会议:2020 interspeech
作者:Liqiang Zhang
单位:Beijing Institute of Technology,Tencent AI Lab
demo链接
文章目录
abstract
初衷:想要实现SVC,但是目标说话人的歌唱数据很少;
方法:通过目标人正常的speech数据生成高质量的歌唱数据。通过统一speech合成和singing合成的特征,将speech和singing的train/conversion整合在一起。因此,正常的speech数据也可有助于SVC的训练,尤其是歌唱数据很少的时候。 因为要做one-shot training SVC,所以需要一个单独的speaker embedding module(用speech和singing的数据寻训练)。
结果:目标人20s的注册speech数据完成source到目标人的歌唱转换。
1. introduction
歌唱合成需要一个人大量的数据,但是是hard and expensive。[4]训练一个multi-speaker singing synthesis,然后用小数据的target speaker singing data进行fine-tune。对于unseen voice,可以通过SVC完成。【Unsupervised singing voice conversion】首先提出基于非平行数据以及wavenet-autoencoder结构的SVC,neither singing data nor the transcribed lyrics or notes is needed。
尽管如此,SVC仍然需要相当大的歌唱数据,【10】做了speech2singing的任务:修正f0 contour和duration 信息,但是需要人工的手动修正才能达到好的可懂度和自然度。
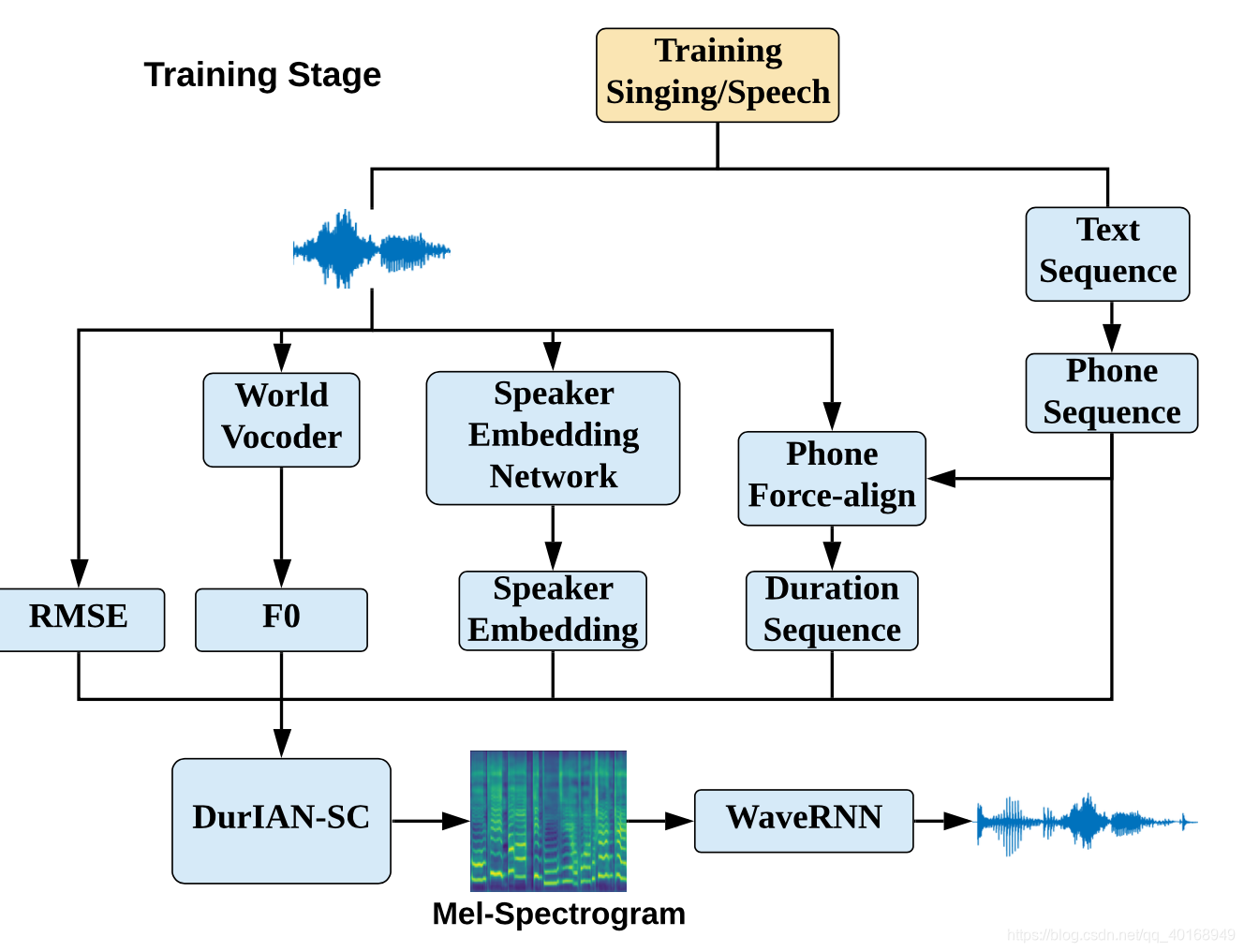
Duration Informed Attention Network (DurIAN)是做多模态合成,用自回归网络帧级别生成语音特征。本文基于
DurIAN网络,做speech&sing conversion。贡献点:(1)将speech synthesis和singing synthesis的网络合并,可以通过speech数据训练sing voice conversion。(2)speaker embedding是用一个训练好的d-vector网络提取的,而不是LUT(look up table)的结构。转换过程中:20s的目标说话人speech or singing数据用于提取d-vector,即可完成转换。
tts前端将speech/sing的文本转成phone-seq,TDNN做force_align得到对齐时长,声学特征包括mel,F0/RMSE(能量均方差)。不同于TTS的五因子,non-tonal phone用于同时建模speech&singing phones。
Speaker embedding network:用speech和singing的数据共同训练,提取句子中的d-vector。
整个模型只有一个loss:mel 重建损失
2. Model Architecture
2.1 DurIAN-SC
DurIAN:优点在于合成稳定且时长可控
DurIAN-SC:
input:(1) speech的文本或者song的歌词,用TTS前端进行韵律分词,(2) 使用帧级别的F0以及RMSE(average Root Mean Square Energy)
- 理由:(1)F0和韵律是由score note以及内容决定的(说话人无关),因此除非source 和target的pitch范围相差太大。(2)RMSE作为输入有助于loss收敛;

2.1.1 encoder
- 输入phone sequence X 1 : N X_{1:N} X1:N
- 输出phn的编码 h 1 : N h_{1:N} h1:N
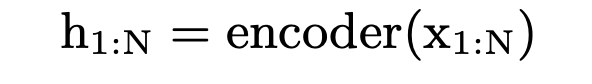
2.1.2. Alignment model
- 将phn_seq和target做等长映射
- d 1 : N d_{1:N} d1:N是phn对应的时长信息,将phn-seq进行扩增
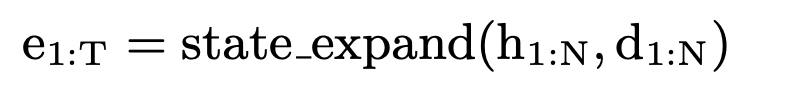
- 真正送入decoder的输入是(1)扩帧后的phn-seq e 1 : N e_{1:N} e1:N,(2)基频 f 1 : N f_{1:N} f1:N,(3)RMSE r 1 : N r_{1:N} r1:N, (4)句子级别的speaker embedding扩帧T次 D 1 : N D_{1:N} D1:N, concat之后送入FC层
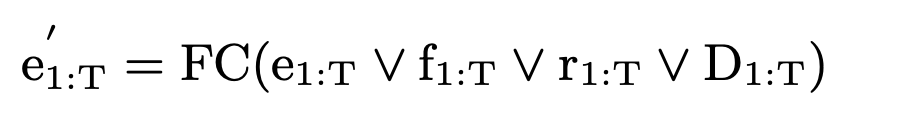
2.1.3 decoder
每个decoder step解码2步
2.2 Singing Voice Conversion Process
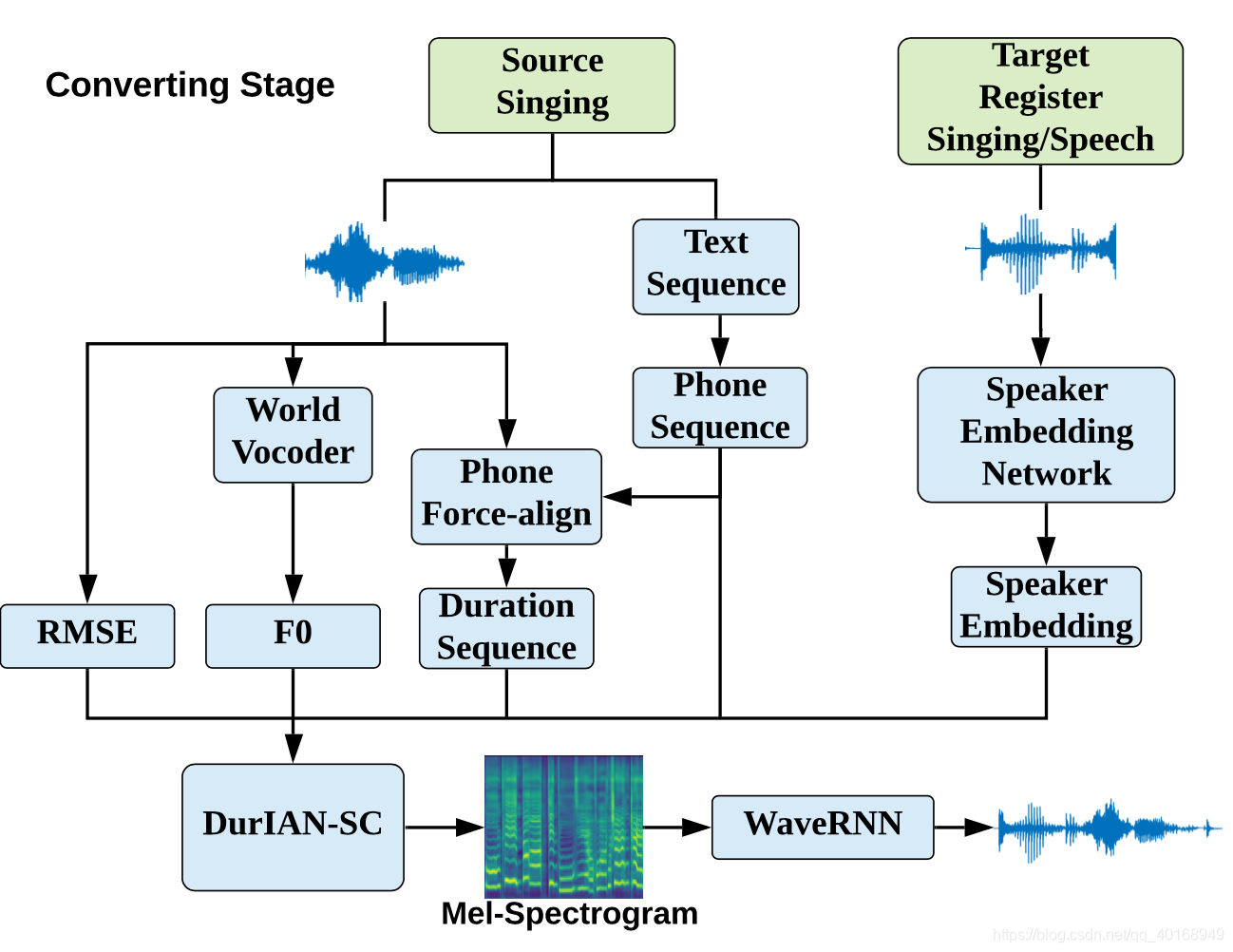
- TTS mandarin使用的是五因子的phn_id建模,本文用none tonal phone, 目的是可以同时建模speech和sing。
- 时长信息来自于force align
3. Experiments
数据集:
- (1)A:18h的歌唱数据,3600个歌唱片段(2600女声,1000男声),每段20s,是歌唱者自己用各种各样的设备录制的,24KHz
- (2)B:TTS中文speech数据,10h,4女3男
- (3)C:另外一个中文歌唱数据集用作测试
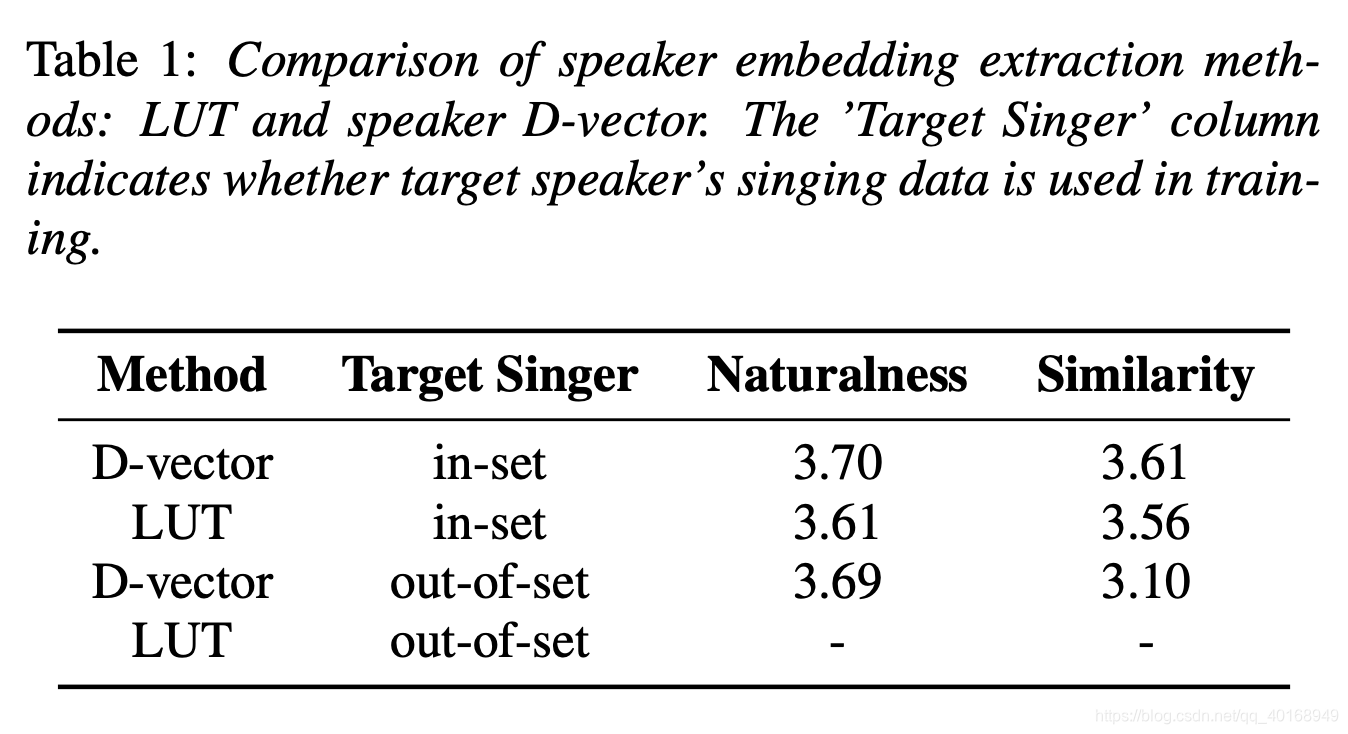
实验:比较speaker embedding
- 比较speaker embedding:LUT和d-vector
- in-set (A)和out-set(B)说话人转换的声音自然度和相似度(每人只有20s)
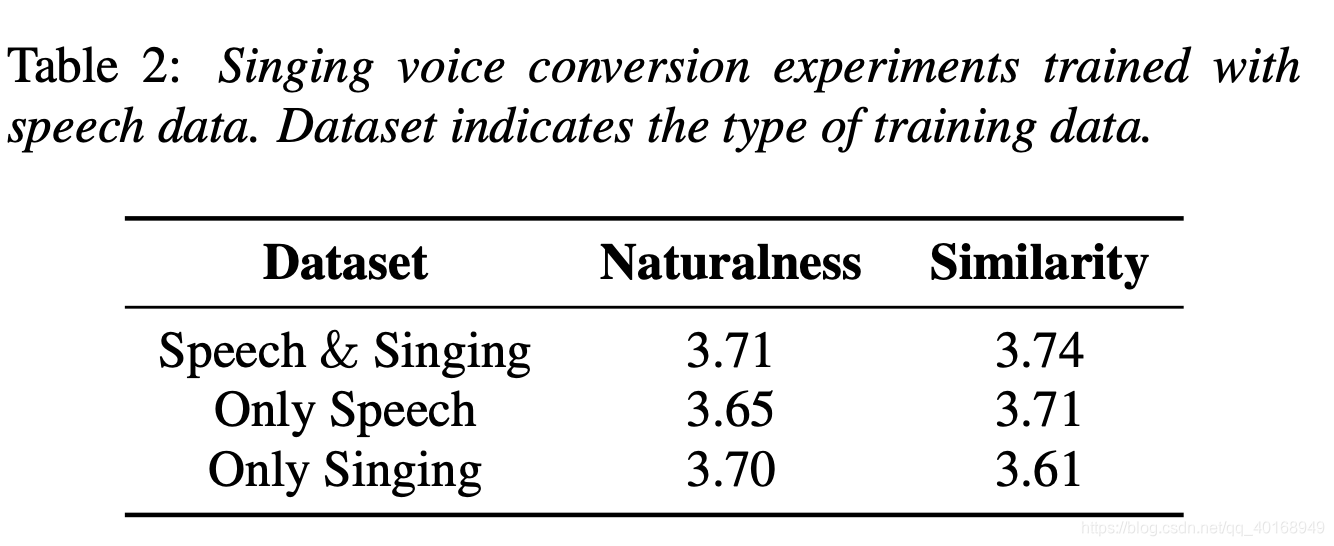
实验:比较训练数据集对结果的影响