如有错误,恳请指出。
paper:MLP-Mixer: An all-MLP Architecture for Vision
code:https://github.com/google-research/vision_transformer

摘要:
研究人员表明,尽管卷积和注意力都足以获得良好的性能,但它们都不是必需的。为此,作者提出了MLP-Mixer,一种专门基于多层感知机的体系结构。MLP-Mixer包含两种类型的层:一种是独立于每个patch的mpl结构(既混合每个位置的特征);另外一种是跨越不同patch的mlp结构(既混合空间信息)。
在大数据集上或使用现代正则化方案进行训练时,MLP-Mixer在图像分类基准测试中获得了有竞争力的分数,其预训练和推理成本可与最先进的模型相媲美。
1. Introduction
MLP-Mixer完全基于多层感知机,不需要任何的卷积或者是self-attention操作。其有两种mlp的结构:channel-mixing MLPs与token-mixing MLPs。
channel-mixing MLPs允许不同channel之间进行通信(channel间);token-mixing MLPs允许tokens中的不同空间位置进行通信(channel内)。
2. Mixer Architecture
MLP-Mixer的结构如图所示:
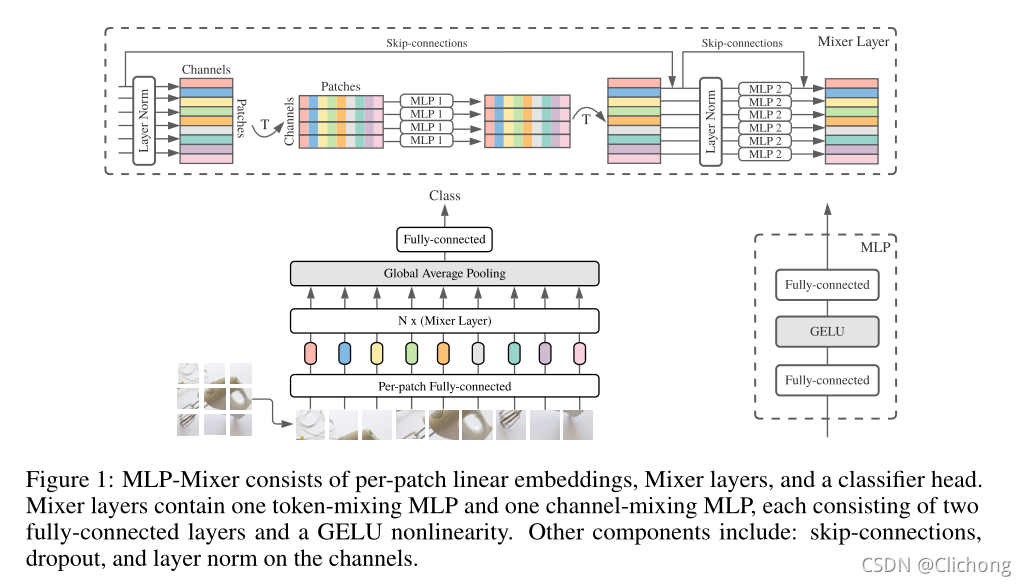
Mixer将不重叠的patch作为输入,每个patch包含了C个维度的信息。假设输入的图像是224x224x3,patch设置大小为7,那么就有32x32个patch,每个patch的维度为7x7x3=147.现在就构成了一个(32x32)x147的二维矩阵。对于矩阵的每一个channel,应用token-mixingMLP,进行32x32个patch的mlp处理;然后应用channel-mixingMLP,进行147个channels的mlp处理。如上图结构的左右两种mlp处理结构所示。
每个Mixer Layer都由以上两种结构组成,其中每一种结构又包含了两层全连接层以及一个非线性激活层。用数学表示为,这里C=channel(147),S=patch(32x32):

网络的复杂度与patch呈线性关系,而ViT的计算复杂度是二次的,所以总体复杂度与图像中的像素数呈线性关系,就像CNN一样。
Mixer中的每一层(除了初始patch投影层)都采用相同大小的输入,除了MLP层,Mixer还使用了其他标准架构组件:skip-connections and layer normalization。与vit不同,Mixer不使用position embeddings,因为token-mixing MLPs对input tokens的顺序很敏感。最后,Mixer使用一个标准的分类头和全局平均池化层,然后是一个线性分类器。
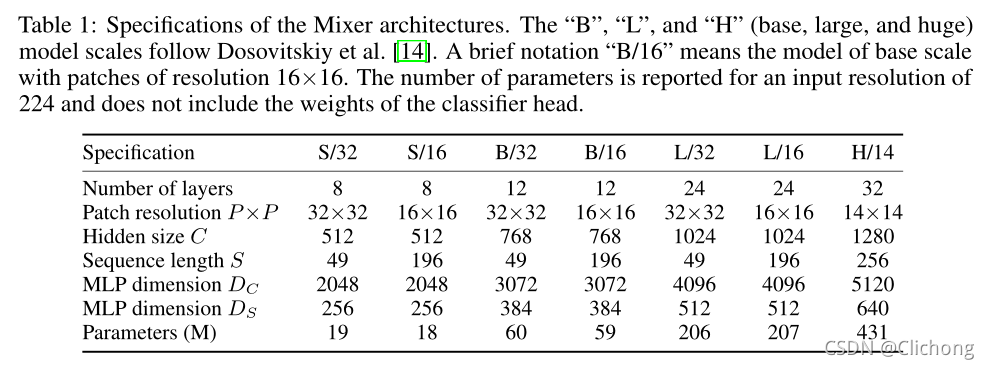
MLP-Mixer配置如下表所示:
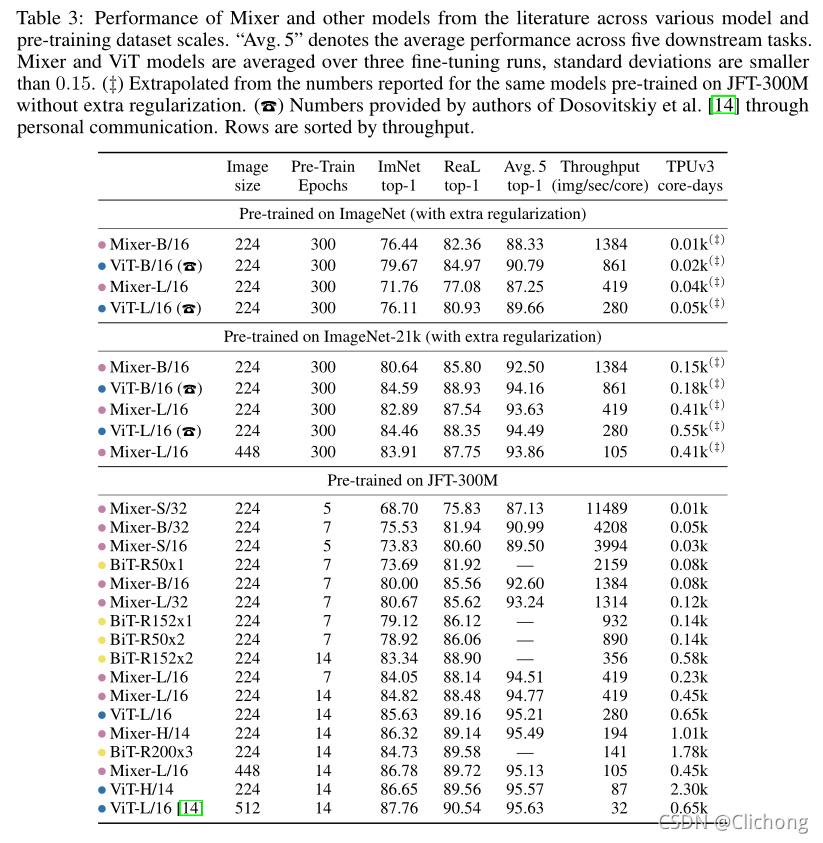
3. Result
- 与SOTA的对比: