控制与数据被流水化,以造成如下错觉:256个输入被立刻读入,并且他们立刻更新256个累加器对应的存储区域。从正确性的角度来看,软件完全不知道矩阵乘单元的脉动特性,但从性能的角度看,软件需要关心单元的延迟。
DianNao
基本信息
- 论文名称:DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning
- 作者:Tianshi Chen,Zidong Du,Yunji Chen
- 发表时间:ASPLOS(Architectural Support for Programming Languages and Operating Systems), March 2014.
主要内容:
在过去几年中,神经网络技术已经被证明是广泛应用的最新技术。DianNao[6]是DianNao加速器系列的第一个成员,它容纳最先进的神经网络技术(如深度学习),并继承了神经网络的广泛应用范围。
架构
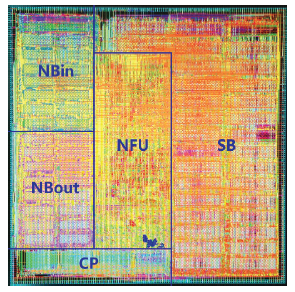
DianNao具有以下组件:用于输入神经元的输入缓冲区(NBin),用于输出神经元的输出缓冲区(NBout),以及用于突触权重(SB)的第三个缓冲区,它们连接到一个计算块(执行突触和神经元的计算),我们称之为神经功能单元(NFU)和控制逻辑(CP),详细参考下图.
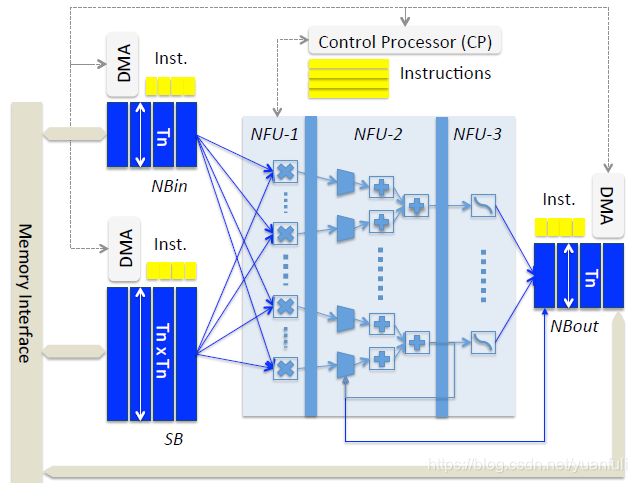
神经功能单元(NFU)。NFU实现了Ti个输入/突触和Tn个输出神经元的功能块,可以由不同的神经元算法分时复用。根据层类型的不同,NFU的计算可以分解为两个或三个阶段。对于分类层和卷积层:输入乘突触,之后所有的乘的结果相加,最后阶段(sigmod或其他非线性函数)的性质是可以变化的。对于池化层,没有乘法,池化操作可以是去平均值或最大值。注意,加法器有多个输入,它们实际上是加法树,见图1;第二阶段也包含移位器和用于池化层的最大操作。在NFU中可以使用分段线性插值(F(x)=a_i×x+b_i ,xϵ[x_i,x_(i+1) ])有效地实现sigmod函数(用于分类层和卷积层),精度损失可以忽略不计(16段足够)。
片上存储。DianNao是片上存储结构可以解释为暂存器(电脑高速暂存记忆区)的修改缓冲器。虽然高速缓存对于大多数通用处理器是一个很好的存储结构,但是由于高速缓存访问开销(tag检查,关联性,行大小,预测读等)和高速缓存冲突,这是提高重用的次优方法。在专用加速器的暂存器实现了两全其美:高效存储,以及高效和轻松利用局部性,因为只需手动调整少量算法。
DianNao将片上存储分成三个结构(NBin,NBout和SB),因为有三种类型的数据(输入神经元,输出神经元和突触)具有不同的特征(读取宽度和重用距离)。这种拆分结构的第一个好处是将SRAM定制到适当的读/写宽度,拆分存储结构的第二个好处是避免冲突,就像在缓存中一样。此外,实现三个DMA来利用数据的局部性,每个缓冲区一个(两个load DMA用于输入,一个存储DMA用于输出)。循环分块
DianNao利用循环分块来最小化内存访问,从而有效地适应大型神经网络。为了简单起见,这里我们只讨论一个具有Nn个输出神经元的分类器层,它完全连接到Ni个输入。在图5给出了分类器的原始代码,以及分块后代码。
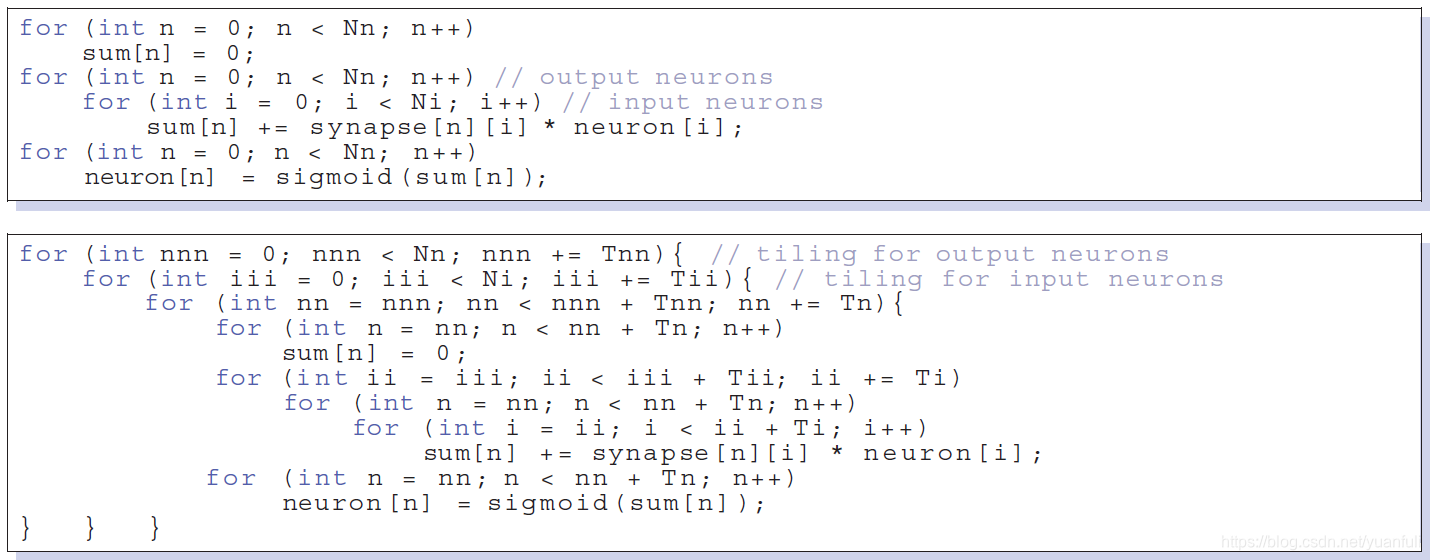
在分块代码中,循环ii和nn反映了上述事实,即NFU是Ti输入/突触和Tn输出神经元的功能块。另一方面,输入神经元被重新用于每个输出神经元,但由于输入神经元的数量可以在几十到几十万之间任何范围,它们通常不适合DianNao的NBin大小。因此,我们进一步使用分块因子Tii来分块循环ii(输入神经元)。分块的一个典型折衷是,改进一个引用(这里指输入神经元的neuron[i])会增加另一个引用(sum[n]是输出神经元的部分和)的重用距离,所以我们还需要分解第二个引用,因此循环nnn和循环分块因子Tnn是为了计算神经网络部分和。层的内存行为现在主要由突触支配,在分类器层,所有的突触通常是独一无二的,因此在层内没有重用。总的来说,分块大大降低了分类器层的总的内存带宽需求,在实验中发现降低了约50%。实验结果
首先实现了一个自定义周期精确、位精确的加速器C++模拟器。该模拟器也可以用来测量一些周期的时间,它是插在主存模型上,允许带宽高达250GB/s。还实现了加速器的Verilog版本,它使用Tn=Ti=16(即16个硬件神经元,每个神经元16个突触),因此该设计包含256个16位截断乘法器在NFU-1(用于分类器和卷积层);在NFU-2中有16个加法树,每个加法树15个加法器,以及一个16输入移位器和取最大值(用于池化层)在NFU-2;在NFU-3中还有16个16位截断乘法器和16个加法器(用于分类器和卷积层,也可用于池化层)。对于分类层和卷积层,每个周期NFU-1和NFU-2都是有效的,每个周期可以实现256+16*15=496个定点运算,当频率为0.98GHz时,这相当于452GOP/s。使用Synopsys工具在65nm工艺上完成了加速器的综合和布局,见下图。
更多的实验结果见原论文或者神经网络加速器文档!
加粗样式
DaDianNao
基本信息
- 论文名称:DaDianNao: A Machine-Learning Supercomputer
- 作者:Yunji Chen, Tianshi Chen,Zidong Du
- 发表时间:MICRO, 2014.
主要内容:
在ML社区中,神经网络存在着越来越大的显著趋势。Krizhevsky等人最近的工作在ImageNet数据集上实现了很高的准确度,有将近6000万的参数,最近有一个10亿参数的神经元例子[7]。尽管DianNao可以在不同的尺度上执行神经网络,但是为适应大型神经网络,它必须将神经元和突触值存储在主存储器中,频繁的主存访问极大地限制了DianNao的性能和能效。
如果从ML的角度来看,10亿个参数或更多参数的模型会大量出现,重要的是我们需要意识到,它不是从硬件的角度来看:如果每个参数需要64位,那么只对应8G(并且有明确的迹象表明较少的比特就足够了)。虽然单个芯片的8G仍然太大,但可以想象一个由多个芯片组成的专用ML计算机,每个芯片包含专用逻辑和足够的RAM,所有芯片的RAM总和可以包含整个神经网络,不需要主存。
架构
在大型神经网络中,基本问题是两种类型层突触的存储(用于重用)或带宽需求(用于获取):具有私有内核的卷积层和分类层(通常是全连接,因此有很多突触)。在DaDianNao中,通过采用以下设计原则来解决这个问题:(1)创建一个架构,其中突触总是存储在靠近神经元的位置,这些神经元将使用它们,最大限度地减少数据的移动,节省时间和能量;架构是完全分布式的,没有主存;(2)创建一个不对称的结构,其中每个节点占用的空间都大量偏向于存储而不是计算;(3)转移神经元值而不是突触值,因为前者在上述层中比后者少几个数量级,需要相对较少的外部(跨芯片)带宽;(4)通过将本地存储分解为多个区块来实现高内部带宽[8]。
DaDianNao的一般体系结构是一组节点,每个芯片一个全部相同,以经典的网状拓扑排序。每个节点包含大量存储,特别是用于突触和神经计算单元,为了与DianNao加速器的一致性,称之为NFU。这里简要介绍节点架构的一些关键特性。
基于分块的组织。当NFU具有中等面积时,将所有功能单元(如加法器和乘法器)放在一个单独的计算块(NFU)中是可以接受的设计选择,这就是DianNao的情况。但是,如果显著扩大NFU,NFU和片上存储之间的数据移动将需要非常高的内部带宽(即使拆分片上存储),导致不可接受的大布线开销。为解决这个问题,在每个节点中采用基于区块的组织,参见图10。每个区块包含一个NFU和四个RAM组,用于存储神经元之间的突触。
当容纳神经网络层时,输出神经元在不同区块中展开,使得每个NFU可以同时处理16个输入神经元和16个输出神经元(256个并行操作)。所有的分块通过胖树连接,胖树用于将输入神经元值广播到每个分块,并从每个分块收集输出神经元值。结果,对于广播到所有区块的每组输入神经元,在同一硬件神经元上计算多个不同的输出神经元。这些神经元的中间值被保存在本地区块RAM中,当输出神经元完成计算时(所有输入神经元被考虑在内),该指通过胖树发送到芯片中心,最后发送到中央RAM库.
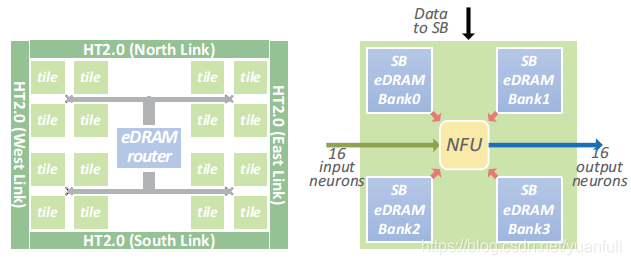
存储。在一些最大的已知神经网络中,层所需的存储大小通常在1MB到1GB范围内,其中大多数在几十MB范围内。虽然SRAM适用于缓存的目的,但它们对于如此大规模的存储还不够密集,已知eDRAM具有更高的存储密度。例如,10MB的SRAM存储器在28nm工艺下需要20.73〖mm〗2,而相同存储和相同技术节点的eDRAM存储器需要7.27〖mm〗2,即存储密度高2.85倍。在每个DaDianNao节点中,实现了16个区块,所有区块都使用eDRAM作为其片上存储。每个分块有四个eDRAM存储区(见图10),每个存储区包含1024行4096位,因此一个分块的总eDRAM容量为4*1024*4096=2MB。每个节点中的中央eDRAM大小为4MB,因此,总节点eDRAM容量是16*2+4=36MB。
互连。因为神经元是唯一传递的值,并且这些值在每个节点内被大量重用,所以通信量虽然很大,但通常不是瓶颈。因此并没有开发定制的高速互连,而是转向商用高性能接口,使用HyperTransport(HT)2.0 IP模块。 多节点DaDianNao系统使用简单的2D网状拓扑,因此每个芯片必须通过四个HT2.0 IP块连接到四个邻居。实验结果
作者实现了一个自定义周期精确、位精确的C++模拟器,用于DaDianNao架构的性能评估,还实现了DaDianNao的Verilog版本,并在28nm工艺下完成综合和布线(节点布局见图11)。芯片的时钟频率为606MHz,占用面积为67.73〖mm〗^2,峰值性能为5585GOP/s。在最大的神经网络层样本中,发现单个DaDianNao节点的速度比NVIDIA K20M GPU高出21.38倍,平均能耗降低330.56倍;64节点系统的速度比NVIDIA K20M GPU高出450.65倍,平均能耗降低150.31倍.

Cambricon-S
基本信息
- 论文名称:Cambricon-S: Addressing Irregularity in Sparse Neural Networks through A Cooperative Software/Hardware Approach
- 作者:Xuda Zhou,Zidong Du,Yunji Chen
- 发表时间:MICRO, 2018.
主要内容:
随着神经网络模型的拓扑结构朝着规模不断扩大,层数不断加深方向发展,庞大的数据和计算量给传统计算平台带来巨大挑战。虽然采用稀疏技术(包括神经元和权值稀疏)能够有效减少神经网络的参数,从而减少数据访问和计算量,但是它同时会将稠密网络规则的拓扑结构转化为稀疏不规则形式,从而阻碍处理平台(包括CPU、GPU和专用加速器)充分利用神经网络稀疏特性获得性能的提升。
基于大量实验,观察到了局部收敛的现象,即在训练过程中,权值的分布不是随机的,较大的权重往往会聚集成簇。基于这个关键的观察,作者提出粗粒度剪枝大幅降低稀疏神经网络的不规则性,即将多个突触作为一个整体进行裁剪,而不是裁剪单个突触。并进一步设计了一个新型硬件加速器,Cambricon-S,用于有效处理剩余的稀疏神经元和突触的不规则性[9]。
压缩方法
为了减少神经网络参数规模,从而减少对存储资源,计算资源和带宽的需求,加快神经网络运行速度,降低神经网络能耗,我们首先进行权值编码来压缩权值数据,具体过程见图12,它由量化和熵编码两个步骤组成。量化是将连续取值或大量可能的离散权值近似为有限多个离散值的过程,量化能减少表示神经网络参数的比特数,当权值比特数为t位时,权值可能取值为2^t个。在量化过程总,利用聚类算法(K-means)将分散的权值聚集成K个簇,其中值相近的权重将会被聚成一个簇。熵编码即编码过程中按熵原理不丢失任何信息的编码,因此它是一种无损压缩的编码技术,作者使用的是哈夫曼编码[10]。
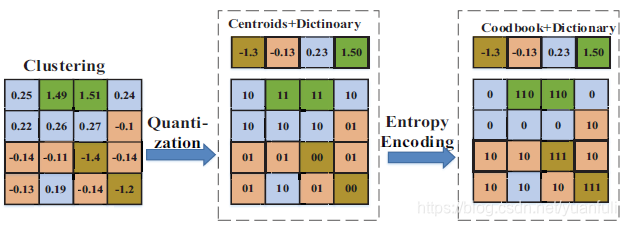
压缩神经网络流程包括三个步骤:粗粒度剪枝、局部量化和熵编码。粗粒度剪枝的核心思想基于神经网络权值局部收敛特征,将多个突触聚成的簇进行剪枝操作,而不是对单个权值进行剪枝。由于训练过程中,绝对值较大的权值倾向于聚集成簇,重点保留那些拥有大量较大权值的簇,裁剪那些只有少量较大权值的簇,从而在粗粒度裁剪过程中保持神经网络的表征能力。局部量化策略先将权值矩阵划分为两个子矩阵,然后对两个子矩阵分别进行聚类,每个子矩阵权值将被编码成一个密码本和一个字典。局部量化能够利用局部收敛进一步减少表示权值的比特数,从而获得更高的压缩比。熵编码为输入中每个符号创建并分配唯一无前缀码,实验显示,熵编码能够进一步减少20%~30%的网络存储开销。
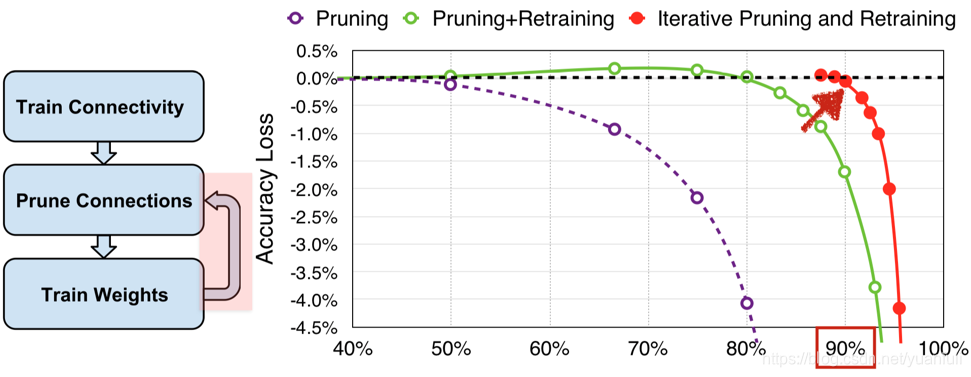
由于粗粒度剪枝和局部量化后会导致神经网络的精度下降,所以需要对神经网络进行重训练,保证神经网络的精度。从图13可以看出随着剪枝神经网络精度逐渐下降,但是通过迭代剪枝和重训练过程,发现可以保障精度不损失的情况下进行大量的剪枝。 .
整体架构
加速器的逻辑架构有四个部分组成,如图14所示,分别是稀疏处理模块,存储模块,控制模块和片上互联模块。
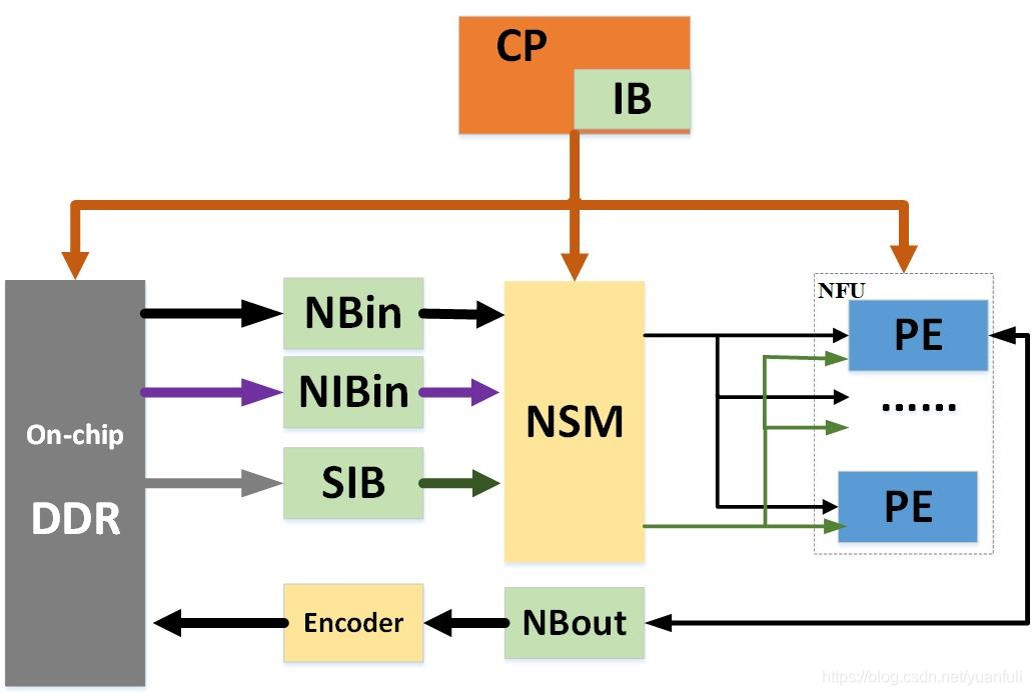
稀疏处理模块包括神经元选择器模块(NSM),神经功能单元(NFU)和动态神经元压缩模块(Encoder)。NSM用于处理静态稀疏和共享信息(包括共享索引信息和神经元信息)。NFU用于完成神经网络中的核心计算,NFU中具有多个处理单元(PEs)用来并行计算不同的输出神经元,每个PE都包含一个本地的突触选择器模块(SSM)来处理动态稀疏性。Encoder用于动态地将输出神经元压缩成为非零元素/非零元素索引的模式,从而减少Loa/Store神经元的开销。
存储模块需要存储输入神经元,权值和输出神经元,因此我们需要输入神经元缓存(NBin),输出神经元缓存(NBout)和突触缓存(SB),考虑到神经元和权值的稀疏性,我们需要两个额外的缓存,即输入神经元索引缓存(NIBin)和突触索引缓存(SIB)分别存储输入神经元索引和突触索引信息。注意,其中SB被内置在NFU的每一个PE中,没有体现在图中。
控制模块由控制处理器(CP)和指令缓存(IB)组成,CP有效地将IB中存储的各种指令解码为所有其它模块的详细控制信号,将CP设计为一个多发射的控制器,从而挖掘访存与计算之间的并行性,进一步提升加速器的性能。
最后采用H树的拓扑结构连接NSM和NFU中的T_n个PE,以缓减片上网络拥堵,减少数据传输的延迟。实验结果
在当前加速器中,为了兼容剪枝块的大小,将PE的数量T_n以及每个PE内部乘法器数量T_m配置为T_n=T_m=16,同时考虑到神经网络神经元和权值的稀疏度,将NSM设计为256选16的结构,SSM设计为64选16的结构,Encoder设计为64选16的结构。
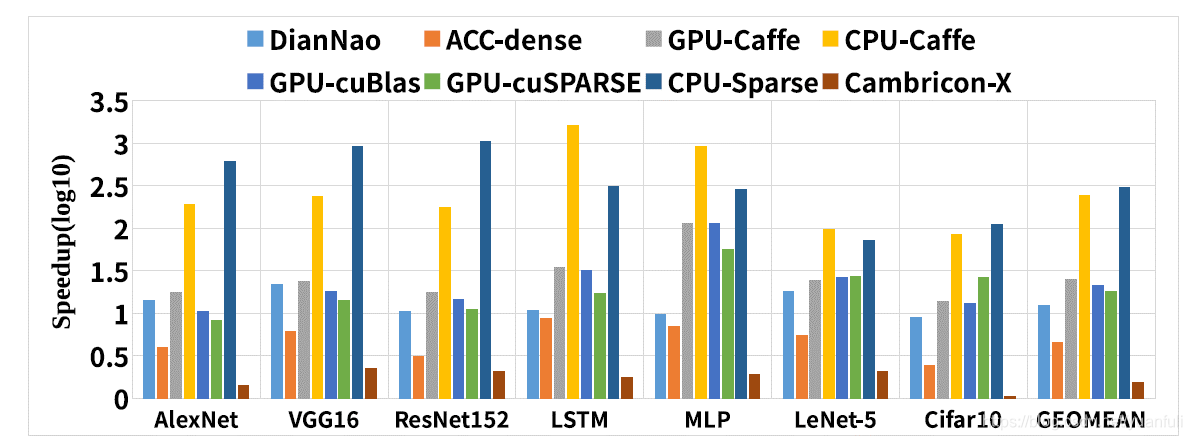
在性能上Cambricon-S和CPU,GPU,DianNao,Cambricon-X[11]进行了对比,同时评估稀疏神经网络和稠密神经网络的性能,使用稀疏库(CPU-Sparse,GPU-Sparse)评估稀疏神经网络的性能,使用稠密库(CPU-Caffe,GPU-Caffe,GPU-cuBLAS)评估稠密神经网络性能,为了与CPU和GPU公平比较,评估加速器在稠密网络上的性能(ACC-dense)。
在图15中,比较了Cambricon-S和CPU,GPU,DianNao,Cambricon-X的性能,同时将所有性能的数据归一化到了Cambricon-S的稀疏网络上的性能。在稠密网络上,Cambricon-S与CPU-Caffe,GPU-Caffe,GPU-cuBLAS对比分别获得44.8倍、5.8倍和5.1倍的加速比。在稀疏网络上,Cambricon-S与CPU-Sparse和GPU-Sparse对比分别能获得331.1倍和19.3倍的加速比。对比于DianNao和Cambricon-X,Cambricon-S分别能获得13.1倍和1.71倍的加速比。实验结果充分显示该加速器能够充分利用神经网络稀疏的特性,从而获得高加速比。
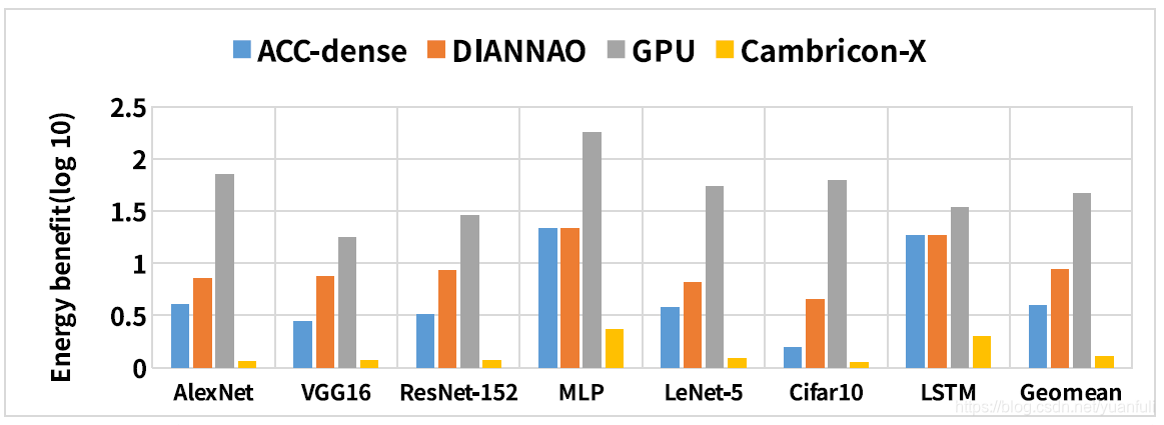
在七个benchmark上,作者又比较了Cambricon-S,GPU,DianNao,Cambricon-X的能耗,其中包括了片外访存的能耗。如图16所示,对比于GPU,DianNao和Cambricon-X,能够分别节约63.49倍,11.72倍和1.75倍的能耗。如果不考虑片外访存的能耗,Cambricon-S分别比GPU,DianNao和Cambricon-X节约1169.51倍,12.30倍和1.75倍能耗。以上实验实验数据证明该加速器能够使用很低的能耗完成神经网络的计算。