会议:2019 APSIPA
作者:ZHOUYI Li Haizhou
单位:新加坡国立
abstract
average modeling approach用一个低维度的speaker embedding和vc网络联合训练,可以达到many-to-many cross-lingual的效果。
base-model: vc+i-vector作为speaker embedding表示。
introduction
average model可以表示训练集说话人的average voice。但是需要adaptive step for new target speaker。
adaptation 的三种经典方法:
(1)average model用新的说话人的句子进行自适应,但是由于两种语言之间的gap,会有较大的失真。
(2)用i-vector拼接在输入特征上,网络学习说话人独立的特征映射。但是i-vector提取的模型是单独的sv loss,没有和vc model联合训练。
(3)deep voice2: trainable speaker embedding+TTS联合训练,模型可以学到seen speaker的能力。
本文提出:speaker embedding+vc联合训练。声学特征通过一个辅助的网络的得到speaker embedding。
i-vector based vc
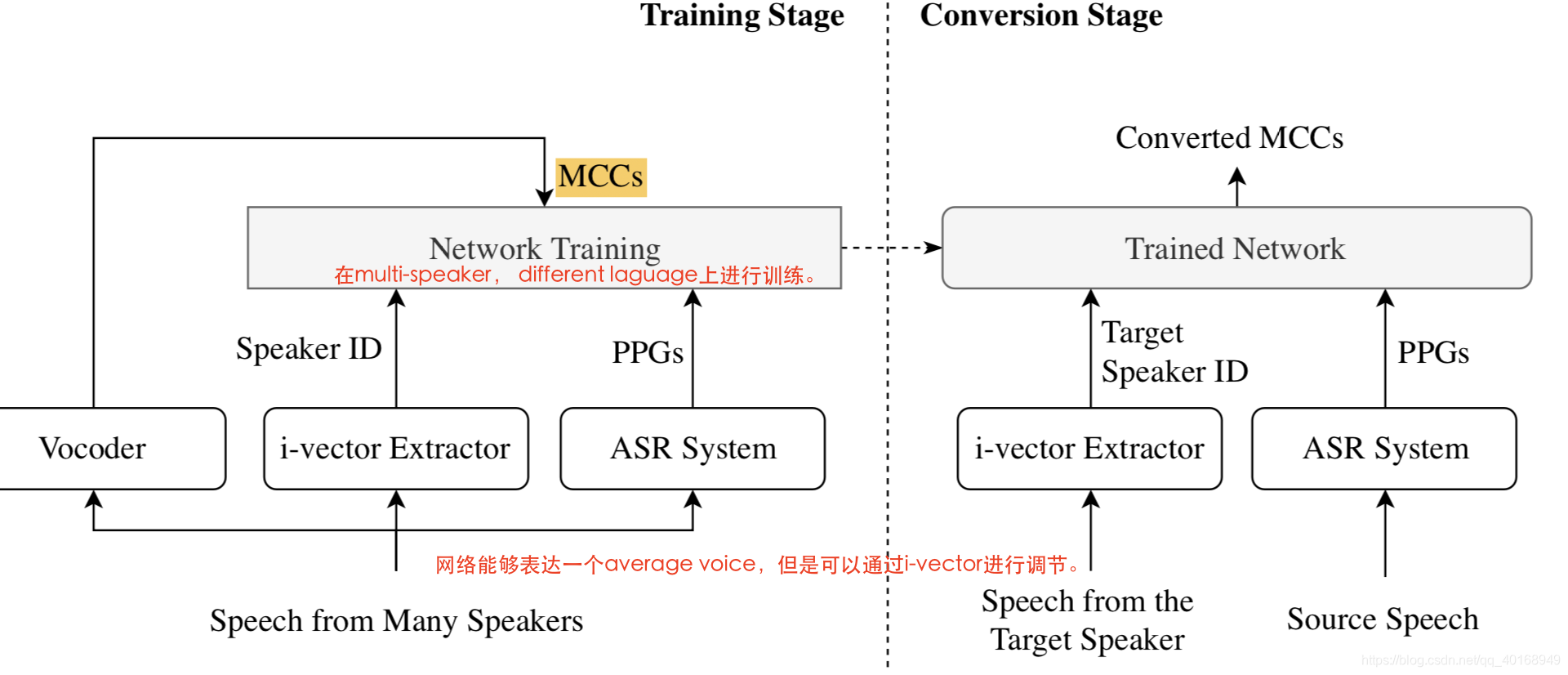
The training stage and conversion stage of the cross-lingual voice conversion system with the average model conditioned on i-vector.
vc with jointly trained speaker embedding

voice conversion的网络把ppgs转换成MCC,辅助的一个speaker embedding网络,输入同一个人一句话的MCC(不一定来自同一句话,最好不是),提取到定长的speaker embedding,然后repeat+拼接在ppgs编码后的latent embedding上。
因为speaker embedding的网络和文本无关,只是从MCC中提取说话人身份信息,因此可以适用于cross-lingual的转换中。
experiment
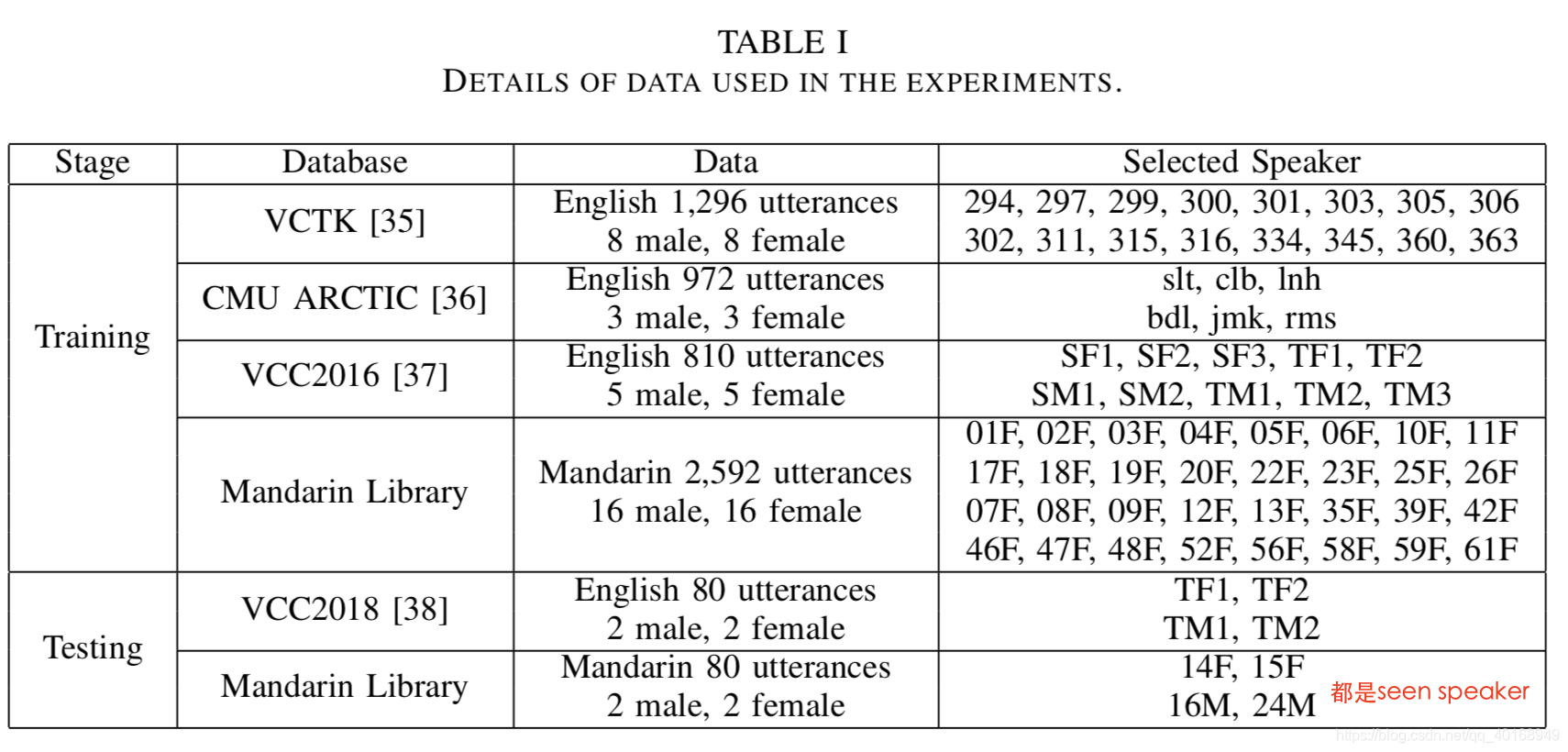
训练和测试的数据选取:一共男en-16, mandarin-16,女en-16, mandarin-16。
ppgs: 341-bilingual-ppgs