版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/82284088
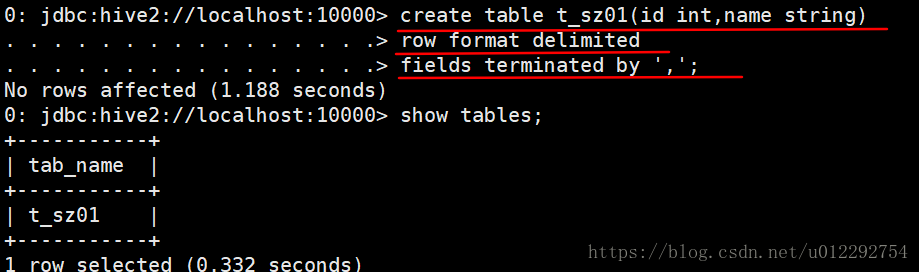
1 新建一个表
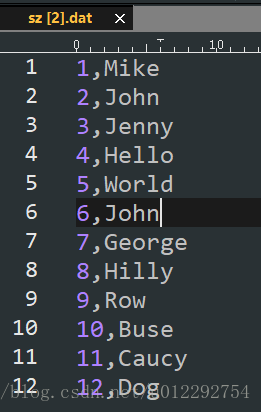
给表添加数据

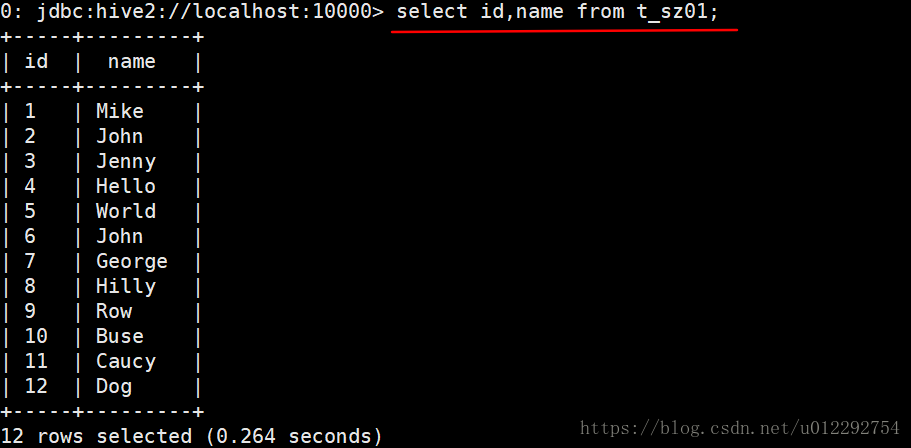
查询数据
2 调用 mapreduece 测试
select id,name from t_sz01 order by name;
开始报错
客户端的报错信息
0: jdbc:hive2://localhost:10000> select id,name from t_sz01 order by name;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Error: org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:380)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:257)
at org.apache.hive.service.cli.operation.SQLOperation.access$800(SQLOperation.java:91)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:348)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1758)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:362)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748) (state=08S01,code=2)
服务器端的错误信息
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20180903101007_9e7d7d77-493e-4229-b28d-63cc3fea2f4f
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535939204925_0001, Tracking URL = http://node1:8088/proxy/application_1535939204925_0001/
Kill Command = /home/hadoop/apps/hadoop-2.7.6/bin/hadoop job -kill job_1535939204925_0001
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2018-09-03 10:16:12,587 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1535939204925_0001 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
访问 http://node1:8088,报错信息如下:
Diagnostics:
Application application_1535939204925_0001 failed 2 times due to Error launching appattempt_1535939204925_0001_000002. Got exception: java.net.ConnectException: Call From node1/192.168.73.101 to node1:45652 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor49.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy83.startContainers(Unknown Source)
at org.apache.hadoop.yarn.api.impl.pb.client.ContainerManagementProtocolPBClientImpl.startContainers(ContainerManagementProtocolPBClientImpl.java:96)
at sun.reflect.GeneratedMethodAccessor15.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy84.startContainers(Unknown Source)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:119)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:250)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:615)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:713)
at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:376)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1529)
at org.apache.hadoop.ipc.Client.call(Client.java:1452)
... 15 more
. Failing the application.2.1 错误解决
发现是每个节点下的 /etc/hostname 文件里的主机名没有个相应的节点对应起来,修改后,重启。
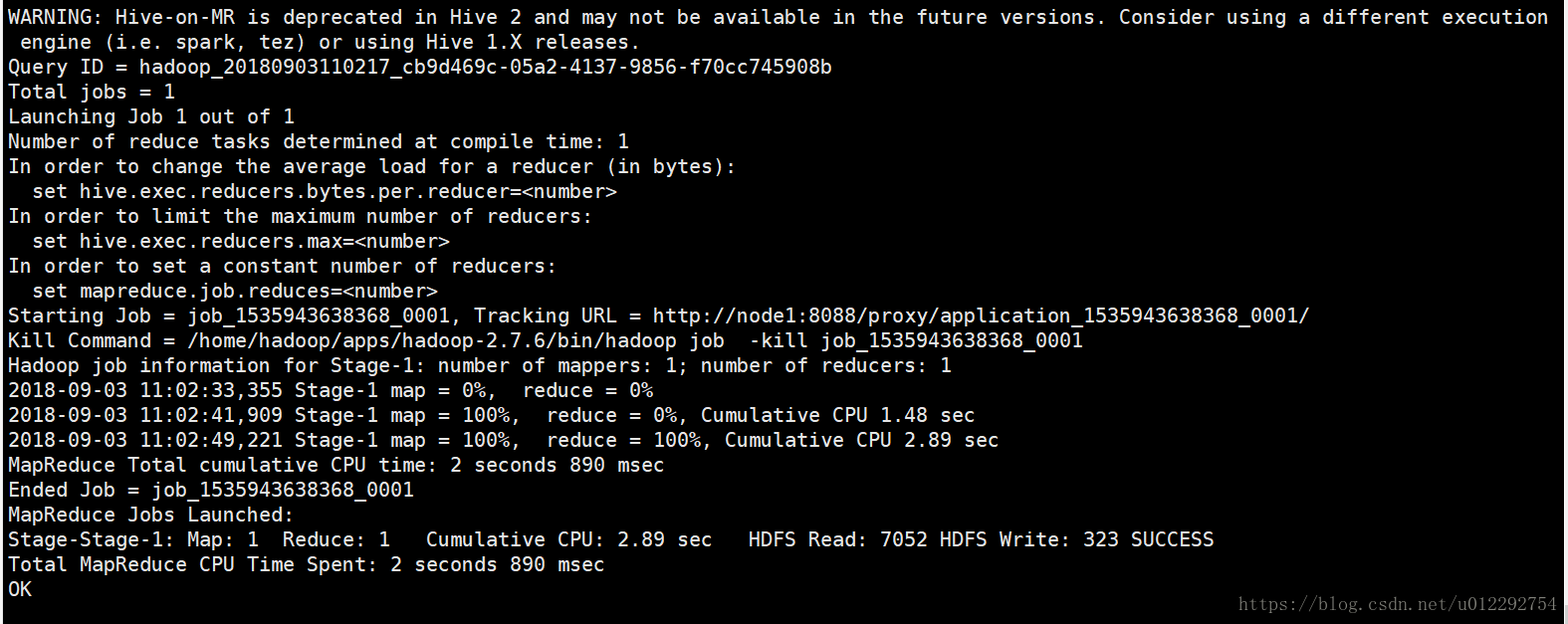
2.2 正确结果
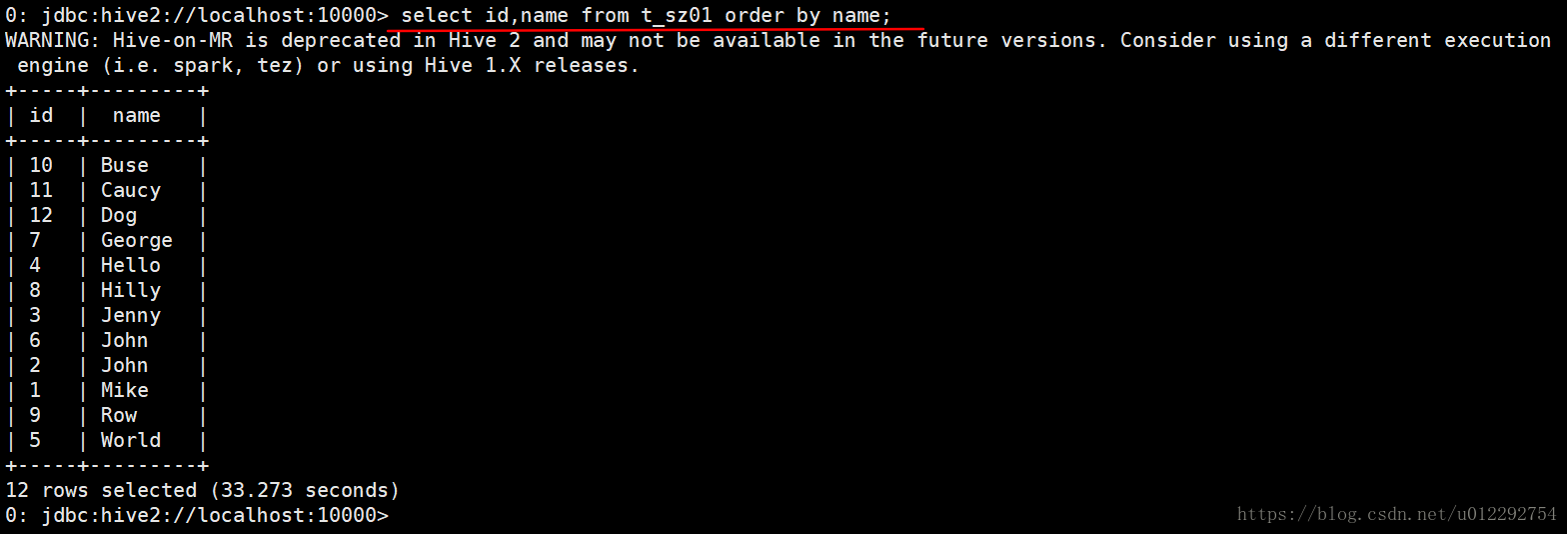
服务端输出信息