版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/88851206
贝叶斯算法用于做分类
例如你给[email protected]邮箱发送邮件 , 邮件发送过程中会先经过xx公司的服务器 , 我们可以根据关键词扫描之后做一个分类例如是垃圾邮件 , 然后做一个处理 , 删掉或者投递到用户的垃圾邮件分类里之类. 该场景中关键词的设定,可以由人来设定 , 但是很主观 , 我们就可以用贝叶斯算法建立模型来实现,通过训练来实现分类 .
又例如天气,70%降水概率 , 也同样是通过模型来计算的 , 以湿度,温度,压强,云朵,风等等的特征…
案例:使用朴素贝叶斯算法对邮件进行分类
首先是元数据的样式
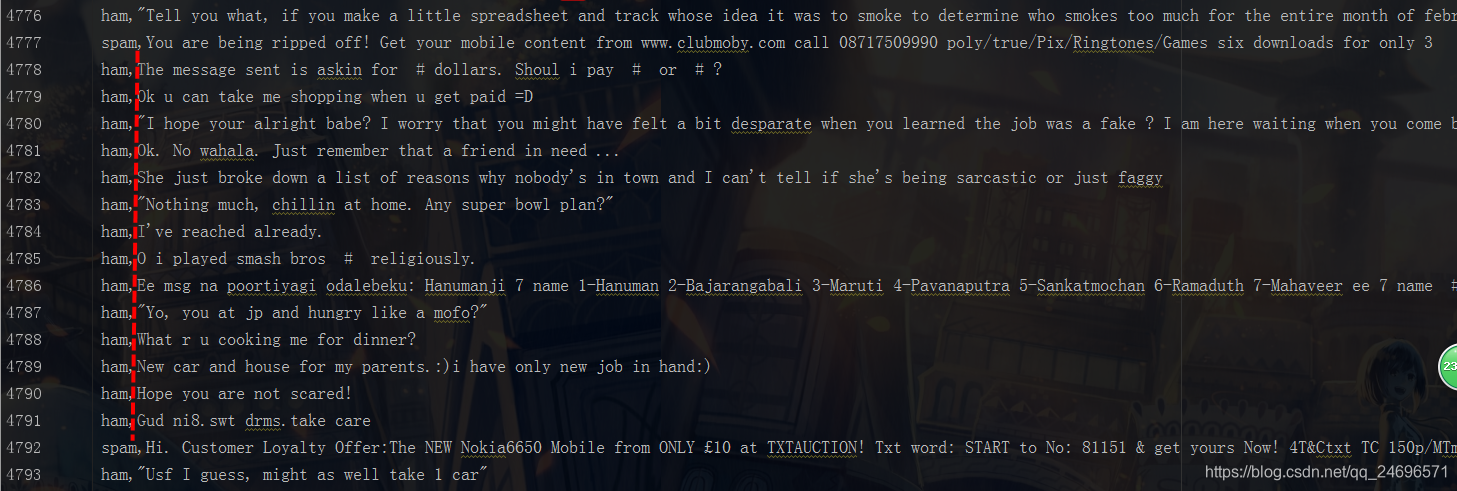
将数据分为两部分, 第一部分是邮件的判断 , spam是垃圾邮件,ham是正常邮件 , 其后是邮件的内容

package com.spark
import org.apache.spark.ml.classification.{NaiveBayes, NaiveBayesModel}
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2019/4/2.
*/
object Naive_bayes1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("emailFilter").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//读取数据
val idData: RDD[Array[String]] = sc.textFile("F:\\code02\\sparkLearn\\src\\sms_spam.txt").map(_.split(",")).cache() //以,将数据分为两部分
// 1.0是正常邮件0.0是垃圾邮件 , 邮件内容按" "切分后去空
val idDataRows: RDD[Row] = idData.map(x=> Row((if(x(0)=="ham")1.0 else 0.0),x(1).split(" ").map(_.trim)))
val schema = StructType(List(
StructField("label", DoubleType, nullable = false), //double类型,非空 , 正常邮件和垃圾邮件
StructField("words", ArrayType(StringType, true), nullable = false) //数组类型,单词string类型,非空 , 单词
))
val df = sqlContext.createDataFrame(idDataRows,schema)
//构建词袋 , CountVectorizer:构建词袋的类 , 根据df中的words数据来构建词袋
val countVectorizer: CountVectorizerModel = new CountVectorizer().setInputCol("words").setOutputCol("features").fit(df)
//查看词袋的词汇表, 只看前100个
countVectorizer.vocabulary.take(100).foreach(println)
//文本向量化 , 将邮件的内容对照词袋来向量化文本内容
val cvDF: DataFrame = countVectorizer.transform(df)
//查看一下
cvDF.show(false)
//正负例样本
val example = cvDF.drop("words") //使用向量数据来训练模型, 单词部分drop
example.show(10) //查看前十个
// 使用数据来训练 , 一部分数据训练 , 一部分测试 , 随机种子1234L
val Array(trainingData,testData) = example.randomSplit(Array(0.8,0.2),seed = 1234L)
// 训练朴素贝叶斯模型
val model: NaiveBayesModel = new NaiveBayes().fit(trainingData) //NaiveBayes:朴素贝叶斯模型对象 . fit() 放入8成数据用于训练
// 2成数据用于测试
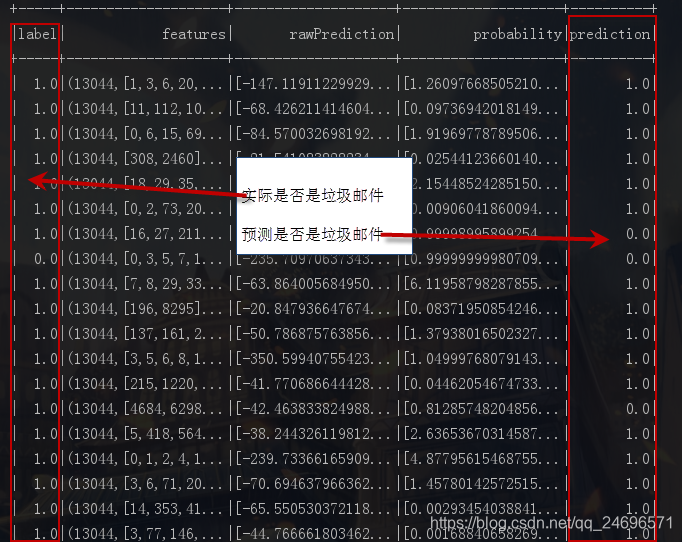
val predictions: DataFrame = model.transform(testData)
// 查看预测
predictions.show()
// 模型评估
predictions.registerTempTable("result") //注册成临时表
//计算正确率 , label是实际结果 , prediction是预测结果 , 垃圾邮件0.0,正常邮件1.0 实际结果-预测结果 , 0就是正确 , !0就是预测错误
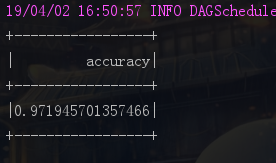
val accuracy: DataFrame = sqlContext.sql("select (1- (sum(abs(label-prediction)))/count(label)) as accuracy from result")
// 查看正确率
accuracy.show()
}
}
测试准确率