本篇博文主要总结贝叶斯网络相关知识。
复习之前的知识点
相对熵
相对熵,又称互熵,交叉熵,鉴别信息,
设
- 相对熵可以度量两个随机变量的“距离”。
- 一般的,
D(p||q)≠D(q||p) 。 -
D(p||q)≥0,D(q||p)≥0 。
互信息
两个随机变量
- 显然当
X,Y 互相独立时,P(X,Y)=P(X)P(Y) 这个时候,X,Y 距离最短,互信息为零。
信息增益
信息增益表示得知特征
定义:特征
对于两个随机变量
-
H(Y|X)=H(X,Y)−H(X) -
H(Y|X)=H(Y)−I(X,Y) -
H(Y|X)<H(Y) -
H(X|Y)<H(X) -
I(X,Y)=H(X)+H(Y)−H(X,Y)
显然,这即为训练数据集
贝叶斯公式和最大后验估计
贝叶斯估计是一种生成式模型。所谓生成式和判别式模型的区别在于:
- 通过
P(y|x) 直接得出的模型称为判别式模型。 -
P(y|x) 是由P(x|y) 得出的模型叫做生成式模型,也就是在类别已知的情况下,样本是怎么生成出来的。
给定某些样本

- 第一个等式:贝叶斯公式;
- 第二个等式:样本给定,则对于任何
Ai,P(D) 是常数,即分母仅为归一化因子 - 第三个箭头:若这些结论
A1、A2……An 的先验概率相等 (或近似),即P(A1)=P(A2)=...P(An) , 则得到最后一个等式:即第二行的公式,这时候其实是转成了求最大似然估计。
朴素贝叶斯
朴素贝叶斯的假设
一个特征出现的概率,与其他特征(条件)独立 (特征独立性)
- 其实是:对于给定分类的条件下,特征独立
每个特征同等重要(特征均衡性)
朴素贝叶斯的推导
朴素贝叶斯(Naive Bayes,NB)是基于“特征之间是独立的”这一朴素假设,应用贝叶斯定理的监督学习 算法。
对于给定的特征向量
类别
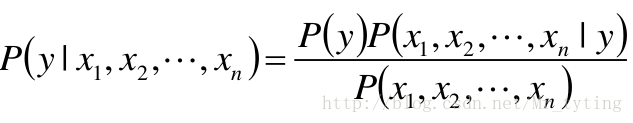
使用朴素的独立性 假设:
类别
在给定样本的前提下,
从而:
以上就是朴素贝叶斯通用化的推导,所有的朴素贝叶斯都可以这样推导出来。
根据样本使用
高斯朴素贝叶斯
根据样本使用
假设特征服从高斯分布,即:
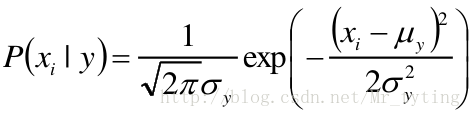
参数使用
多项分布朴素贝叶斯
假设特征服从多项分布,从而,对于每个类别y, 参数为
参数
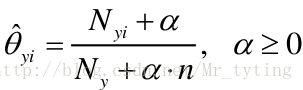
假定训练集为

其中:
-
α=1 称为Laplace 平滑。 -
α<1 称为Lidstone 平滑。 - 平滑操作除了避免出现零,还有增加模型的泛化能力的作用。
以文本分类为例
问题描述
- 样本:
1000 封邮件,每个邮件被标记为垃圾邮件或者非垃圾邮件 。 - 分类目标:给定第
1001 封邮件,确定它是垃圾邮件还是非垃圾邮件。 - 方法:朴素贝叶斯
问题分析
类别
词汇表,两种建立方法:
- 使用现成的单词词典;
- 将所有邮件中出现的单词都统计出来,得到词典。
记单词数目为
将每个邮件
若单词
贝叶斯公式:
特征条件独立假设 :
特征独立假设:
带入公式:
实际情况下,不需要考虑
等式右侧各项的含义:
-
P(xi|cj) :在cj (此题目,cj 要么为垃圾邮件1,要么为非垃圾邮件2)的前提下,第i 个单词xi 出现的概率 。 -
P(xi) :在所有样本中,单词xi 出现的概率。 -
P(cj) :在所有样本中,邮件类别cj 出现的概率。
由上面例子可以看出,朴素贝叶斯基于以下两条假设:
- 一个特征出现的概率,与其他特征(条件)独立(特征独立性),即是:对于给定分类的条件下,特征独立 。
- 每个特征同等重要(特征均衡性) 。
以上两条假设不一定正确,但是基于这两条假设的朴素贝叶斯在一些应用中效果却是不错的。
贝叶斯网络
把某个研究系统中涉及的随机变量,根据是否条件独立 绘制在一个有向图 中,就形成了贝叶斯网络。
贝叶斯网络(
一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,或隐变量、未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系(或非条件独立)。若两个节点间以一 个单箭头连接在一起,表示其中一个节点是“因
每个结点在给定其直接前驱时,条件独立 于其非后继。
一个简单的贝叶斯网络
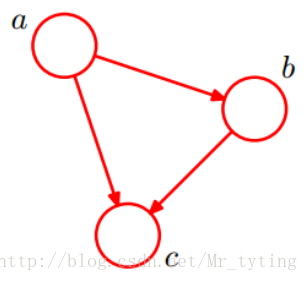
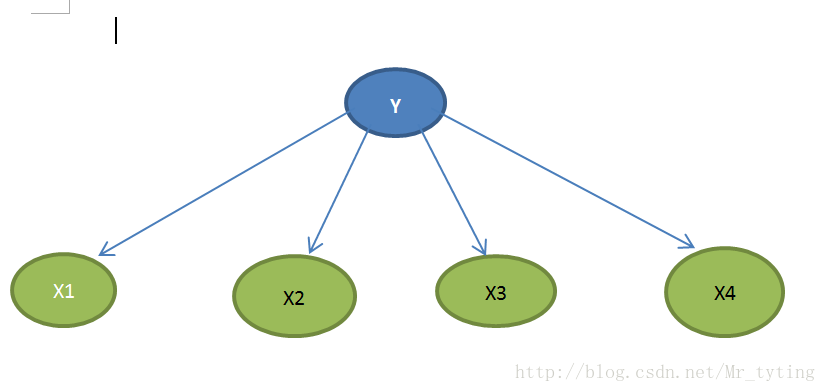
朴素贝叶斯就是把特征
全连接贝叶斯网络
每一对结点之间都有边连接:
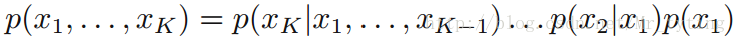
一个“正常”的贝叶斯网络:
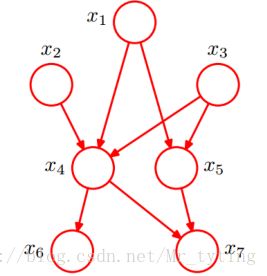
- 有些边缺失
直观上:
x1 和x2 独立
x6 和x7 在x4 给定的条件下独立x1,x2,…x7 的联合分布:
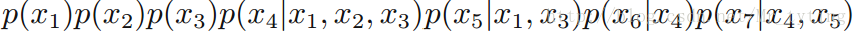
对一个实际贝叶斯网络的分析:
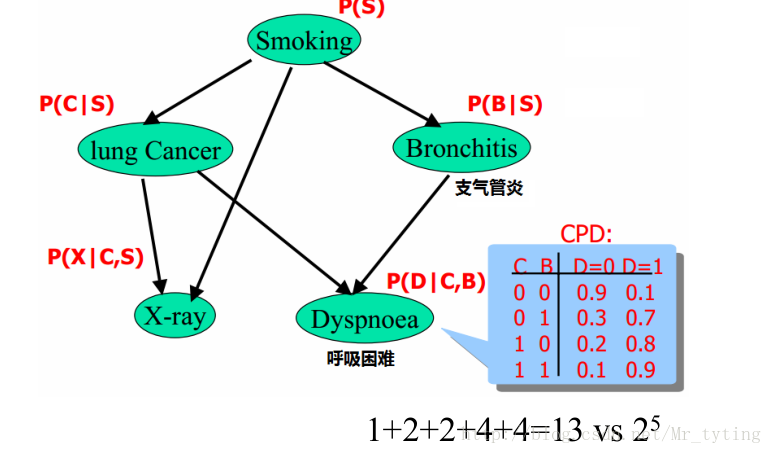
贝叶斯网络的形式化定义
- G:有向无环图
- G的结点:随机变量
- G的边:结点间的有向依赖
- Θ:所有条件概率分布的参数集合
- 结点
X 的条件概率:P(X|parent(X))

通过贝叶斯网络判定条件独立—1
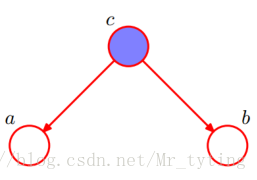
根据图模型,得:
从而:
因为
得:
即:在
通过贝叶斯网络判定条件独立—2
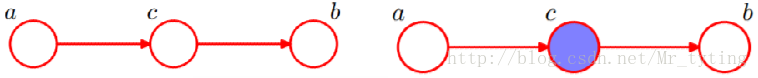
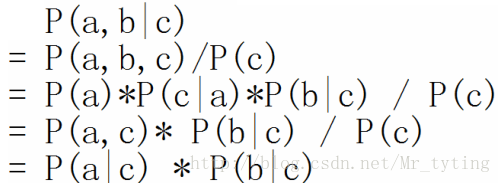
即:在
通过贝叶斯网络判定条件独立—3

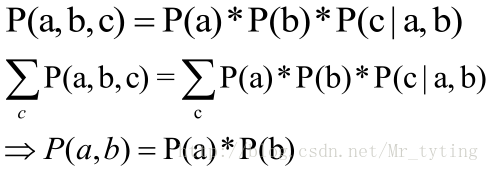
在
以上三种情况的举例说明:
