详解贝叶斯方法
1 贝叶斯方法的理解
首先给出一个概率和似然的对比实例:
(Qa) 假设袋子内有 N N N个白球, M M M个黑球,伸手进去摸一次,摸出黑球的概率是多大?
(Qb) 假设袋子内黑白球比例未知,伸手进去摸若干次,观察取出的球的颜色来推测袋子内的黑白球比例。
对于似然问题(Qb),前面说过,贝叶斯学派认为环境参数 θ \theta θ不定,是一个随机变量。贝叶斯方法就是贝叶斯学派思考问题的模式,定义如下:
参数先验信息 π ( θ ) + 样本观测数据 X = 后验分布 P ( θ ∣ X ) \text{参数先验信息}\pi \left( \theta \right) +\text{样本观测数据}X=\text{后验分布}P\left( \theta |X \right) 参数先验信息π(θ)+样本观测数据X=后验分布P(θ∣X)
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对模型的认知是先验分布 π ( θ ) \pi \left( \theta \right) π(θ),在得到新的样本信息 X X X后,人们对模型的认知为后验分布 P ( θ ∣ X ) P\left( \theta |X \right) P(θ∣X)。
贝叶斯方法的深刻原因在于:现实世界本身就是不确定的,人类观察能力有局限性,日常所见几乎都是事物表面。正如(Qb)所描述的,我们往往只能知道从里面取出来的球是什么颜色,而并不能直接看到袋子里面得实际情况。所以这种通过对观测样本的补充,不断更新对事物规律的认识的思维方法符合机器学习思想和人类认识规律。
2 贝叶斯定理
贝叶斯定理的数学表述为:若 ⋃ k = 1 n B k = S \bigcup_{k=1}^n{B_k}=S ⋃k=1nBk=S且 B i B j = ∅ ( i ≠ j , i , j = 1 , 2 , 3 , . . . , n ) B_iB_j=\varnothing \left( i\ne j,\;\;i,j=1,2,3,...,n \right) BiBj=∅(i=j,i,j=1,2,3,...,n), P ( B k ) > 0 ( k = 1 , 2 , . . . , n ) P\left( B_k \right) >0\left( k=1,2,...,n \right) P(Bk)>0(k=1,2,...,n), P ( A ) > 0 P\left( A \right) >0 P(A)>0,则有:
P ( B k ∣ A ) = P ( B k ) ⋅ P ( A ∣ B k ) ∑ i = 1 n P ( B i ) ⋅ P ( A ∣ B i ) = 边缘化 全概率公式 P ( B k ) ⋅ P ( A ∣ B k ) P ( A ) \;P\left( B_k\mid A \right) =\frac{P\left( B_k \right) \cdot P\left( A\mid B_k \right)}{\sum_{i=1}^n{P\left( B_i \right) \cdot P\left( A\mid B_i \right)}}\xlongequal[\text{边缘化}]{\text{全概率公式}}\frac{P\left( B_k \right) \cdot P\left( A\mid B_k \right)}{P\left( A \right)} P(Bk∣A)=∑i=1nP(Bi)⋅P(A∣Bi)P(Bk)⋅P(A∣Bk)全概率公式边缘化P(A)P(Bk)⋅P(A∣Bk)
其中的等式也称为贝叶斯公式。
从机器学习模型的角度理解贝叶斯公式。假设数据样本 ( x 1 , x 2 , ⋯ , x n ) \left( x_1,x_2,\cdots ,x_n \right) (x1,x2,⋯,xn)是满足独立同分布的一组抽样 X X X,设模型参数为 θ \theta θ,基于贝叶斯方法,这里认为 满足先验分布,因此考虑参数后验分布:
P ( θ ∣ X ) = P ( θ ) ⋅ P ( X ∣ θ ) P ( X ) \;P\left( \theta \mid X \right) =\frac{P\left( \theta \right) \cdot P\left( X\mid \theta \right)}{P\left( X \right)} P(θ∣X)=P(X)P(θ)⋅P(X∣θ)
设稳定系数 α ( X ; θ ) = P ( X ∣ θ ) P ( X ) = 某参数下的样本分布 实际样本分布 \alpha \left( X;\theta \right) =\frac{P\left( X|\theta \right)}{P\left( X \right)}=\frac{\text{某参数下的样本分布}}{\text{实际样本分布}} α(X;θ)=P(X)P(X∣θ)=实际样本分布某参数下的样本分布,当 α ( X ; θ ) = 1 \alpha \left( X;\theta \right) =1 α(X;θ)=1时说明参数
估计与实际情况最为符合,其余情况下则说明此模型的样本估计并不稳定。所以在机器学习视角下,贝叶斯公式表述为:模型参数的后验概率等于其先验分布与稳定系数的乘积:
P ( θ ∣ X ) = P ( θ ) ⋅ α ( X ; θ ) \;P\left( \theta \mid X \right) =P\left( \theta \right) ·\alpha \left( X;\theta \right) P(θ∣X)=P(θ)⋅α(X;θ)
基于贝叶斯定理的模型训练,总会使稳定系数趋于1以使模型估计更稳定。
3 贝叶斯网络
贝叶斯网络又称信念网络(Belief Network),是一种概率图模型,模拟了人类推理过程中因果关系的不确定性,其网络拓扑结构是有向无环图(Directed Acyclic Graphical, DAG)。
贝叶斯网络中的节点表示随机变量,有向连边表示变量间有因果关系或非条件独立,两个用箭头连接的节点就会产生一个条件概率值,如图所示。

设 G = ( I , E ) G=\left( I,E \right) G=(I,E)表示一个DAG,其中 I I I是图形中所有节点的集合, E E E是所有有向连边的集合;函数 p a ( x ) pa\left( x \right) pa(x)表示一个从子节点到父节点的映射。令 x i ( i ∈ I ) x_i\left( i\in I \right) xi(i∈I)为DAG中某一节点 i i i所代表的随机变量,若 ∀ x i , i ∈ I \forall x_i\,\,, i\in I ∀xi,i∈I的概率可以表示成:
p ( x i ) = ∏ i ∈ I p ( x i ∣ x p a ( i ) ) p\left( x_i \right) =\prod_{i\in I}{p\left( x_i|x_{pa\left( i \right)} \right)} p(xi)=i∈I∏p(xi∣xpa(i))
则称此DAG是贝叶斯网络模型。
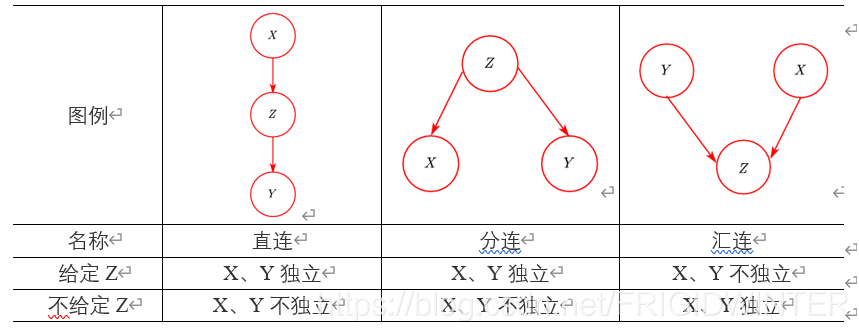
图2列出了贝叶斯网络的基本结构,判断节点变量的独立性意义在于:从概率图模型可知,进行独立性假设后可以作出可视化的概率图模型,那么如果给定一个有向概率图,判断变量间的独立性关系就是其逆过程。
从理论上对图2进行简单证明。
(a) 直连
给定 Z Z Z时,根据有向概率图因果关系可得:
P ( X , Y , Z ) = P ( X ) P ( Z ∣ X ) P ( Y ∣ Z ) P\left( X,Y,Z \right) =P\left( X \right) P\left( Z|X \right) P\left( Y|Z \right) P(X,Y,Z)=P(X)P(Z∣X)P(Y∣Z)
从而:
P ( X , Y ∣ Z ) = P ( X , Y , Z ) P ( Z ) = P ( X ) P ( Z ∣ X ) P ( Y ∣ Z ) P ( Z ) = P ( X ∣ Z ) P ( Y ∣ Z ) P\left( X,Y|Z \right) =\frac{P\left( X,Y,Z \right)}{P\left( Z \right)}\\=\frac{P\left( X \right) P\left( Z|X \right) P\left( Y|Z \right)}{P\left( Z \right)}\\=P\left( X|Z \right) P\left( Y|Z \right) P(X,Y∣Z)=P(Z)P(X,Y,Z)=P(Z)P(X)P(Z∣X)P(Y∣Z)=P(X∣Z)P(Y∣Z)
所以 X X X、 Y Y Y在给定 Z Z Z时条件独立。
(b) 分连
给定 Z Z Z时,根据有向概率图因果关系可得:
P ( X , Y , Z ) = P ( Z ) P ( X ∣ Z ) P ( Y ∣ Z ) P\left( X,Y,Z \right) =P\left( Z \right) P\left( X|Z \right) P\left( Y|Z \right) P(X,Y,Z)=P(Z)P(X∣Z)P(Y∣Z)
从而:
P ( X , Y ∣ Z ) = P ( X , Y , Z ) P ( Z ) = P ( Z ) P ( X ∣ Z ) P ( Y ∣ Z ) P ( Z ) = P ( X ∣ Z ) P ( Y ∣ Z ) P\left( X,Y|Z \right) =\frac{P\left( X,Y,Z \right)}{P\left( Z \right)}\\=\frac{P\left( Z \right) P\left( X|Z \right) P\left( Y|Z \right)}{P\left( Z \right)}\\=P\left( X|Z \right) P\left( Y|Z \right) P(X,Y∣Z)=P(Z)P(X,Y,Z)=P(Z)P(Z)P(X∣Z)P(Y∣Z)=P(X∣Z)P(Y∣Z)
所以 X X X、 Y Y Y在给定 Z Z Z时条件独立。
© 汇连
给定 Z Z Z时,根据有向概率图因果关系可得:
P ( X , Y , Z ) = P ( X ) P ( Y ) P ( Z ∣ X , Y ) P\left( X,Y,Z \right) =P\left( X \right) P\left( Y \right) P\left( Z|X,Y \right) P(X,Y,Z)=P(X)P(Y)P(Z∣X,Y)
从而:
P ( X , Y ∣ Z ) = P ( X , Y , Z ) P ( Z ) = P ( X ) P ( Y ) P ( Z ∣ X , Y ) P ( Z ) ≠ P ( X ∣ Z ) P ( Y ∣ Z ) P\left( X,Y|Z \right) =\frac{P\left( X,Y,Z \right)}{P\left( Z \right)}\\=\frac{P\left( X \right) P\left( Y \right) P\left( Z|X,Y \right)}{P\left( Z \right)}\\\ne P\left( X|Z \right) P\left( Y|Z \right) P(X,Y∣Z)=P(Z)P(X,Y,Z)=P(Z)P(X)P(Y)P(Z∣X,Y)=P(X∣Z)P(Y∣Z)
而不给定 Z Z Z时:
P ( X , Y ) = ∑ Z P ( X , Y , Z ) = P ( X ) P ( Y ) ∑ Z P ( Z ∣ X , Y ) = P ( X ) P ( Y ) P\left( X,Y \right) =\sum_Z{P\left( X,Y,Z \right)}\\=P\left( X \right) P\left( Y \right) \sum_Z{P\left( Z|X,Y \right)}\\=P\left( X \right) P\left( Y \right) P(X,Y)=Z∑P(X,Y,Z)=P(X)P(Y)Z∑P(Z∣X,Y)=P(X)P(Y)
所以 X X X、 Y Y Y在给定 Z Z Z时不条件独立,不给定 Z Z Z时条件独立。
综合上述(a)(b)©,当 X X X、 Y Y Y关于 Z Z Z(给定或不给定)条件独立时,称 X X X、 Y Y Y关于 Z Z Z(给定或不给定)有向分离,简称D-分离。
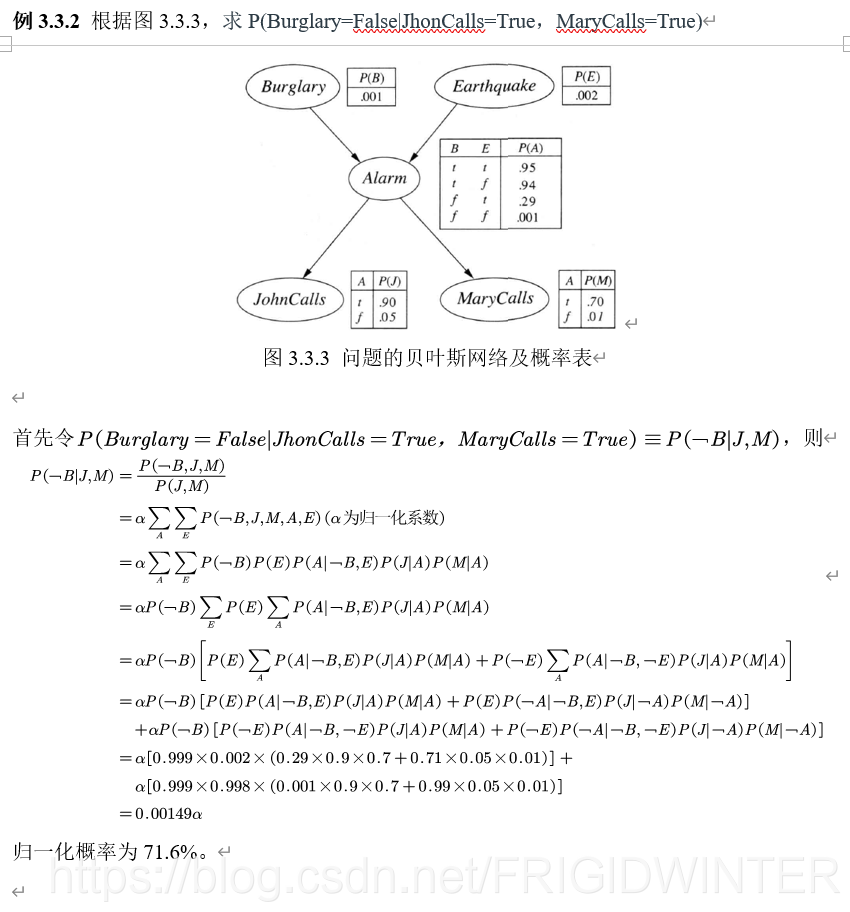
4 贝叶斯网络例题分析