粒子群优化算法(Particle Swarm Optimization,PSO)与模拟退火算法类似,通过随机解出发,迭代找出最优解,通过适应度(评价指标)来评价解的品质。
1 基本原理
在PSO中,,每个优化问题的潜在解,相当于解空间的一个粒子,粒子都有一个由优化函数确定的适应值(fitness),每个粒子有,位置,速度等基本属性。通过不同迭代,更新粒子的速度和位置来得到最适解,粒子在某一个位置越集中,代表该问题的解所在。

其中X表示粒子位置,V表示粒子速度,Pid 表示个体粒子的最优位置,Pgd表示群体粒子的最优位置。
2 更新规则和流程图
假设在D维空间中,有N个粒子组成的一个群落,其中第i个粒子表示为一个D维向量

同理飞行速度V也是一个D维变量
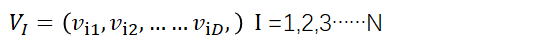
第i个粒子搜索到的最优位置成为个体极值,记为
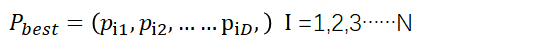
整个群体搜索到的最优位置为
![]()
利用以下公式 进行位置和速度的变更
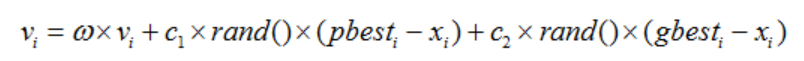
![]()
Vi 中 第一部分为“惯性”反映粒子运动习惯
第二部分为“认知”,表示粒子有向自身最优位置行走趋势
第三部分为“社会”,表示粒子有向群体最优位置移动趋势
其中 w 叫做惯性因子,非负值,可以用以下公式进行更新或者设置为常数
最初其值较大,全局搜索能力较强。
最后其值较小,局部搜索能力较强。

C1 和 C2为学习因子,也称加速度常数,rand为[0,1]的随机数
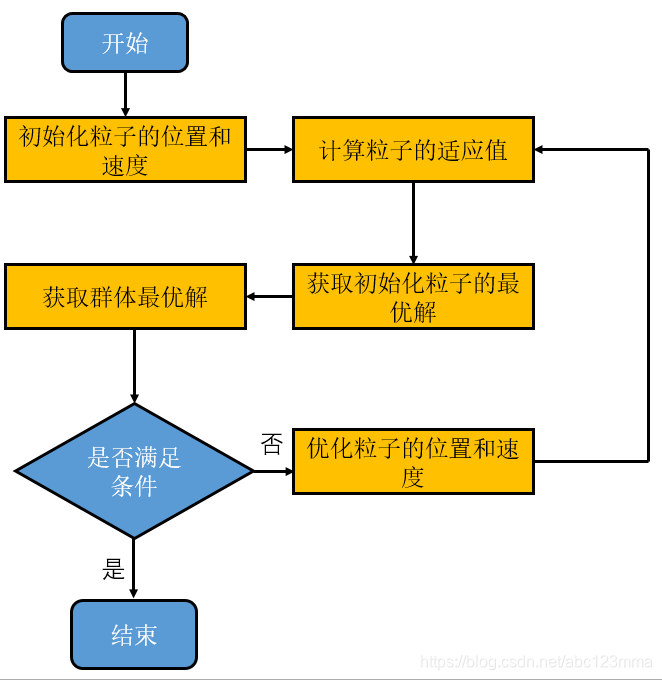
3 整体代码
使用方法:[xm1,fv1] = PSO(@fitness,50,2,2,0.5,100,30);

设置适应度函数
function F=fitness(x)
F=0;
for i=1:30
F=F+x(i).^2+x(i)-6
end
end
粒子群寻优算法
function [xm ,fv ] = PSO( fitness,N,c1,c2,w,M,D )
%% 参数 fitness为待优化的目标函数(适应度函数),N为粒子数目,c1,c2为学习因子(即各部分的贡献度,相当于加了一个权重)
% w为惯性权重,M为最大迭代数,D为自变量的个数(相当于维度)
%% 结果:xm 为目标函数取最小值时候的自变量,fv是目标函数的最小值
%%
%初始化位置以及速度
format long; %有效数字16位
for i=1:N
for j=1:D
x(i,j)=randn;%随机初始化位置
v(i,j)=randn;%随机初始化速度
end
end
%计算每个粒子的适应度
for i=1:N
p(i)=fitness(x(i,:));
y(i,:)=x(i,:);
end
pg=x(N,:); %pg全局最优
for i=1:(N-1)
if fitness(x(i,:)) <fitness(pg) %%根据适应度函数以及需求进行符号的选取(<,>)
pg=x(i,:);
end
end
%按照公式进行迭代,直到满足精度要求
for t=1:M
for i=1:N %更新速度、位置
v(i,:)=w*v(i,:)+c1*rand*(y(i,:)-x(i,:))+c2*rand*(pg-x(i,:));%rand产生[0,1]上的均匀值,服从均匀分布
x(i,:)=x(i,:)+v(i,:);
if fitness(x(i,:)) <p(i)
p(i)=fitness(x(i,:));
y(i,:)=x(i,:);%个体历史最优进行更新
end
if(p(i)<fitness(pg)) %%根据情况判断符号的选取
pg=y(i,:);%全局最优进行更新
end
end
Pbest(t)=fitness(pg); %历次最优适应度值
end
%%结果展示
plot(Pbest)
disp('****************************')
xm=pg' %全局最优的结果
fv=fitness(pg) %最优结果的适应度值
end