https://arxiv.org/pdf/1808.00191.pdf
本文摘要没有介绍背景及他人方法,而是开门见山,指出本文提出了一个新的scene generation model,叫做graph R-CNN。接着介绍这个模型的特点是能够既能高效的检测到图片中的物体,又能有效的抓取物体之间的关系。本文模型包括一个Relation proposal network(RePN),能够高效的解决物体间两两的联系随着物体数量以平方的形式增长的问题,本文还提出了一个attention graph convolutional network(aGCN),能够高效抓取物体和relation之间的相互联系。最后一点贡献是提出了一个结果衡量方式,这个衡量方式相比于现有的衡量标准更加全面,更加实际。最后作者一句话概括说自己的模型在实验中无论是用现有的衡量标准,还是新提出来的衡量标准,都取得了state-of-the-art的结果。
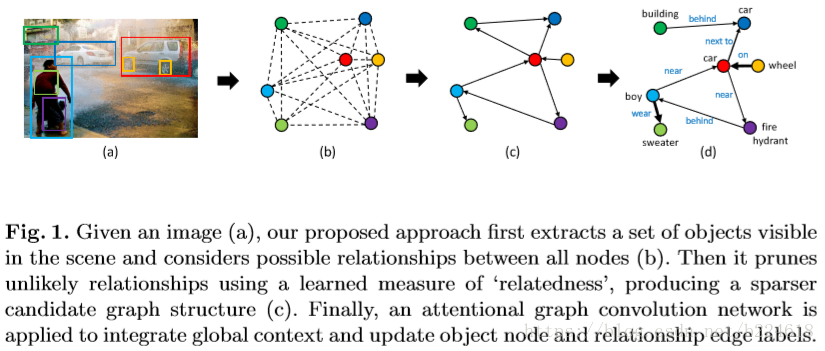
本文提出的模型大体流程可用上图表示,给定一张image,首先从image中抓取出一组可见的物体,然后假定所有物体两两间都有联系,接着用学习出来的“relatedness”将那些不太可能的relation去掉,使得得到的graph变得稀疏一些,合理一些。最后,一个图卷积网络被用来整合global context,并且更新object node和relationship edge的标签。整体来讲,graph R-CNN就这三个阶段。下面详细介绍模型。
将一个image表示为I,V表示一组nodes,每一个node对应I中识别出来的一个object的区域,表示edge的集合,O,R分别表示object和relation的标签,则整个模型可以表述为
,也就是给定image预测graph,在本文中,这个工作被分解成三个部分

也就是最终的概率是三个部分相乘,分别预测object,relation(edge)和label。这里面对于object的预测可以使用现成的物体识别系统;
使用的是一个relationship proposal network(RePN),作者指出现存的生成edge的方法都是随机抽样的,因此不能视作是一个end-to-end的系统,而本文这个直接生成edge的方法使得整个模型变成了end-to-end的;最后的
一般采取一个迭代的优化过程,不断地进行修饰。
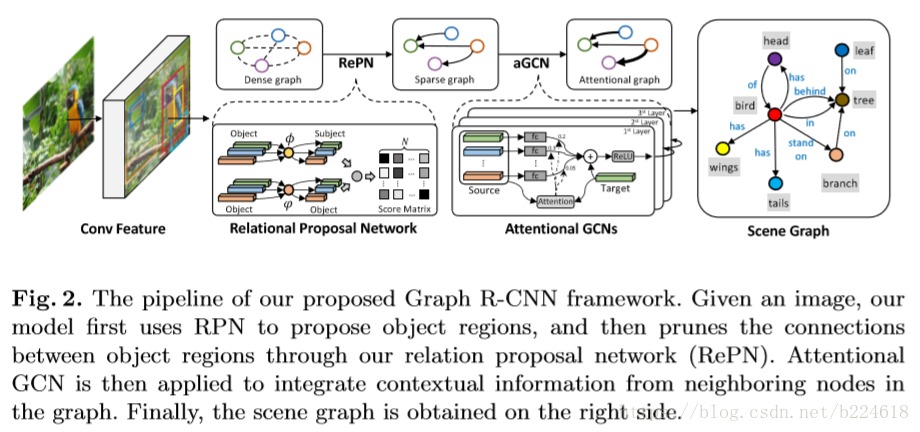
具体来讲,模型的object识别采取的是用faster R-CNN提取出一组n个object proposal,每一个proposal i都对应着一个空间区域,一个pooled feature vector
,和一个初始的在k个类别上的label分布的预测
。所有n个proposal对应的就是
。
对于给定的n个object proposal,之间的可能存在的relation数量级是,但是有很多物体之间是不需要加relation的,因此需要去掉很多edge,本文采取的方法是基于
,也就是根据edge连接的两个object的类别来判断是否有必要加这个edge。一个很自然的想法就是将这两个object的类别分布连接起来得到
,然后输入到MLP中,但是这种方法不经济,因此,本文采取的是另一种方法
这里面,f输出的就是两个物体之间的relatedness score,和
是两个投影函数,一个是对subject使用的,一个是对object使用的,这里面是将relationship的第一个object和最后一个object区分开来,也就是形成
,将relatedness score按这种方式表示,计算relatedness score组成的score matrix
就只需要先计算对
(这里应该是写错了,明明是对
的投影)的两个投影,接着再计算矩阵乘法。这两个投影函数采用的是相同结构不同参数的MLP,计算完之后还要经过sigmoid得到0,1之间的score。得到score之后,按数值大小取前K个作为选定有edge的位置。之后又通过non-maximal suppression(NMS)来去掉相互重叠很大的object对,具体来将,两个object对{u,v}和{p,q},两对之间的重合(overlap)是
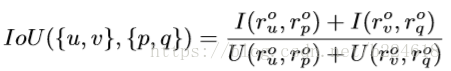
I是计算交叉部分的算符,U是共同的部分,要注意这个和顺序是有很大关系的,{u,v}和{v,u}计算出来的结果就不同。通过这个标准筛选剩下的m个edge就是剩下的有意义的edge。这样,一个graph就生成了,有节点也有边,完整了。
接下来使用aGCN对节点和边进行进一步的修饰,其实这个aGCN就是一个在每一个node的位置进行加权求和获得卷积结果的模型,加权求和的权重是可以学习的,这个就是所谓的attention,具体来讲attention使用两层的MLP来进行预测的
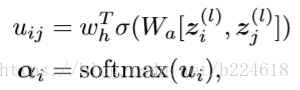
这里面的zi是第i个节点的feature vector,上标l表示第l层,W是wh都是可学习的参数,[.,.]是将两个vector连接在一起的操作。而具体的卷积操作如下
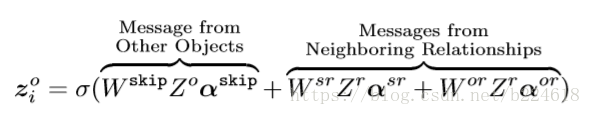
这是对节点feature进行更新的操作,上标o代表object,r代表relation,s代表subject,也就是说更新每一个node的信息的时候,是考虑了此node本身的信息,周围relation的信息,而且整合relation信息的时候还要考虑是relation和subject的关系,还是relation和object之间的关系,并且注意到这个信息流动是不对称的,作者对此的举例解释是subject对relation提供的信息和relation对subject提供的信息不一定一样。
对relation的feature的更新方式如下
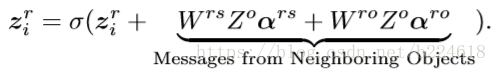
文章的最后一个贡献是一个新的衡量标准,用来衡量一个生成的graph的优劣,这个衡量标准比之前的衡量标准要宽松一些,更加全面一些,以下图为例可以很清晰的看出新旧标准都是什么意思
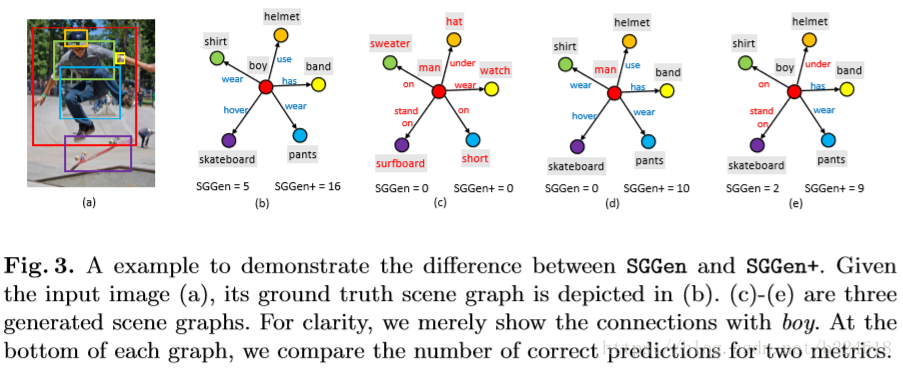
这里面的(b)是ground,后面几个是生成的graph,下面的SSGen是老标准下正确预测数量,SSGen+是新标准衡量下,预测正确数量。老标准是要求(object,relationship,subject)这个triplet预测对了,才算预测对一个,例如(c)中,五个triplet全错,(e)中有两个是对的。而新标准就不仅仅考虑triplet的正确数量,还会考虑object的正确数量和predicate(谓语,例如stand on)的预测数量,从上图可以清晰地看出这是什么意思,例如最后一个,有两个triplet正确预测,有7个singleton(object或者predicate)成功预测,因此正确预测数是9.