如有错误,恳请指出。
文章目录
paper:AS-MLP:an axial shifted mlp architecture
code:https://github.com/svip-lab/AS-MLP

摘要:
AS-MLP更多的关注于局部的特征信息,通过轴向移动特征映射的通道,从不同的轴向方向获取信息流,从而捕获局部依赖关系。作者表示,这样的操作能够利用一个纯粹的MLP架构来实现与类似cnn架构相同的局部感受场。
AS-MLP是MLP-based中第一个用于下游任务的,效果如下:
- 83.3% Top-1 accuracy with 88M parameters
- 51.5 mAP on the COCO validation set
- 49.5 MS mIoU on the ADE20K dataset
1. Introduction
对于MLP结构来说,模型通过矩阵转置与token-mixing投影操作获取全局的感受野,从而覆盖了长距离依赖。但是,从操作上可以看出来,MLP-Mixer比较少地利用了局部信息(局部信息就是cnn的归纳偏置,在构建cnn模型时比较重要),而且也不是所有的像素点都需要长距离依赖(这也vit模型目前被改进的一个方向,长距离依赖就是vit的归纳偏差,现在希望增加局部信息操作来减少参数量,部分论文已经证实了局部信息的重要性及优势),局部信息更多地关注于提取底层特征。为此,作者关注于局部性对MLP架构的影响。
为了将局域性引入到基于mlp的体系结构中,一个最简单和最直观的想法是向MLP-Mixer添加一个窗口,然后在窗口内的特征上对本地信息执行token-mixing projection,就像在Swin Transformer中所做的那样。但是对于基于mlp的体系结构,如果划分窗口(如7×7)并在窗口中进行token-mixing projection,那么只使用49x49linear层,这极大地限制了模型的容量,从而影响了参数的学习和最终的结果。
为此,作者提出了一种基于mlp架构的轴向转移策略,在水平和垂直方向上进行空间转移特征。轴向位移可以将不同空间位置的特征安排在同一位置。在此之后,一个channel-mixing MLP被用来结合这些特征(此时不同的patch信息就进行了交互,进行了信息的融合)。这种方法使模型能够获得更多的本地依赖项,从而提高性能。此外,还能够设计与卷积核相同的MLP结构,例如设计核的大小和膨胀率。
2. Related Work
以下简要介绍vit与mlp-base相关idea相关paper:
2.1 Transformer-based Architectures
- DeiT:仔细设计训练策略和数据增强,以进一步提高小数据集(如ImageNet-1K)的性能
- DeepViT / CaiT:考虑网络深化时的优化问题,训练更深层次的Transformer网络
- CrossViT:使用两个vision transformers组合local patch和global patch
- CPVT:使用条件位置编码来有效地编码patch的空间位置
- LeViT:从convolution embedding、额外non-linear projection和批处理归一化等方面改进了ViT
- Transformer-LS:提出了一个长期注意和一个短期注意模型的长序列语言和视觉任务
- PVT / Swin Transformer / NesT:设计层次骨架,提取不同尺度的空间特征
2.2 MLP-based Architectures
- Res-MLP:仅在ImageNet1K上训练residual MLP
- gMLP:引入空间门控单元Spatial Gating Unit (SGU)来提高纯mlp架构的性能
- EA:引入外部关注External Attention来提高纯mlp架构的性能
- Container:提出了一种综合了卷积、transformer和MLP-Mixer的通用网络
- S2-MLP:使用空间位移MLP进行特征交换
- ViP:提出了一个Permute-MLP层用于空间信息编码,以捕获长期依赖关系
3. AS-MLP Architecture
3.1 Overall Architecture
对于输入大小为3xHxW的RGB图像,划分patch大小为4x4,每个patch的线性投影信息为48,所以token为48x(H/4)x(W/4)。AS-MLP共有四个阶段,不同阶段的AS-MLP block数量不同。所有token都将经历这四个阶段,最后输出的特征将用于图像分类。
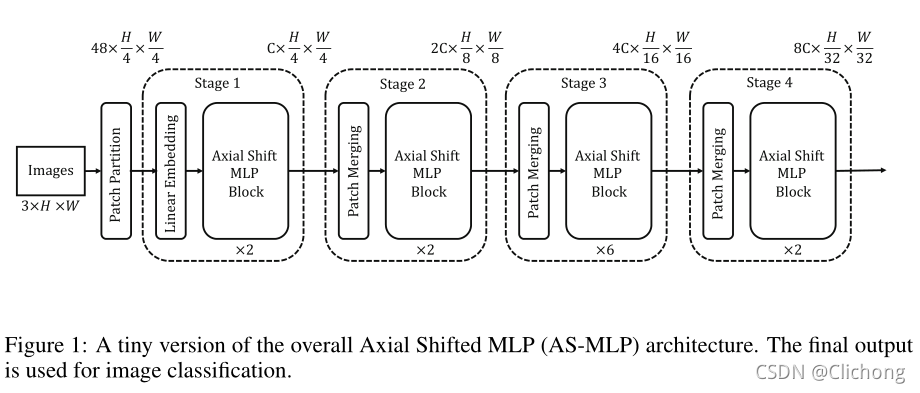
- Step1:与其他的类似,采用一个普通的Linear Embedding将channels为48扩充为C(shape:Cx(H/4)x(W/4))
- Step2:首先对2x2的邻近patch进行融合拼接,也就是变成4Cx(H/8)x(W/8),然后进行线性降维为2Cx(H/8)x(W/8),然后进行AS-MLP block的级联
- Step3、Step4:与Step2类似,层次结构表示将在这些阶段中生成
Tiny version与其他版本不同的地方就是堆叠的数量不同。
3.2 AS-MLP Block
AS-MLP体系结构的核心操作是AS-MLP块,主要由Norm层、Axial Shift操作、MLP和residual connection组成。
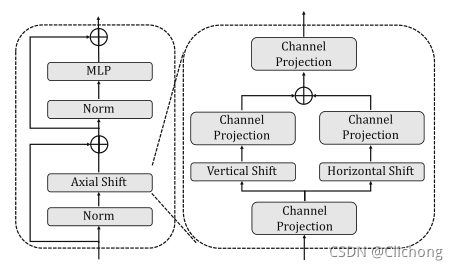
在轴向位移操作中,作者利用通道投影、垂直位移和水平位移来提取特征,其中通道投影将特征映射为一个线性层。垂直移动和水平移动负责特征在空间方向上的平移。
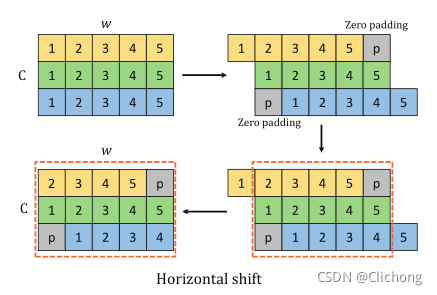
上图以水平移动为例:输入的维度为C×h×w,在图中省略h并假设c = 3,w= 5。当位移大小为3时,将输入特征分割为三个部分,每个部分沿水平方向分别移动{-1,0,1}单位。在这个操作中,执行零填充(用灰色块表示,此外还有其他的填充方式)。之后,虚线框中的特性将被取出并用于下一个channels投影。竖直移动也是类似的,其实本质上就是对channel进行前后左右4个方位进行移动,并且使用0padding进行填充,与S2-MLP是类似的。
与S2-MLP不同的是,在Axial Shift操作中,水平操作与竖直操作构成了一个并行分支,分别进行一个线性投影在重新的组合在一起,也就是多了一个融合的思想,不仅仅是简单的Shift。通过这种操作,来自不同空间位置的信息可以组合在一起。在下一个channel投影操作中,来自不同空间位置的信息可以充分流动和交互。
代码表示为:
#norm:normalizationlayer
#proj:channelprojection
#actn:activationlayer
import torch
import torch.nn.functional as F
def shift(x, dim):
x = F.pad(x, "constant", 0)
x = torch.chunk(x, shift_size, 1)
x = [ torch.roll(x_c, shift, dim) for x_s, shift in zip(x, range(-pad, pad+1))]
x = torch.cat(x, 1)
return x[:, :, pad:-pad, pad:-pad]
def as_mlp_block(x):
shortcut = x
x = norm(x)
x = actn(norm(proj(x)))
x_lr = actn(proj(shift(x, 3)))
x_td = actn(proj(shift(x, 2)))
x = x_lr + x_td
x = proj(norm(x))
return x + shortcut
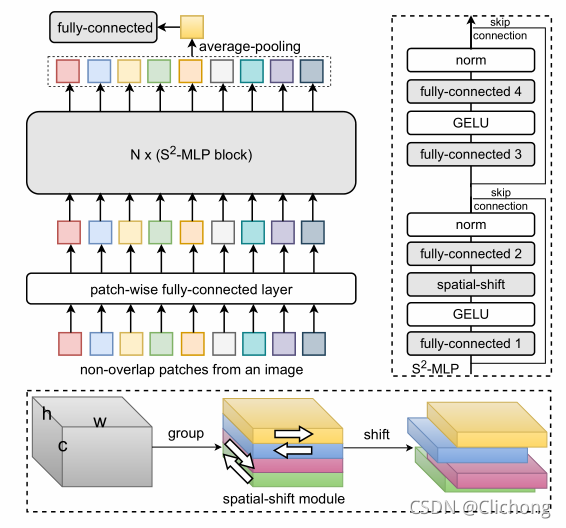
ps:AS-MLP与S2-MLP有点类似,这里附上S2-MLP的结构图:
3. Comparisons
这部分作者将MLP与CNN和Transformer进行了对比。
虽然这些模块的探索路径完全不同,但从计算的角度来看,它们都是基于给定的输出定位点,其值取决于不同采样位置特征(乘法和加法运算)的加权和。这些采样位置特征包括局部依赖(如卷积)和远程依赖。
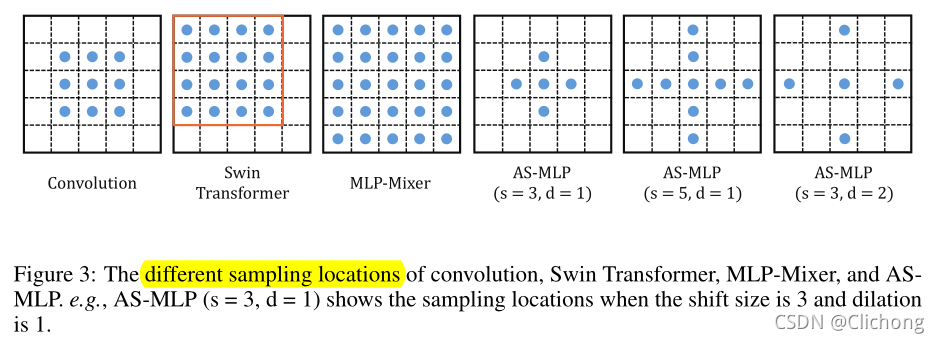
通过轴向移动特征信息,AS-MLP 可以得到不同方向的信息流,这有助于捕获局部相关性。该操作使得我们采用纯 MLP 架构即可取得与 CNN 概念相同的感受野,并可以类似卷积核设置 AS-MLP 模块的感受野尺寸以及扩张因子。下图比较了不同架构模块的感受野范围:
- 传统稠密型卷积的感受野是方状的,是局部依赖;
- Swin 则是在窗口内进行 Self-Attention,感受野在整个窗口内,是局部依赖;
- MLP-Mixer 是全连接层,相当于一个超大型卷积,感受野是整个特征图,是长距离依赖,所以对于局部性特征把握性较差;
- AS-MLP 因为是将水平和竖直方向的移动解耦开,然后进行相加,其得到的是十字形感受野。通过调节感受野尺寸以及扩张因子可以得到不同的感受野。不同设置使得采样位置包含局部依赖与长距离依赖。
4. Result
-
connection types的比较(串行与并行):
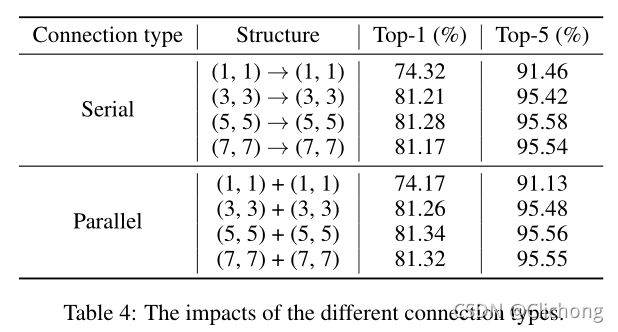
可以看出,对于位移量大于1的部分操作,并行的结果要比串行的结果要好,而对于位移量为1的部分,其实没有太多意义,因为相当于不唯一,完全等同于两个1x1的卷积操作。 -
padding的比较:
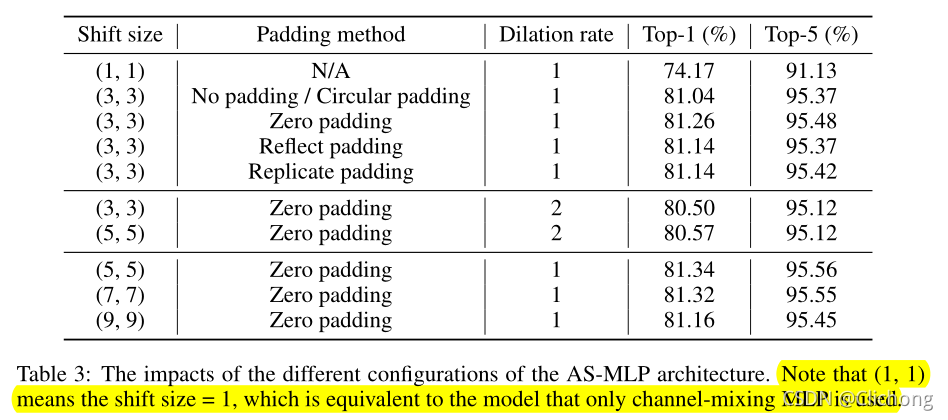
可以看见,对于位移后的填充用zero padding的效果是最好的,而且位移量为5的时候也是效果最好的。
参考其他博客的一些分析:
-
作者采用的转动是暴力的全部转动,水平转动时最左边一列会移动出去,最右边一列会空出来,就造成了一列的信息损失。这时候能够把最左边移动出去的那一列补到右边吗?实际是不好的,因为我们在做图像,且 AS-MLP 对位置是敏感的,图像最左边和最右边不一定有关系,这时候强迫图像最左边和最右边的信息交流不一定能 work。
-
采用 zero-padding 看似会产生信息缺失,实际上在移动的时候是分前中后特征图的,该位置的信息依然可以通过没有移动的中间特征图进行保留。也就是在图像最左边的像素点,它只和它右边的那些像素点进行交流,这是完全 ok 的。至于 Reflect padding 和 replicate padding 其实可被视为在图像最左边的像素点处增加了自己或者右侧像素点的权重(即考虑两次自己和右边像素,或者考虑自己和两次右边像素),这其实意义不大。
-
与其他模型的对比:
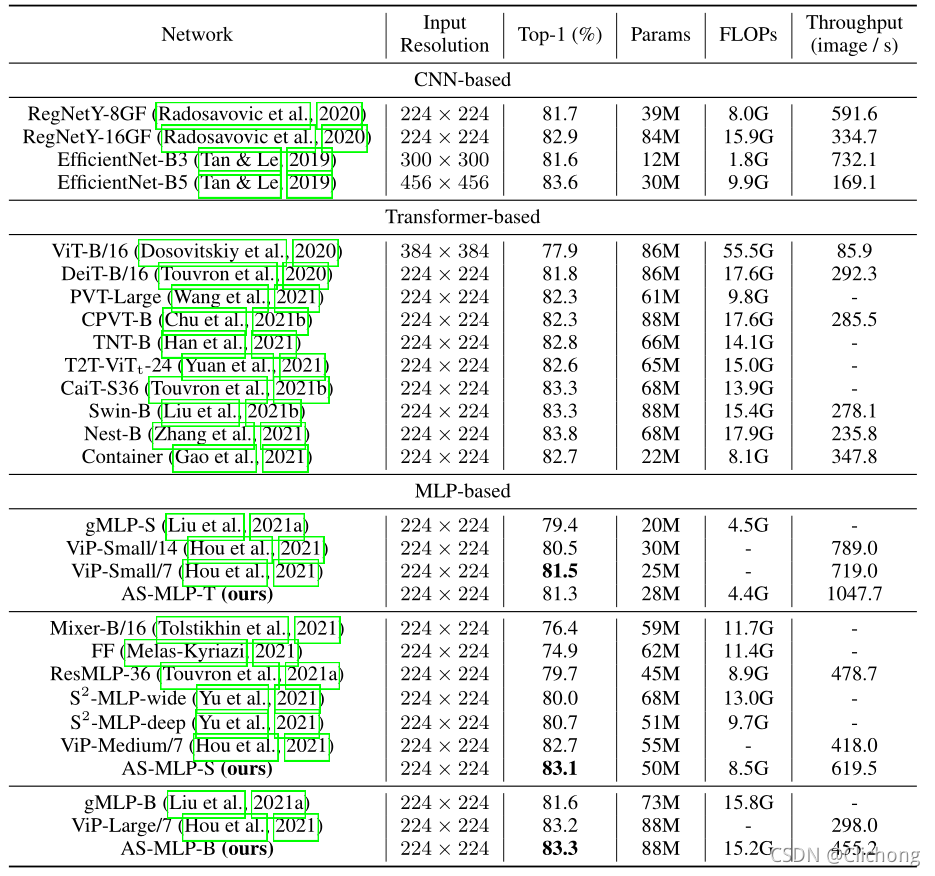
-
为下游任务目标检测性能对比:
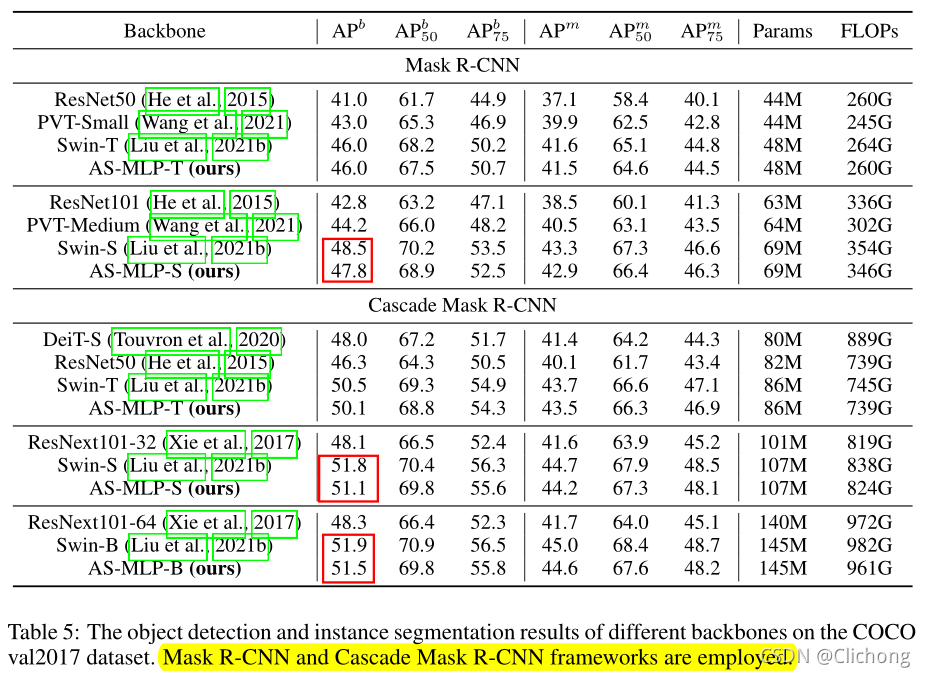
-
为下游任务语义分割性能对比:
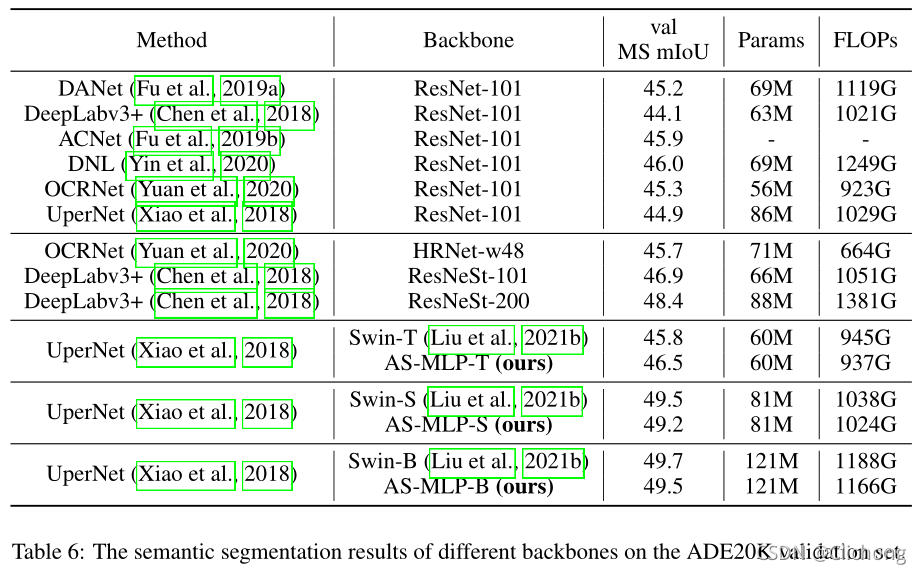
总结:
与MLP-Mixer相比,作者更注重局部特征的提取,提出了一个无参数化的方法对channel信息在水平方向与竖直方向上进行了解耦的信息融合,使得MLP架构拥有与cnn类似的感受野的概念(十字形感受野)。
参考资料:
https://blog.csdn.net/baidu_36913330/article/details/120564606