我个人其实对NeRF是非常感兴趣的,相比于一些深度学习的文章,NeRF系列在数学公式方面的要求高得多,这也是我投入的一大原因,搞明白数学原理及对应的代码实现非常有成就感。
我之前写了几篇博客,分析的是NeRF原理以及其代码实现,还有Instant-NGP,也用NeRF进行了玩具的三维重建。后来为了补AIGC的内容,搁置了NeRF很久,这篇文章是对各个版本的NeRF进行总结。我也会把我收集到的所有NeRF相关的论文打包上传,方便大家学习。
1、NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
前面两篇论文都是用SDF来进行三维重建的,SDF和NeRF相比有哪些优劣势呢?这就让我联想到了NeuS这篇文章,这篇论文提出了SDF具有更好的表面特征效果,关于SDF、占用场Occupancy Field、NeRF的内容可以参考大佬的博客
浅谈3D隐式表示(SDF,Occupancy field,NeRF)_欧二lord的博客-CSDN博客
NeuS还是遵循NeRF的重建过程,我们来回顾一下NeRF,在下面这篇文章中,我主要是按照代码编写顺序来讲的,对于整体流程没有写清楚
NeRF的输入是一系列带有相机坐标系下位置信息的自然图像,c2w指的是camera坐标系到world坐标系的转换,这些信息可以是拍摄时自带的,也可以是一系列图像通过colmap等图形学预处理得到的。

输入还有两个参数用于表示场景的范围Bounds (bds),是该相机视角下场景点离相机中心最近(near)和最远(far)的距离,所以near/far肯定是大于0的。
这两个值是怎么得到的?是在imgs2poses.py中,计算colmap重建的3D稀疏点在各个相机视角下最近和最远的距离得到的。
这两个值有什么用?之前提到体素渲染需要在一条射线上采样3D点,这就需要一个采样区间,而near和far就是定义了采样区间的最近点和最远点。贴近场景边界的near/far可以使采样点分布更加密集,从而有效地提升收敛速度和渲染质量。
NeRF的输出是由这一系列图像重建得到的三维模型,该三维模型是神经辐射场的隐式表达,这种表达形式可以转换为mesh、点云、体素等显示表达,或者通过体渲染直接生成渲染视频
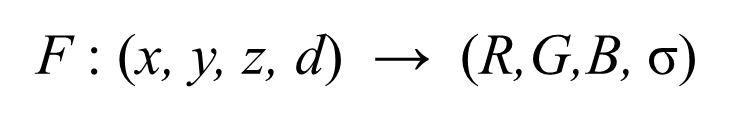
NeRF模型训练时会从这一系列图像中获取图像,对于每张图像上的每个像素点,生成一条射线

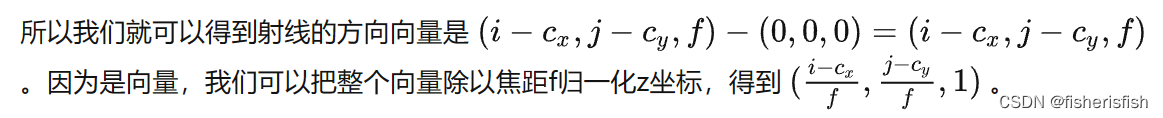
这条射线包含方向信息 rays_d,射线原点信息(相机坐标系的原点,即c2w的平移向量)rays_o,二者结合即可得到一条射线,在这条射线上的near~far范围上随机取采样点,取采样点的原理是体渲染公式
若通过给定pose,从NeRF的模型中获得一张输出图片,关键就是获得每一个图片每一个像素坐标的像素值。在NeRF的paper中,给定一个camera pose,要计算某个像素坐标 (x,y) 的像素。通俗来说,该点的像素计算方法为:从相机光心发出一条射线(camera ray)经过该像素坐标,途径三维场景很多点,这些“途径点”或称作“采样点”的某种累加决定了该像素的最终颜色。
数学上,它的颜色由下面的“体渲染公式”计算而出,其中C表示渲染出的像素点颜色,σ表示体素密度, r 和 d 分别表示camera ray上的距离和ray上的方向,r=o+dt, t表示在camera ray上采样点离相机光心的距离,T表示透射比,也叫光学厚度、介质透明度,c表示当前区域的粒子发光和内散射辐射强度,也就是表面的实际颜色。δi是计算得到的各点之间的步长dists![]()
离散的体渲染公式
![]()
NeRF入门之体渲染 (Volume Rendering) - 知乎 (zhihu.com)
体渲染公式的进一步理解,体渲染公式可以简单总结为下:C(o,v)和C(r),r=o+dt含义一样,代表着以相机坐标为中心,v方向对应在2D投影图上的像素点的颜色信息,C(p(t),v)代表着v方向射线上的点的颜色累加,![]() 实际含义为加权函数,就是每个点颜色累加时应该取哪些点更加重要,哪些点可以忽视,那么这个加权函数是如何构造的呢?
实际含义为加权函数,就是每个点颜色累加时应该取哪些点更加重要,哪些点可以忽视,那么这个加权函数是如何构造的呢?
![]()
其中,σ ( t )是所谓的volume density(传统体积渲染中的术语),而T ( t ) 则表示该射线上所累积的transmittance(透光率),具体有:![]()
至于为什么是这样的?这就要提到体渲染最基本的概念了,体渲染的目的是建模非刚性物体的渲染,体渲染把气体等物质抽象成一团飘忽不定的粒子群。光线在穿过这类物体时,其实就是光子在跟粒子发生碰撞的过程。光与粒子在物理学上发生作用有四类:
- 吸收 (absorption):光子被粒子吸收,会导致入射光的辐射强度减弱;
- 放射 (emission):粒子本身可能发光,比如气体加热到一定程度就会离子化,变成发光的「火焰」。这会进一步增大辐射强度;
- 外散射 (out-scattering):光子在撞击到粒子后,可能会发生弹射,导致方向发生偏移,会减弱入射光强度;
- 内散射 (in-scattering):其他方向的光子在撞到粒子后,可能和当前方向上的光子重合,从而增强当前光路上的辐射强度。

这四个过程可以简单合并成以下公式,从左到右分别代表吸收、外散射、放射、内散射
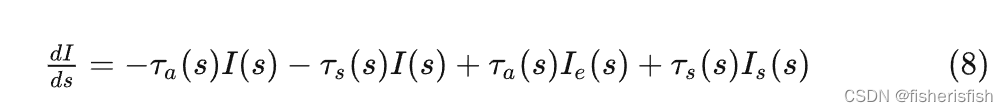
其中,吸收和外散射都会削弱光线的辐射强度,并且由于它们都和入射光有关,因此它们共同构成了体渲染中的衰减项 (attenuation item),而粒子发光和内散射都来自独立的光源,因此被称为源项 (source item)。
在NeRF的体渲染公式中忽略了散射这一过程,所以只有,这就是体素密度
由此定义透射比 (transmittance):

它表示粒子群某一点的透明度,数值越大,说明粒子群越透明,光线衰减的幅度就越小。
这里其实是帮助解释什么是体素密度和透光率,以及这两个物理量是如何影响体渲染的,通过上述物理过程解释了这个问题,体素密度和透光率实际上是对粒子和光之间的物理作用的数学表示,反应了光线穿过粒子后的衰减情况。
综上所述,如果要通过体渲染进行三维重建,那么最关键的就是得到每个点的颜色值,以及对应的体素密度,而NeRF也正是这么做的。
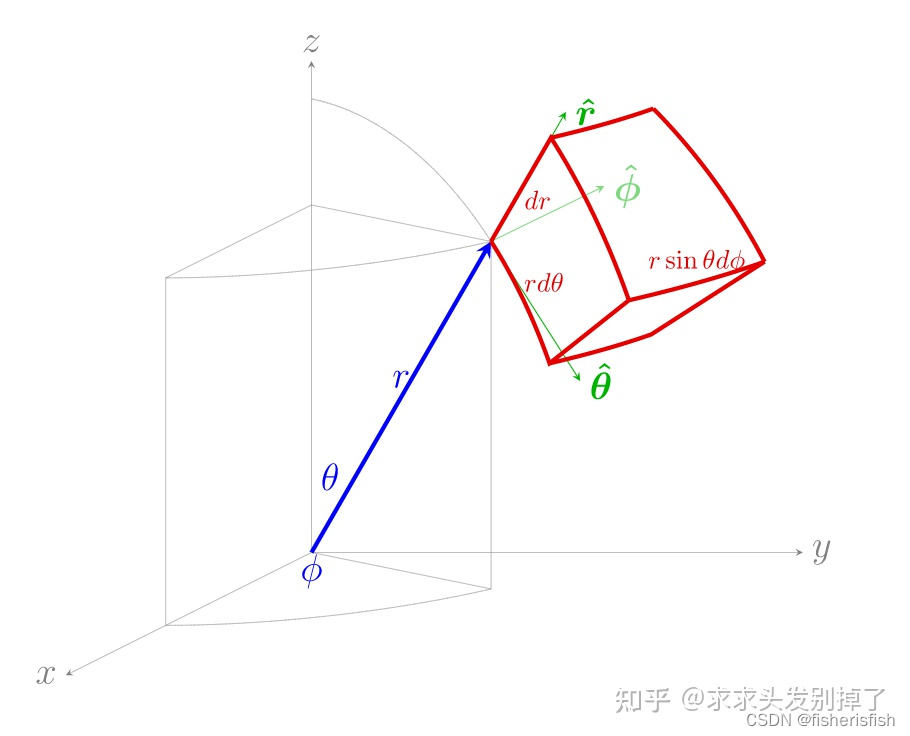
接上NeRF过程,我们在射线上进行采样取点,那么取的这些采样点通过射线计算就可以得到对应的xyz信息,其俯仰角θ,φ信息就是方向射线信息rays_d,具体换算过程可见下图
这两个信息随后会被正余弦编码Positional Encoding,Positional encoding是作者发现让①中的MLP网络(F:(x,d) -> (c,σ))直接操作 (x,y,z,θ,φ)输入会导致渲染在表示颜色和几何形状方面的高频变化方面表现不佳,表明深度网络偏向于学习低频函数。因此在将(x,y,z,θ,φ)输入传递给网络之前,使用高频函数将输入映射到更高维度的空间,可以更好地拟合包含高频变化的数据。这段话的核心含义是空间点的输入差异太小了,所以放大到高维空间,扩大它们之间的差异,从而使得重建结果能够区分很相近的点的差异,具体效果可以看实验结果图

[NeRF坑浮沉记]思考Positional Encoding - 知乎 (zhihu.com)
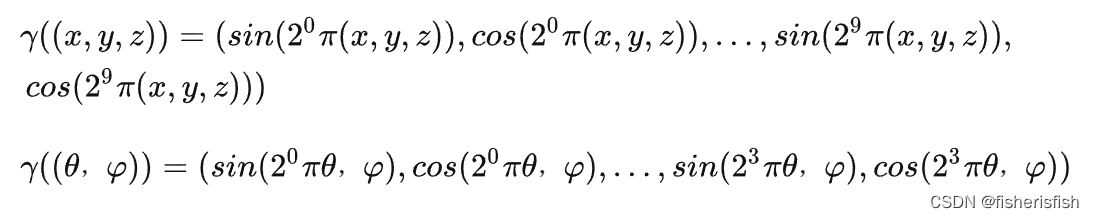
再经过MLP预测rgbα,每个点都会有对应的rgb和密度值,再利用体渲染公式就可以得到最后的输出图像了
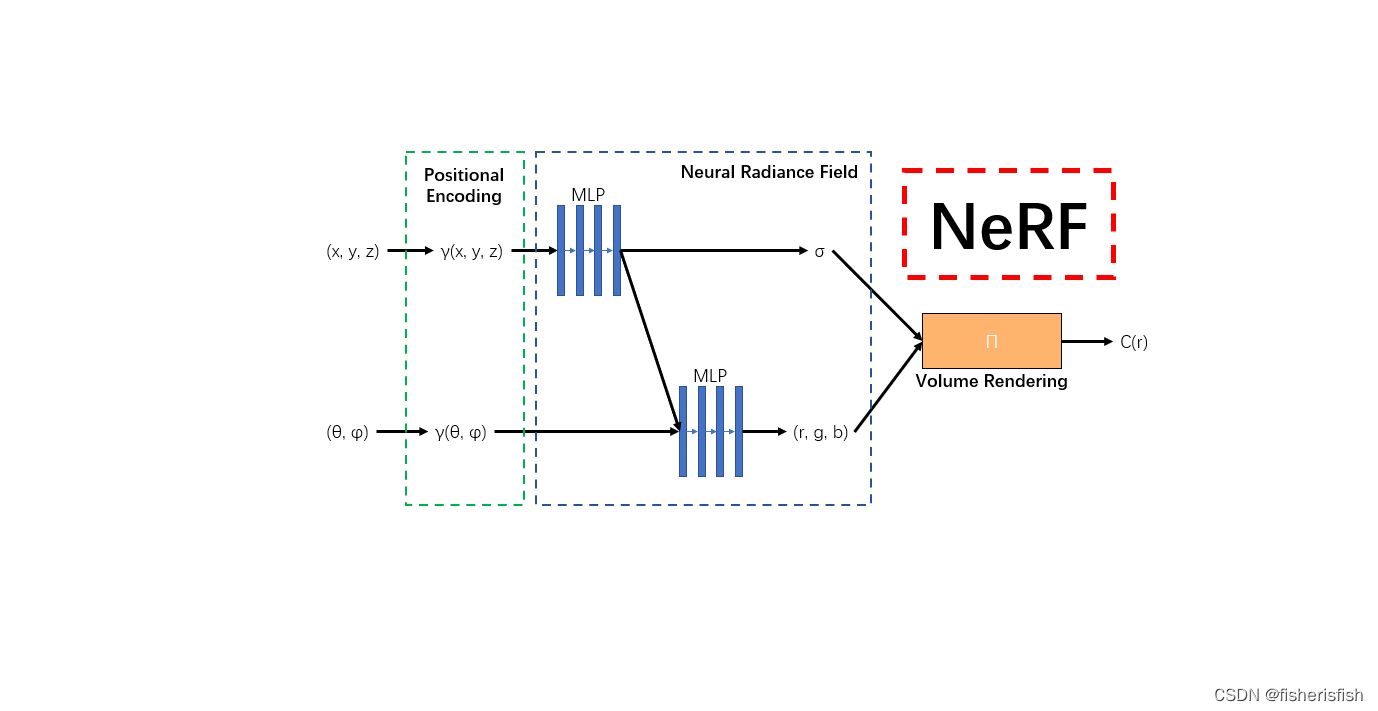
网络输出通过体渲染得到输出图像的过程在我的文章中有了详细的介绍
最后再计算输出图像和输入图像的MSE损失函数,优化MLP网络,得到更好的NeRF表达,这就是NeRF三维重建的全过程了
再回到NeuS这篇文章,其输入和NeRF是一样的,本文发现IDR无法应对图片中深度突然变化的部分,这是因为它对每条光线只进行一次表面碰撞(下图(a)上),于是梯度也到此为止,这对于反向传播来说过于局部了,于是困于局部最小值,如下图IDR无法处理好突然加深的坑。NeRF的体积渲染方法提出沿着每条光线进行多次采样(上图(a)下)然后进行α合并,可以应对突然的深度变化但NeRF是专注于生成新视点图像而不是表面重建所以表面有明显噪声。

NeuS面向多视点表面重建任务,使用SDF描述表面,并用一种新的体积渲染方法训练SDF描述。给出3D图像的多视角图片,想要构造其表面,这个表面由一个神经隐式SDF的零级集合表示。也就是说SDF相比于NeRF可以更好地表述模型表面情况,这在直观上也很好理解。
那么问题就是如何连接SDF和NeRF,或者说如何将SDF融入到NeRF当中
NeuS的做法是将体渲染中体素密度σ(t)这个概念替换成SDF表达,体素密度σ在原来的NeRF中是由MLP预测而来的,下式为NeRF体渲染的原始公式和NeuS中体素密度σ的新计算公式

SDF表面的数学表达,这是SDF的基础内容
![]()
与体渲染引入的粒子密度类似,作者也引入一个概率密度函数:ϕs(f(x)),将其命名为S-density,并选择逻辑斯蒂概率密度分布函数,其原因是计算简单,作者提出S的密度函数可以是任意以 0 为中心的钟形分布函数,这应该是有数学证明的,我后面看懂了再补充。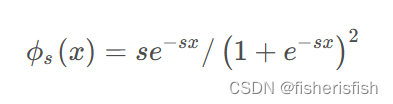
ϕ s的标准差为1 / s,我们不妨令其作为可训练的参数,那么根据梯度下降的原则来看,当1 / s 趋向于0的时候,网络的训练就会收敛,同时也意味着,pdf在射线上的某个空间点上达到了峰值。
作者将新的 σ定义为如下,结合体渲染的理解,体素密度现在变成了表面SDF的概率密度,那么加权的W(t)也应该发生变化。
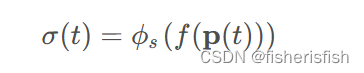
作者也提出了这个问题,作者还对加权函数做出了要求,我们期望这个加权函数能够有以下的性质:
1. 无偏,保证射线与表面交点处贡献是最大的。
2. 对遮挡有所感知,两个点有着相同的SDF数值时,距离观测视角更近的点,应当有着更大的贡献。换句话说,这也就保证了当射线穿越多个表面的时候,渲染过程应该尽可能地去使用射线所遇到的第一个表面交点所带来的颜色。
而原有的加权函数就不适合SDF的概率密度函数了,该方案虽然实现了“遮挡感知”,但是并不能实现“无偏性”。这是因为射线在到达表面之前加权函数就达到了最大值

直接方案(无偏、但不能感知遮挡)。先介绍一种过渡方案,使用归一化的S密度函数来作为权重。

该函数直接由ϕ s来决定,显然是“无偏”的,然而并不能实现“遮挡感知”。试想一下,如果一条射线上存在两个表面,两者的 SDF 值一样,那么两者的权重 w也是相等的。最终渲染颜色时,两个表面会产生同样的贡献,这与现实是不符的。
NeuS方案,还是从加权公式出发,作者用取代了

考虑一种简单情况:即只有一个表面交点且表面是平面。在这种特殊情况下,我们很容易地知道sdf有以下的关系:
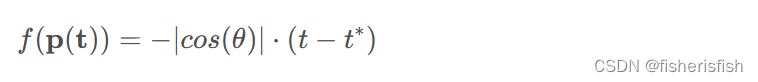
其中,θ是视角方向v与表面法向n之间的夹角。
对应一个固定表面的射线来说θ是固定的,那么根据直接方案可得

也就是![]()
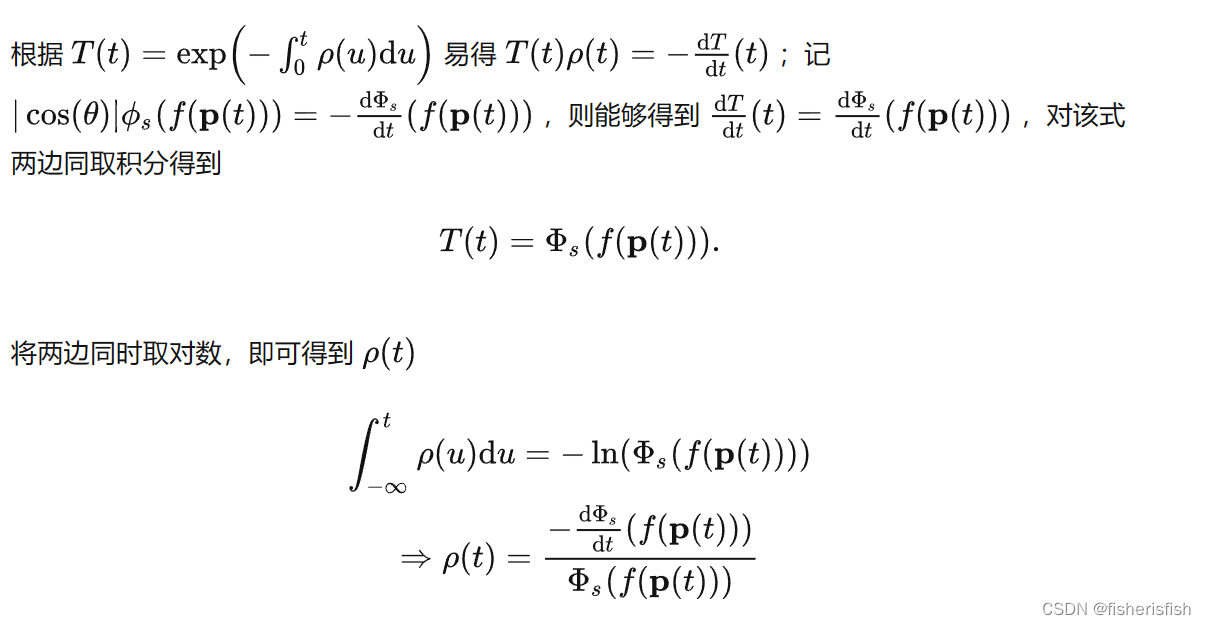

这个式子是符合要求的

离散化结果

非常牛逼的一篇文章,将SDF引入到了NeRF当中,提出了基于SDF的体渲染公式。这篇文章应该整理在NeRF合集当中。
2、Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
神经辐射场(NeRF)使用的渲染程序是以每个像素一条光线对场景进行采样,因此当训练或测试图像以不同分辨率观察场景内容时,可能会产生过度模糊或混叠的渲染效果。对于 NeRF 来说,通过每个像素多条光线渲染来实现超采样的直接解决方案是不切实际的,因为渲染每条光线都需要查询多层感知器数百次。
我们的解决方案被称为 "mip-NeRF",它将 NeRF 扩展为以连续值标度表示场景。mip-NeRF 通过有效地渲染反锯齿锥形顿挫而不是射线,减少了令人反感的锯齿伪影,显著提高了 NeRF 表现精细细节的能力,同时速度比 NeRF 快 7%,体积只有 NeRF 的一半。与 NeRF 相比,mip-NeRF 在 NeRF 数据集上的平均错误率降低了 17%,在我们展示的具有挑战性的多尺度变体数据集上的平均错误率降低了 60%。
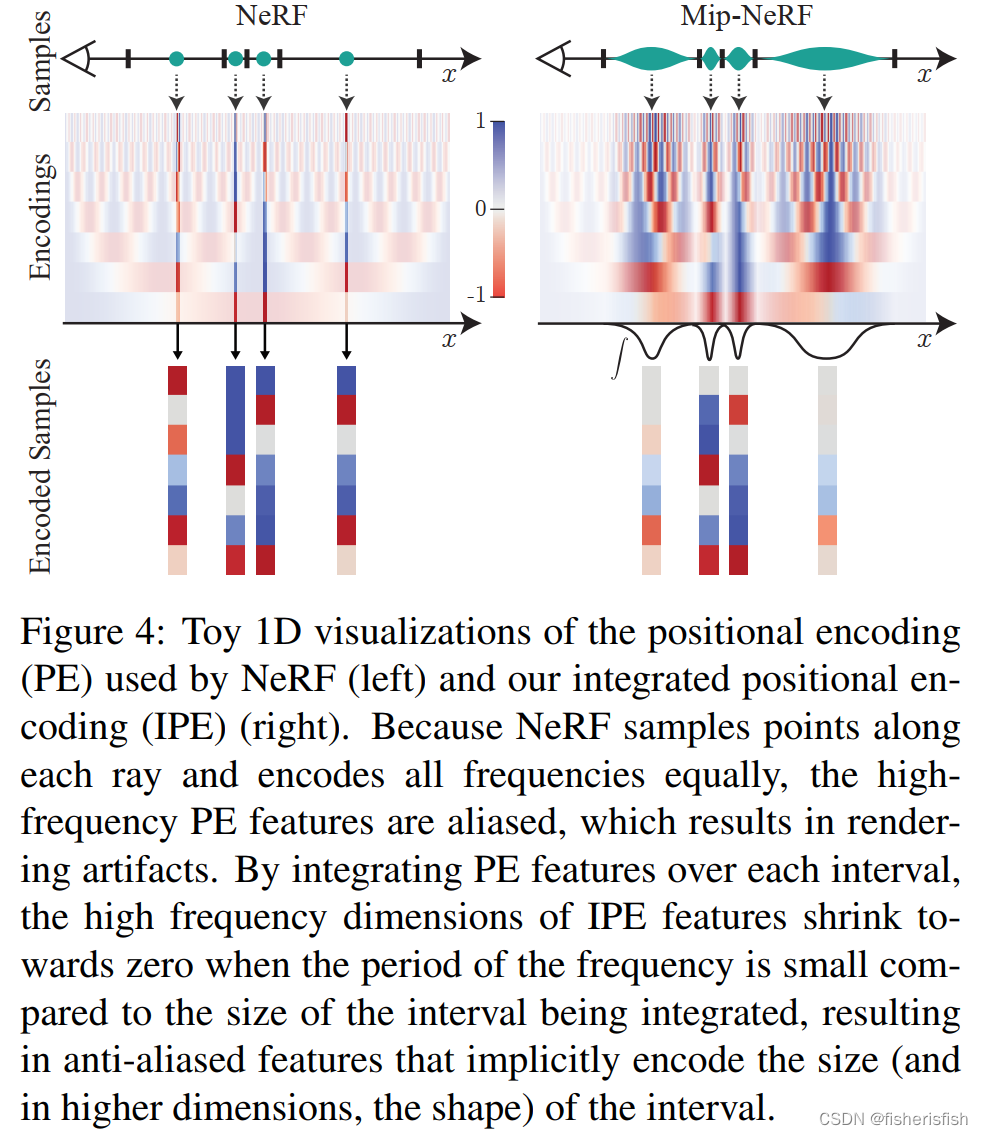
这里我们再次回顾一下NeRF的采样策略,一个相机点O到渲染图像上的点射出一条射线o+td,然后在这条射线的最近和最远点上进行均匀的随机采样(xyz,dir)。而mip-NeRF将采样策略换成了渲染图像上的一个圆区域,那么从相机点出发就变成了下图b中的圆锥形态,这样子采样带来的变化是什么?

我们原来在o+td上采样得到的是射线上的一系列单点,而在圆锥面上采样,就不是单点了。那么原来的NeRF使用 Positional Encoding来处理单点信息,mip-NeRF则提出了integrated positional encoding处理圆锥面采样。此外还有一点改变在于将原来的coarse和fine双阶段生成,集成到一个MLP网络上,同时完成fine的生成,加速了模型,虽然从流程图上看差不多,含义是mip-NeRF的coarse和fine可以采用同样的模型权重,而在NeRF里则是不同的。


上图分别是NeRF和Mip-NeRF在NeRFstudio中的流程图。
uniform sampler指的就是从射线上均匀采点。The Probability Distribution Function (PDF) Sampler生成符合给定分布的样本。
这里我们再回顾一下NeRF的Positional Encoding
Positional Encoding的核心动机了:让原本相似的输入别那么相似了。设想辐射场中距离很近即采样向量很相似的两点,输出具有相似的颜色和密度直觉上是合理的。对于两个很近的点,导数决定了这两点的输出能够有多大的差异,如果相近的点的输出难以拉开差距,那么渲染结果就倾向于模糊、平滑,也就是图像处理常提到的低频信号,反之如果想实现结果高频信息足够清晰,则需要模型能对相近点的输出差异较大,对应较大导数。
所谓不相似就是距离远一些,那么Positional Encoding的要求就是将原本输入的近距离的点的信息映射到高维空间,并且目标是尽可能远一点,那么新空间分布应该尽量满秩,不然就浪费维度了,另外为了方便,映射出的新向量分量正好是正交基就好了。所以NeRF的Positional Encoding将原始输入映射为傅里叶特征

然后我们再回顾一下Coarse-to-Fine 策略
动机是优化采样点的分布,平均采样能用但肯定不是最好的,所以NeRF论文里提出了Hierarchical Sampling(分层采样,多轮采样),第一轮可以使用预定义的采样器(即均匀采样器)生成图像。一旦对空间进行了采样,我们就能知道哪些采样对最终颜色有贡献。我们可以利用这一信息,使用 PDFSampler 对这些区域进行更多采样。也就说我们用不同的采样策略得到了不同的信号,使用同一个MLP处理效果不好。
最后再来学习本文的integrated positional encoding,我们需要关注它是如何实现圆锥采样,以及为何它可以不用Coarse-to-Fine 策略,直接两个NLP使用相同的权重?
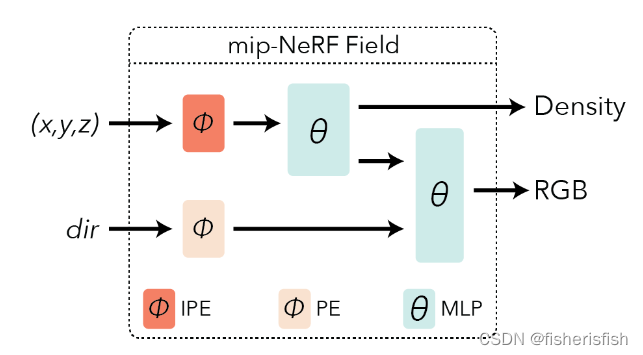
要搞明白一个组件,我们首先需要搞明白输入和输出是什么,从流程图里可以看出IPE针对的是从圆锥采样得到的点X的position(x,y,z)

以上图t0-t1的采样区域为例,其中 X的position作者用了下面这个公式来表达
 这个式子其实简单理解就是在圆锥区域内的点的position(x,y,z)通过这个式子计算结果就是1,其他点就不是1.
这个式子其实简单理解就是在圆锥区域内的点的position(x,y,z)通过这个式子计算结果就是1,其他点就不是1.
区别在于NeRF是直接射线上的点,就一个值,但现在变成了一系列用上面公式表达的点,我们需要找到一个点的值可以很好地代表这一系列点。那要怎么做呢?
对此有许多可行的方法(请参阅补充部分以进行进一步讨论),但我们发现的最简单、最有效的解决方案是简单地计算圆锥台内所有坐标的预期位置编码
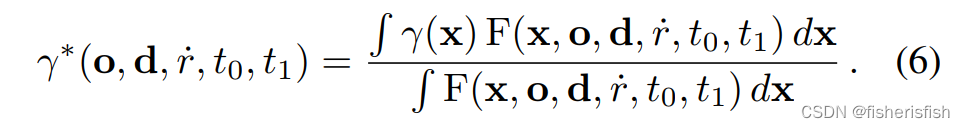
而后就是对上述积分利用多元高斯 (multivariate Gaussian) 进行近似,由于本人数学水平有限,就不再展开解释了,最终的多元高斯近似结果:

简单来理解的话就是将本来的圆锥近似成了NeRF里的射线形式。
再来解释一下为什么用这个方法就不用Coarse-to-Fine 策略了,核心原因就是Mip-NeRF 准确描述(进行了合理的建模)了像素包含区域随物体远近变化的关系(近大远小)。对像素来说,越远的区域截断视锥越大,即积分区域越大,此时 Encoding 高频部分的均值迅速衰减到 0(等价于 MipMap 的 Prefiltered 的功能),避免了远处样本点的突然出现的高频信号的影响。可以看出下右图中的采样信号几乎就是自带边缘信息的。
缺点
- Integrated Positional Encoding (IPE) 比 Positional Encoding 运算复杂度稍高(但单个 MLP 在计算资源层面的优势弥补了这一劣势)。
- Mip-NeRF 相比 NeRF 能够非常有效且准确地构建 Multi-View 与目标物体的关系,但这也意味着相机标定误差(即相机 Pose 的偏差)会更容易使 Mip-NeRF 产生混淆,出现更严重的失真。
很多研究者观察到了这一现象,侧面说明了高质量的 NeRF 重建的前提是实现准确的相机标定,于是研究者们后续提出了一系列的 Self-Calibration 的工作。
同理,当拍摄过程中存在运动模糊 (motion blur) 、曝光等噪声时,Mip-NeRF 也会很容易受到影响。只有当图片成像质量高且相机姿态准确时,Mip-NeRF 才能实现非常棒的效果。后续关于 Self-Calibration、deblur 和曝光控制等工作在一定程度上也是通过更改网络和设置使得 NeRF 能够对这些因素鲁棒,增加容错率(减少失真)
3、Mip-NeRF 360:Unbounded Anti-Aliased Neural Radiance Fields
作者在这篇论文针对的是NeRF对于Unbounded场景的重建效果,什么是Unbounded?个人理解是除了对物体完整建模以外,还需要对背景进行高质量的建模,原来的NeRF射线采样的方法很难实现同时高质量建模物体和背景。
NeRF++是最早关注这个问题的论文,提出的方法是前进背景分开建模。NeRF++ 根据单位球划分了内外,分别用两个 NeRF 进行处理,内部就是正常的 NeRF 采样、训练、渲染(正常的欧式空间)。外部区域仍正常采样,但对坐标进行了变换 (inverted sphere parametrization)
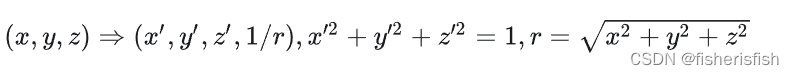
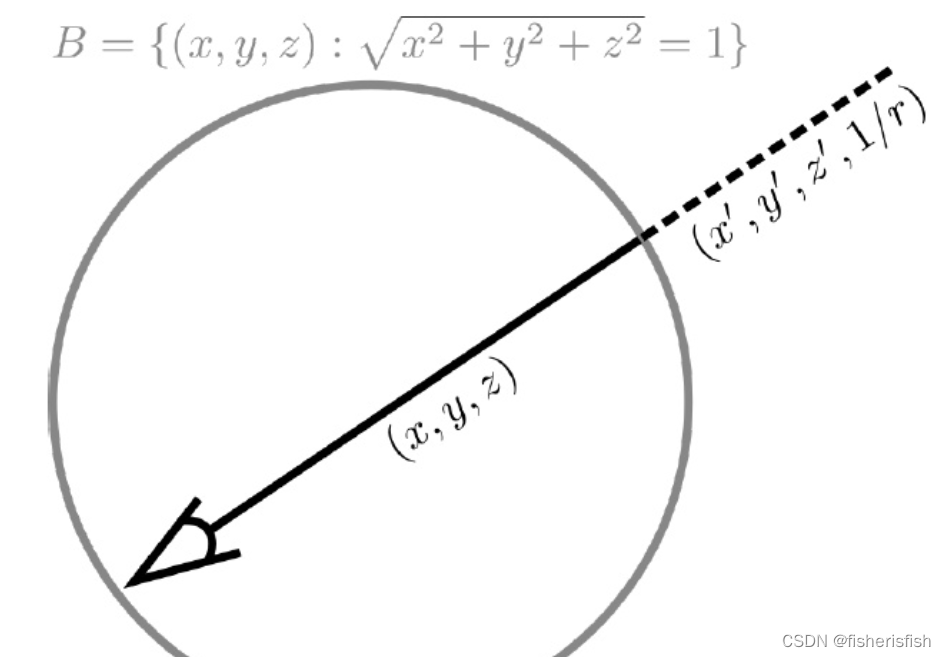
Mip-NeRF 360同样对前景背景做了不同的修改,
