PVT系列论文阅读笔记,包含PVTv1和PVTv2。
目录
1、 Feature Pyramid for Transformer
3、Linear Spatial Reduction Attention
一、PVTv1
论文:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
ViT适用于处理图像分类任务,但是不适合直接应用到密集预测任务,因为ViT的输出分辨率较低(number of patches)。PVT(Pyramid Vision Transformer)通过巧妙地设计,可以输出高分辨率的特征图,同时引入了SRA(spatial reduction attention)来减少计算量。类似CNN,PVT输出多分辨率特征图,可应用于各类下游任务(语义分割、目标检测等)。
一、引言
ViT已经成功的应用于图像分类任务中,但是无法直接用到语义分割和目标检测等任务中,主要原因有2点:
(1)输出特征图分辨率固定,而且分辨率小;
(2)对于正常大小的图片(例如短边长度800个像素的图片),计算成本相对较高;
为了解决上述的限制,作者提出了PVT(Pyramid Vision Transformer),PVT可以替代CNN 的backbone处理多种下游任务(语义分割、目标检测等),PVT主要包含以下几点改进:
(1)PatchEmbedding生成更多的patch,来得到高分辨率特征图用于下游任务;
(2)类似CNN backbone,随着网络加深减少特征图分辨率,同时减少了计算量;
(3)使用SRA(spatial reduction attention)减少计算量;
二、网络结构
1、 Feature Pyramid for Transformer
类似CNN能够通过不同的卷积步长得到不同尺度的特征图,PVT利用PatchEmbedding中的步长来减少特征图的分辨率。
假设输入特征图的维度为[N, C, H, W], 当PatchEmbedding的patch_size为P,那么输出的特征图维度为[N, C, H/P, W/P],由此可以降低特征图的分辨率。
PatchEmbedding代码如下:
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)2、Spatial Reduction Attention
为了减少Attention的计算量,PVT提出了一个简单有效的方法,假设Q\K\V的维度为[H*W, C],为了减少计算量,引入缩放因子R,将K\V的维度先变为[H*W/, RC],然后通过全连接层变为[H*W/
, C],从而减少了计算量(实现的时候可以用卷积设置卷积核和步长为R,那么可以直接将维度从[H*W, C]变为 [H*W/
, C])。

代码:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1: # 维度衰减比例R
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
3、网络结构
下图为网络的结构,PVT可以得到各不同分辨率的特征图,类似于CNN backbone,PVT可以作为各下游任务的通用backbone。

网络的具体参数如下(R表示Attention的空间衰减比例,N表示num of heads,E表示Transformer模块中mlp的维度扩张比例):

三、实验结果
1、图像分类
PVT在ImageNet-1K数据上的表现。

2、目标检测和实例分割
PVT在coco2017数据集上的表现。

3、语义分割
PVT在ADE20K数据集上的表现。

二、PVTv2
论文:PVTv2: Improved Baselines with Pyramid Vision Transformer
与PVTv1相比,PVTv2做了3点改进:
(1)overlap patch embedding;
(2)前向传播加入卷积层;
(3)进一步减少attention计算量;
一、引言
PVTv1有3个缺陷:
(1)类似于ViT,PVTv1使用non-overlapping patch embedding;
(2)PVTv1的位置编码维度固定,对任意尺寸的输入不友好;
(3)计算量大;
为了改进以上缺点,PVTv2做了以下改进:
(1)Overlapping Patch Embedding;
(2)移除位置编码,在前向传播中加入卷积;
(3)提出Linear Spatial Reduction Attention。
二、网络
通过对PVTv1进行3种改进,可以得到以下提升:
(1)获得图像和特征图局部联系;
(2)可以处理各种分辨率的输入;
(3)和CNN一样的线性计算复杂度;
1、Overlapping Patch Embedding
通过卷积实现overlapping patch embedding,只需要调整卷积核大小和卷积步长即可实现。

2、Convolutional Feed-Forward
位置编码的存在使得网络对不同大小的输入不友好,移除位置编码,同时在前向传播的mlp模块中加入卷积(使用深度可分离卷积减少计算量)来提取像素之间的位置关系信息。

代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., linear=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.linear = linear
if self.linear:
self.relu = nn.ReLU(inplace=True)
self.apply(self._init_weights)
def forward(self, x, H, W):
x = self.fc1(x)
if self.linear:
x = self.relu(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x3、Linear Spatial Reduction Attention
为了减少Attention计算量,提出LSRA(Linear Spatial Reduction Attention),SRA利用卷积减少特征图分辨率来降低计算量,LSRA通过平均池化减少计算量。
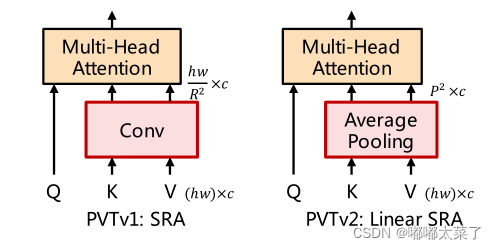
具体计算复杂度如下式:
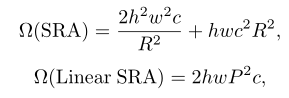
4、网络结构
下表为网络结构,字母含义见下下图。

上图各字母含义:

三、实验结果
1、图像分类
ImageNet-1K分类准确率。

2、目标检测实例分割
coco2017数据集表现如下。
