文章目录
abstract
- 歌唱修音主要难点在于将基频和对应歌曲模板对齐,传统的是使用DTW或者CTW(Canonical Time Warping)算法, 本文提出Shape-Aware DTW算法,可以改善对齐的鲁棒性。
- 传统的修音只考虑了基频对齐,没有考虑整体听感的舒适感,本文将说话人的歌唱分为两部分:(1)vocal tone,是各种歌唱技巧的统称,(2)vocal timbre,具体指的是发音人的个性,比如音色。要做的是改善业余歌手的歌唱技巧(vocal tone),在latent representation空间求对齐和最大似然。vocol timbre保持不变。
- 建设一个数据集PopBuTFy,包含同一首歌专业&业余两种唱法(同一个人),同时模型因为自监督训练,使用到很多无标签的多说话人数据。
method
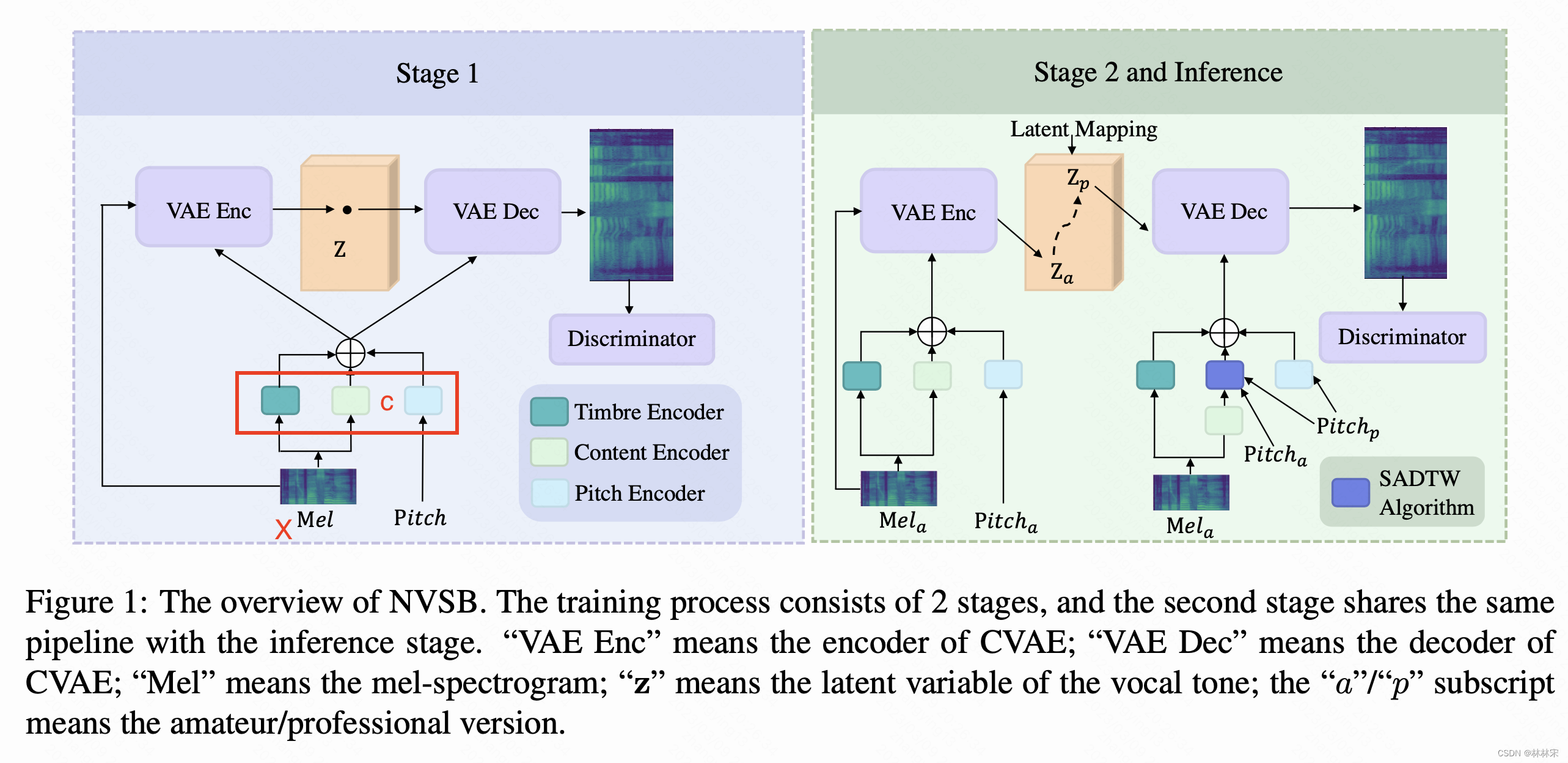
CVAE
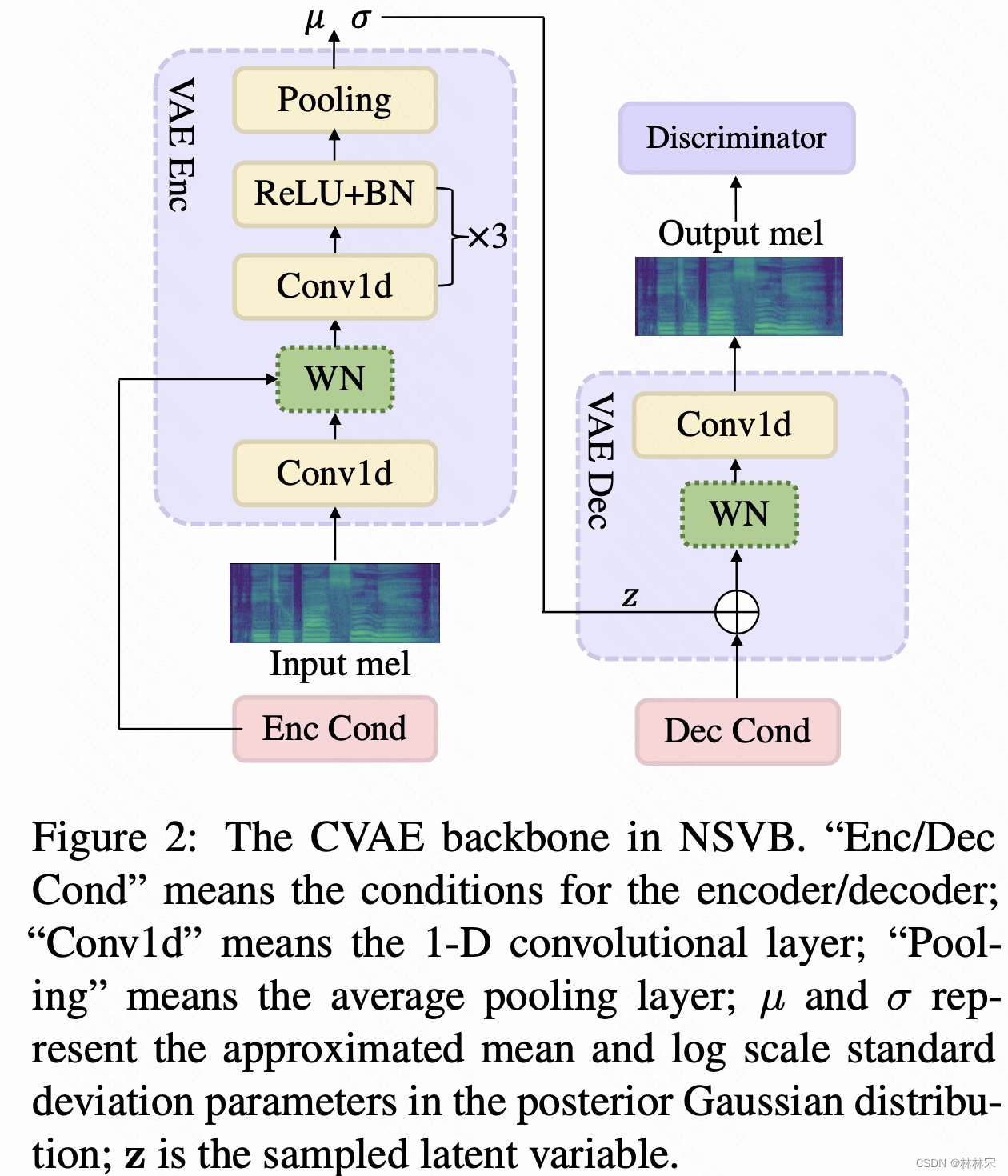
- CVAE的结构,输入mel,输出mel,中间添加条件补充;为了解决decoder预测mel过拟合的问题,输出端加判别器
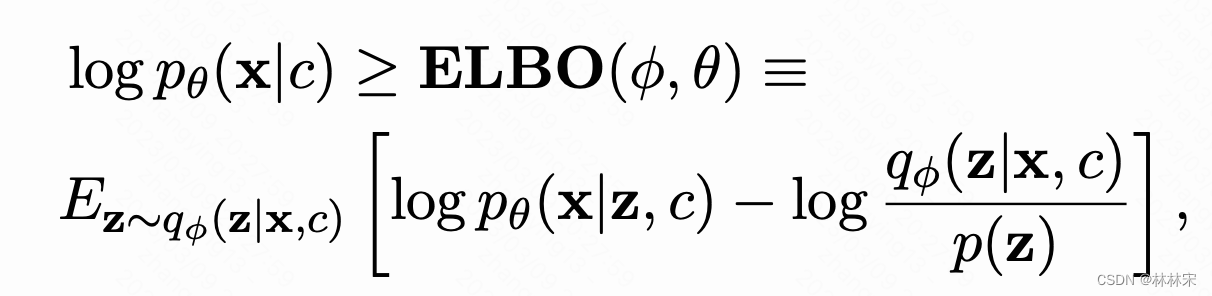
- x x x : mel spec; z z z:vocal tone, c c c:content, pitch,vococal timbre
Shape-Aware Dynamic Time Warping
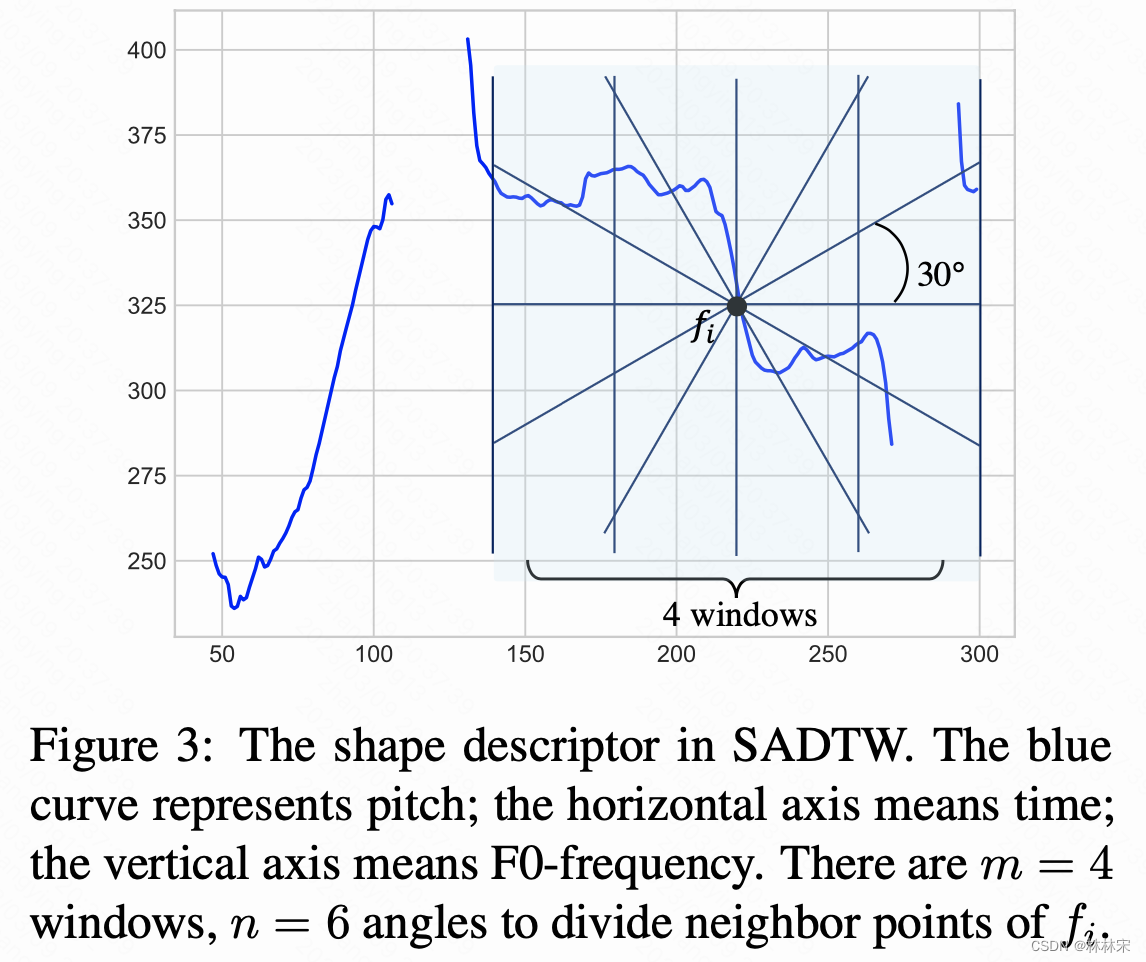
- 常规的DTW算法只是对基频数值进行对齐,本文提出的Shape-Aware DTW考虑数值(量化分区)和角度两个方面。
- 用直方图 h i ( k ) h_i(k) hi(k)表示时间 i i i处的基频 f i f_i fi,然后用 C ( a , p ) C(a,p) C(a,p)计算业余和专业歌手基频直方图归一化之后的距离,然后对 C ( a , p ) C(a,p) C(a,p)通过DTW计算对齐

Latent-mapping Algorithm
- 将业余歌手的vocal tone z a z_a za映射到专业歌手同一首歌的演唱身上 z p z_p zp
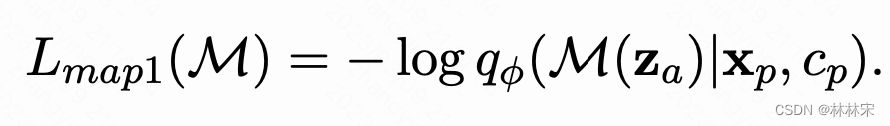
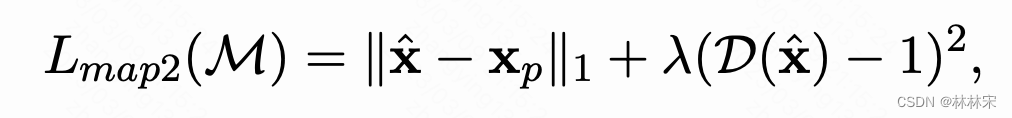
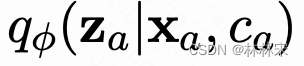
M M M是映射函数, c p c_p cp是专业歌手content embedding(如果是业余歌手,是SADTW对齐之后的content embedding、vococal timbre embedding, template pitch embedding)
L m a p 2 L_{map2} Lmap2是为了保证converted latent emb可以和c^_p生成高质量音频
Training and Inference
- 第一阶段:训练CVAE,其中 ϕ \phi ϕ , θ \theta θ分别是encoder、decoder的参数
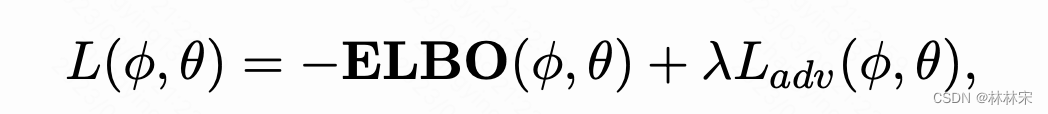
- 第二阶段:固定encoder/decoder/discriminator,训练latent emb align
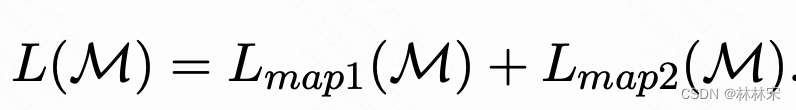
- 第三阶段:inference, e n c o d e r ( c a , x a ) encoder(c_a,x_a) encoder(ca,xa)预测 z a z_a za,然后 M ( z a ) M(z_a) M(za), d e c o d e r ( M ( z a ) , c p decoder(M(z_a), c_p decoder(M(za),cp预测mel
第一、二阶段,除去平行数据以外,还用无标签的30h歌唱数据进行训练
model arch
- encoder: 1 layer 1D conv(stride=4) + 8-layer WaveNet + 3*1D conv BN+ mean pooling----mean/var
- decoder: 4-layer WaveNet + 1D conv —mel80
- discirminator:multiple random window discrimina- tors.
- content encoder:conformer-based ASR AM----ppgs,使用AISHELL-3和LibriTTS在中英文数据上都训练一下。
- timbre encoder:open API speaker verification
- prosody encoder:3*conv,Parselmouth提取pitch
- latent mapping function:2*linear
- HiFiGan vocoder,基于歌唱数据训练好的
experiment
PopBuTFy:99 Chinese pop songs (⇠10.4 hours in total) from 12 singers and 443 English pop songs (⇠40.4 hours in total) from 22 singers. 平行数据,每首歌以专业/业余的方式被演唱两次。