深度学习的”hello world“(【深度学习实战1】:基于Keras的手写数字识别(非常详细、代码开源))已经更新完了,会了手写数字识别就说明一只脚已经踏进了深度学习的大门!
今天博主带来第二个实战内容:基于Keras的cifar10图像分类。全是干货,文末附完整代码!
一、准备工作
| 设备\库 | 型号\版本 |
|---|---|
| 显卡 | GTX1650 |
| 驱动程序版本 | 457.49 |
| tensorflow-gpu版本 | 2.4.0 |
| keras版本 | 2.4.3 |
| Python版本 | 3.7.3 |
二、下载cifar10数据集
Keras已经对cifar10数据集做了集成,可以直接通过API下载与使用。
2.1 导入所需的库与模块
from keras.datasets import cifar10
import matplotlib.pyplot as plt
2.2 下载数据集
# x_train_original和y_train_original代表训练集的图像与标签, x_test_original与y_test_original代表测试集的图像与标签
(x_train_original, y_train_original), (x_test_original, y_test_original) = mnist.load_data()
下载好的数据集系统会存放在C盘用户下的.keras中的datasets文件夹下:
C:\Users\Lenovo\.keras\datasets
三、数据集预处理
3.1 图像标签可视化
我们需要知道cifar10数据集图像分别代表着什么,首先我们解压数据集压缩包,可以看到里面有一个batches.meta,这个文件里面包含了图像的部分信息;data_batch_1~5表示训练集的batch;test_batch表示测试集的batch。
我们定义下面这个函数可视化这些信息:
def load_file(filename):
with open(filename, 'rb') as datasets:
data = pickle.load(datasets)
return data
调用该函数:
data = load_file(r'C:\Users\Lenovo\.keras\datasets\cifar-10-batches-py\batches.meta')
我们打印data信息:
print(data.keys()) # 打印键名
print(data.values()) # 打印键值
输出结果为:
dict_keys(['num_cases_per_batch', 'label_names', 'num_vis'])
dict_values([10000, ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'], 3072])
从输出结果我们可以得到几个信息:
- 键名:每个Batch的训练集的图像数目,标签名字,单张图像的像素数量
- 键值:训练集的每个Batch中包含10000张图像;图像共有10个标签,分别为:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’;单张图像的像素数量为3072,这里的3072是由32×32×3得来的,因为图像的尺寸是(32×32×3),这里后续再说。
3.2 其他处理
接下来的预处理步骤包括:
- 图像可视化(单张图像可视化、多张图像可视化)
- 分配验证集(从数据集量上来看,建议将测试集的一半抽出做验证集)
- 图像数据预处理(类型转化:uint8类型转到float32类型;图像归一化)
- 图像标签预处理(编码方式转为独热编码)
详见程序utils.py
# -*- coding = utf-8 -*-
# @time:2021/11/28/0028 下午21:42
# Author:米开朗琪罗儿
# @File:utils.py
# @Software:PyCharm
# 程序介绍
"""
utils.py包含了对cifar10数据集的所有预处理过程及可视化过程
"""
"""
库导入
"""
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import pickle
from keras.utils import np_utils
"""
数据集下载与加载(利用KerasAPI)
"""
# x_train_original和y_train_original代表训练集的图像与标签, x_test_original与y_test_original代表测试集的图像与标签
(x_train_original, y_train_original), (x_test_original, y_test_original) = cifar10.load_data()
"""
打印数据集信息
"""
# 文件处理函数(可视化图像原始标签),调用该函数的位置在后续的函数load_data()中
def load_file(filename):
with open(filename, 'rb') as datasets:
data = pickle.load(datasets)
return data
"""
数据集图像可视化(调用这两个函数的部分在后续load_data()中)
"""
# 单张图像可视化(通过索引选择一张图像可视化)
# mode=0时,选择原始训练集的数据可视化,mode为其他时,选择原始测试集的数据可视化
def mnist_visualize_single(mode, idx):
if mode == 0:
plt.imshow(x_train_original[idx], cmap=plt.get_cmap('gray')) # 显示函数
title = 'label=' + str(y_train_original[idx]) # 标签名称(这里是原始编码的标签,即0~9)
plt.title(title)
plt.xticks([]) # 不显示x轴
plt.yticks([]) # 不显示y轴
plt.show() # 图像显示
else:
plt.imshow(x_test_original[idx], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_test_original[idx])
plt.title(title)
plt.xticks([]) # 不显示x轴
plt.yticks([]) # 不显示y轴
plt.show()
# 多张图像可视化
# 函数的start与end参数表示可视化从start开始,从end结束,例如start=4,end=8表示可视化索引为4、5、6、7的图像(注:以strat开始、以end-1结束)
# 函数的length与width参数表示绘图框显示图像的情况,例如length=3,width=3表示绘制一个3×3(共9个)的画板,画板用来放置可视化的图像
def mnist_visualize_multiple(mode, start, end, length, width):
if mode == 0:
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_train_original[i], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_train_original[i])
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
else:
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_test_original[i], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_test_original[i])
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
"""
分配验证集并可视化各部分数量
"""
def val_set_alloc():
# 原始原始数据集数据量
print('原始训练集图像的尺寸:', x_train_original.shape)
print('原始训练集标签的尺寸:', y_train_original.shape)
print('原始测试集图像的尺寸:', x_test_original.shape)
print('原始测试集标签的尺寸:', y_test_original.shape)
print('===============================')
# 验证集分配(从测试集中抽取,因为训练集数据量不够)
x_val = x_test_original[:5000]
y_val = y_test_original[:5000]
x_test = x_test_original[5000:]
y_test = y_test_original[5000:]
x_train = x_train_original
y_train = y_train_original
# 打印验证集分配后的各部分数据数据量
print('训练集图像的尺寸:', x_train.shape)
print('训练集标签的尺寸:', y_train.shape)
print('验证集图像的尺寸:', x_val.shape)
print('验证集标签的尺寸:', y_val.shape)
print('测试集图像的尺寸:', x_test.shape)
print('测试集标签的尺寸:', y_test.shape)
print('===============================')
return x_train, y_train, x_val, y_val, x_test, y_test
"""
图像数据与标签数据预处理
"""
def data_process(x_train, y_train, x_val, y_val, x_test, y_test):
# 这里把数据从unint类型转化为float32类型, 提高训练精度。
x_train = x_train.astype('float32')
x_val = x_val.astype('float32')
x_test = x_test.astype('float32')
# 原始图像的像素灰度值为0-255,为了提高模型的训练精度,通常将数值归一化映射到0-1。
x_train = x_train / 255
x_val = x_val / 255
x_test = x_test / 255
# 图像标签一共有10个类别即0-9,这里将其转化为独热编码(One-hot)向量
y_train = np_utils.to_categorical(y_train)
y_val = np_utils.to_categorical(y_val)
y_test = np_utils.to_categorical(y_test)
return x_train, y_train, x_val, y_val, x_test, y_test
"""
加载数据(即将上述定义的所有函数通过该函数进行整合,输出最终的图像数据与标签)
"""
def load_data():
# 打印数据集信息
data = load_file(r'C:\Users\Lenovo\.keras\datasets\cifar-10-batches-py\batches.meta')
print(data.keys()) # 打印键名
print(data.values()) # 打印键值
# 可视化图像数据
mnist_visualize_single(mode=0, idx=0)
mnist_visualize_multiple(mode=0, start=0, end=9, length=3, width=3)
# 验证集分配
x_train, y_train, x_val, y_val, x_test, y_test = val_set_alloc()
# 数据预处理(图像数据、标签数据)
x_train, y_train, x_val, y_val, x_test, y_test = data_process(x_train, y_train, x_val, y_val, x_test, y_test)
return x_train, y_train, x_val, y_val, x_test, y_test
if __name__ == '__main__':
load_data()
程序输出结果为:
dict_keys(['num_cases_per_batch', 'label_names', 'num_vis'])
dict_values([10000, ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'], 3072])
原始训练集图像的尺寸: (50000, 32, 32, 3)
原始训练集标签的尺寸: (50000, 1)
原始测试集图像的尺寸: (10000, 32, 32, 3)
原始测试集标签的尺寸: (10000, 1)
===============================
训练集图像的尺寸: (50000, 32, 32, 3)
训练集标签的尺寸: (50000, 1)
验证集图像的尺寸: (5000, 32, 32, 3)
验证集标签的尺寸: (5000, 1)
测试集图像的尺寸: (5000, 32, 32, 3)
测试集标签的尺寸: (5000, 1)
===============================


四、网络构建
4.1 常规卷积神经网络的构建
我们建立一个名为net.py的程序文件!
首先我们进行库函数导入:
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, BatchNormalization, Input, add, Dropout
from keras.utils.vis_utils import plot_model
import tensorflow as tf
import os
现在开始定义常规CNN,
关于激活函数的选取以及为何使用独热编码在程序中已经给出解释。
"""
常规CNN模型
"""
# 关于激活函数选取的说明:
# (1)卷积层选择”relu“激活函数:relu激活函数从某种角度上来说,是最好的激活函数,适用于众多场景,在卷积层上的表现十分优异,因为relu激活函数收敛速度很快,
# 梯度不会饱和,也就缓解了梯度消失的问题,且计算速度更快。而sigmoid激活函数与tanh激活函数,在正区间内曲线逐步区域平缓,几乎不存在梯度变化的情况,
# 这会引发网络梯度权重无法更新,导致网络无法训练,神经网络无法进入梯度最小值点,也就不存在网络最优值。
#(2)Dense最后一层选择"softmax"激活函数:这里激活函数的选择与数据集标签的编码方式相关,具体来说,数据集标签的编码方式是独热编码,独热编码表示一个
# 长度为10的序列,仅有0和1表示且仅有一个1,其他都是0,此外序列中1的位置=原始标签的值。
# 举例说明:一副图像的标签为4,则独热编码结果为0 0 0 0 1 0 0 0 0 0 ,在第4位上出现了1。
# softmax激活函数输出的是概率值,也就是说不管数据集有几类,最后所有类别的预测结果加和为1,那么在这些类别中的最高概率类别与独热编码的1出现的位置如果
# 相同就说明网络预测正确,那么网络可以按照这个梯度变化的情况继续训练,相反就更改训练方向。
# (3)综上:独热编码与softmax经常拿来一起用。
def conventional_model():
model = Sequential() # 采用序贯模型
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(32, 32, 3))) # 添加卷积层
model.add(BatchNormalization()) # 添加BN层防止过拟合
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) # 添加最大池化层:降采样、去除冗余信息、特征压缩、减少计算量、简化网络复杂度、增大非线性
model.add(Flatten()) # 添加平铺层,将特征图的神经元全部展开,用于后续的全连接层
model.add(Dense(256, activation='relu')) # 添加全连接层,开始进行特征整合与图像分类
model.add(Dropout(0.5)) # 为防止全连接层参数过多导致过拟合的产生,添加该层随机失活神经元
model.add(Dense(10, activation='softmax')) # 最后一层作为分类器,输出10个神经元
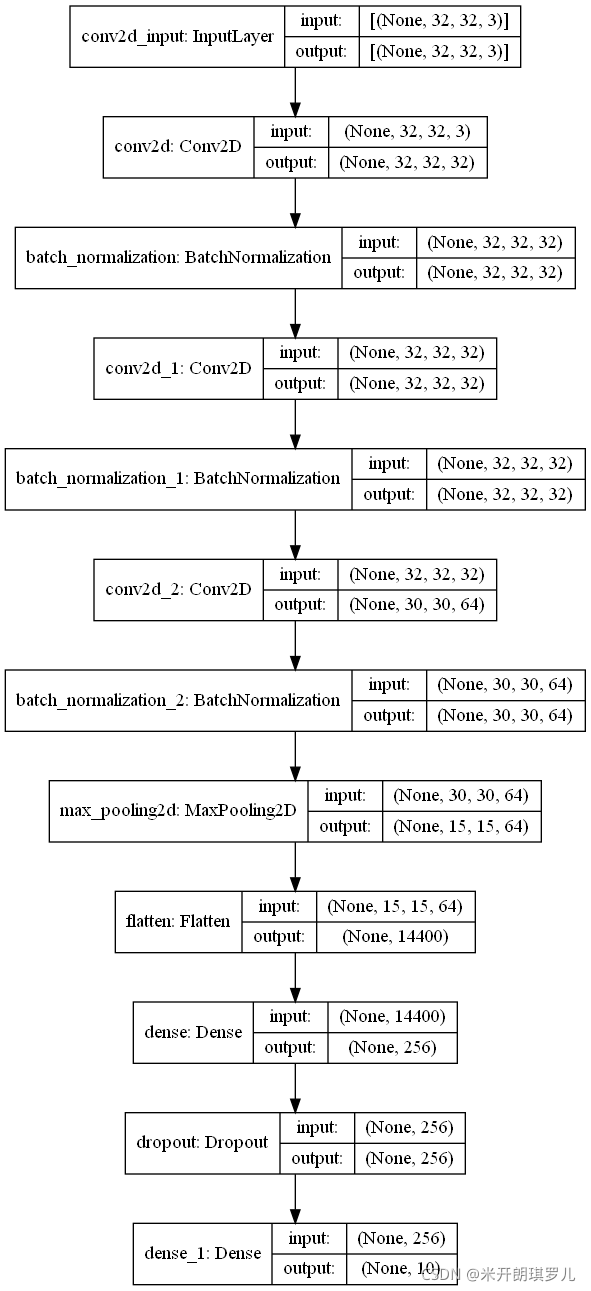
print(model.summary()) # 打印模型
# 模型结构图输出
plot_model(model, to_file='conventional_model.png', show_shapes=True, show_layer_names=True, rankdir='TB')
plt.figure(figsize=(10, 10))
img = plt.imread('conventional_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()
return model
if __name__ == '__main__':
conventional_model()
模型输出信息为:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
batch_normalization (BatchNo (None, 32, 32, 32) 128
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 32) 128
_________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 64) 18496
_________________________________________________________________
batch_normalization_2 (Batch (None, 30, 30, 64) 256
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 14400) 0
_________________________________________________________________
dense (Dense) (None, 256) 3686656
_________________________________________________________________
dropout (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 3,718,378
Trainable params: 3,718,122
Non-trainable params: 256
_________________________________________________________________
None
网络结构图为:
4.2 带残差结构的神经网络的构建
定义网络:
"""
带残差结构的CNN模型
"""
def res_model():
input_shape = Input(shape=(32, 32, 3))
x1 = Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu')(input_shape)
x1 = BatchNormalization()(x1)
x2 = Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu')(x1)
x2 = BatchNormalization()(x2)
add1 = add([x1, x2]) # 引入了一个跳跃连接,用于梯度更新,防止网络过深导致梯度弥散或爆炸
x3 = Conv2D(filters=64, kernel_size=(3, 3), activation='relu')(add1)
x3 = BatchNormalization()(x3)
x4 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x3)
x4 = Flatten()(x4)
x4 = Dense(256, activation='relu')(x4)
x4 = Dropout(0.5)(x4)
output = Dense(10, activation='softmax')(x4)
model = tf.keras.Model(input_shape, output)
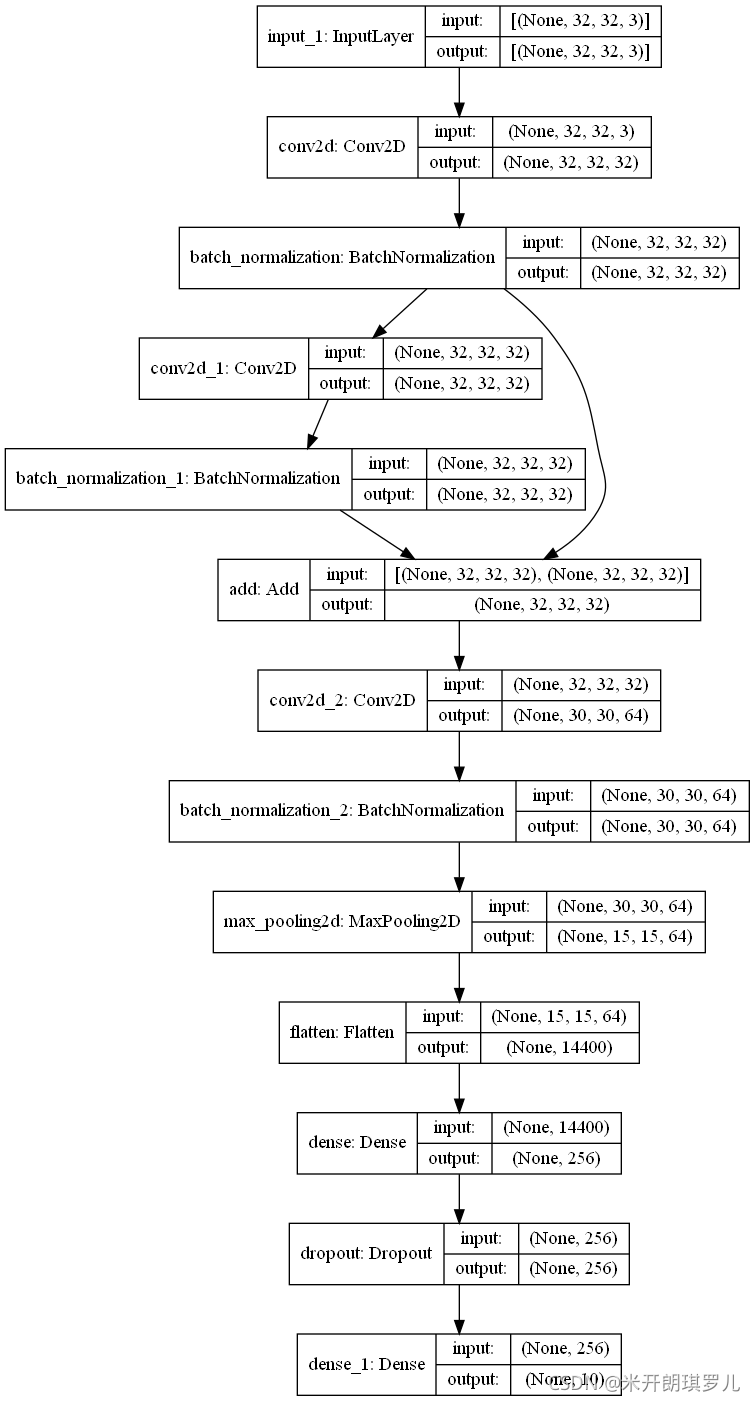
print(model.summary())
validity = model(input_shape)
plot_model(model, to_file='res_model.png', show_shapes=True, show_layer_names=True, rankdir='TB')
plt.figure(figsize=(10, 10))
img = plt.imread('res_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()
return Model(input_shape, validity)
if __name__ == '__main__':
res_model()
模型输出信息为:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 32) 896 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 32, 32, 32) 128 conv2d[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248 batch_normalization[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 32, 32, 32) 128 conv2d_1[0][0]
__________________________________________________________________________________________________
add (Add) (None, 32, 32, 32) 0 batch_normalization[0][0]
batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 64) 18496 add[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 30, 30, 64) 256 conv2d_2[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 64) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 14400) 0 max_pooling2d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 256) 3686656 flatten[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 256) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 10) 2570 dropout[0][0]
==================================================================================================
Total params: 3,718,378
Trainable params: 3,718,122
Non-trainable params: 256
__________________________________________________________________________________________________
None
模型结构图为:
后续我们会用这两个网络进行训练。
五、网络训练
网络训练这一part包含:
- 定义网络
- 编译网络
- 定义回调函数
- 定义训练过程可视化函数
- 训练网络
- 模型保存
import utils # 导入刚刚建立的预处理库
import net # 导入刚刚建立的网络模型库
from keras.callbacks import ReduceLROnPlateau, EarlyStopping
import matplotlib.pyplot as plt
import os
import datetime
# 下面两行表示调用CPU训练,如果要使用GPU,需要删除下面两行
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# 数据集加载
x_train, y_train, x_val, y_val, x_test, y_test = utils.load_data()
# 定义网络
conventional_model = net.conventional_model()
res_model = net.res_model()
# 编译网络(定义损失函数、优化器、评估指标)
conventional_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
res_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 定义学习率回调函数(监测验证集精度,根据所设参数,按照标准衰减学习率)
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=2, verbose=1, factor=0.3, min_lr=0.00000001)
print('当前学习率为:', learning_rate_reduction)
# 定义早停回调函数,当监测的验证集精度连续5次没有优化,则停止网络训练,保存现有模型
es = EarlyStopping(monitor='val_loss', patience=5)
# 回调函数联合
callback = [learning_rate_reduction, es]
# 定义训练过程可视化函数(训练集损失、验证集损失、训练集精度、验证集精度)
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
def train_model(model):
start_time = datetime.datetime.now()
# 开始网络训练(定义训练数据与验证数据、定义训练代数,定义训练批大小)
train_history = model.fit(x_train, y_train, validation_data=(x_val, y_val),
epochs=30, batch_size=32, verbose=2, callbacks=[callback])
elapsed_time = datetime.datetime.now() - start_time
print('训练时间:', elapsed_time)
# 模型保存
model.save('res_model.h5') # 根据要训练的网络自行修改.h5模型名称
show_train_history(train_history, 'accuracy', 'val_accuracy')
show_train_history(train_history, 'loss', 'val_loss')
if __name__ == '__main__':
train_model(res_model) # 选择要训练的网络
我们对带有残差结构的神经网络训练结果如下:
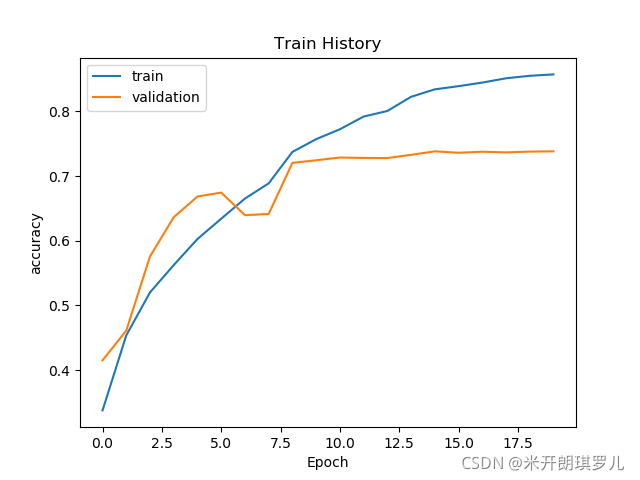
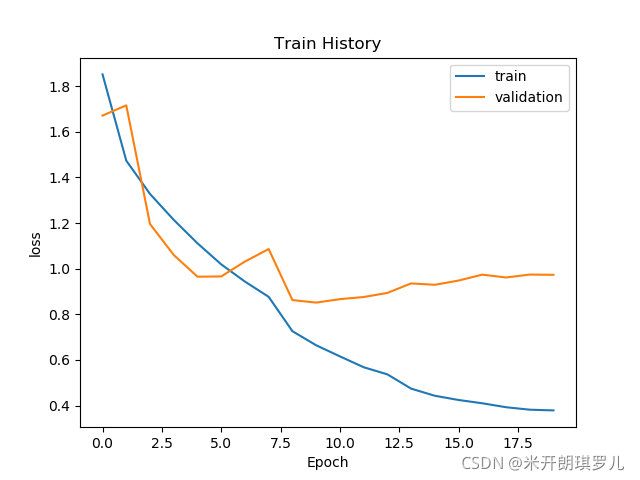
六、网络测试
在第五步中,我们已经训练好了两个网络并且保存了对应模型,接下来我们就可以保存好的模型进行测试。
在这一part中,有以下几个步骤:
- 加载原始数据集及预处理数据集
- 加载训练好的模型
- 定义预测函数
- 定义预测结果可视化函数
- 定义混淆矩阵
import utils
import matplotlib.pyplot as plt
import numpy as np
import keras
import pandas as pd
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 加载原始数据集及预处理数据集
x_train_original, y_train_original, x_val_original, y_val_original, x_test_original, y_test_original = utils.val_set_alloc()
x_train, y_train, x_val, y_val, x_test, y_test = utils.load_data()
# 加载训练好的深度学习模型
conventional_model = keras.models.load_model('conventional_model.h5')
res_model = keras.models.load_model('res_model.h5')
# 定义预测函数
def model_predict(model):
# 模型预测,score中包含预测结果的损失和精度
score = model.evaluate(x_test, y_test)
print('Test loss:', score[0]) # 打印测试集损失
print('Test accuracy:', score[1]) # 打印测试集精度
# 测试集结果预测(测试集的预测结果全部存放在predictions中)
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=1) # 将预测得到的独热编码转换为常规编码,即0 1 2 3 4 5 6 7 8 9
print('前20张图片预测结果:', predictions[:20])
return predictions
# 预测结果图像可视化
def mnist_visualize_multiple_predict(model, start, end, length, width):
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_test_original[i], cmap=plt.get_cmap('gray'))
title_true = 'true=' + str(y_test_original[i]) # 图像真实标签
title_prediction = ',' + 'prediction' + str(predictions[i]) # 预测结果
title = title_true + title_prediction
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
# 定义混淆矩阵
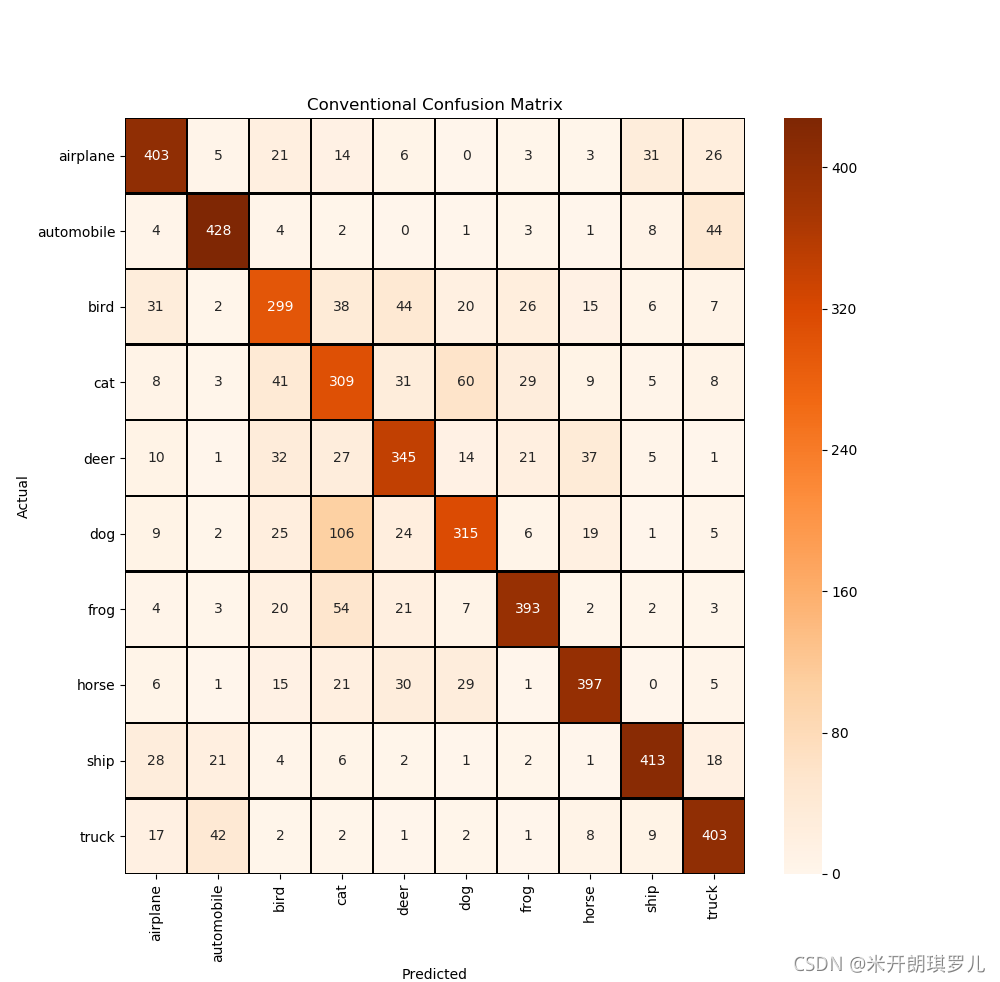
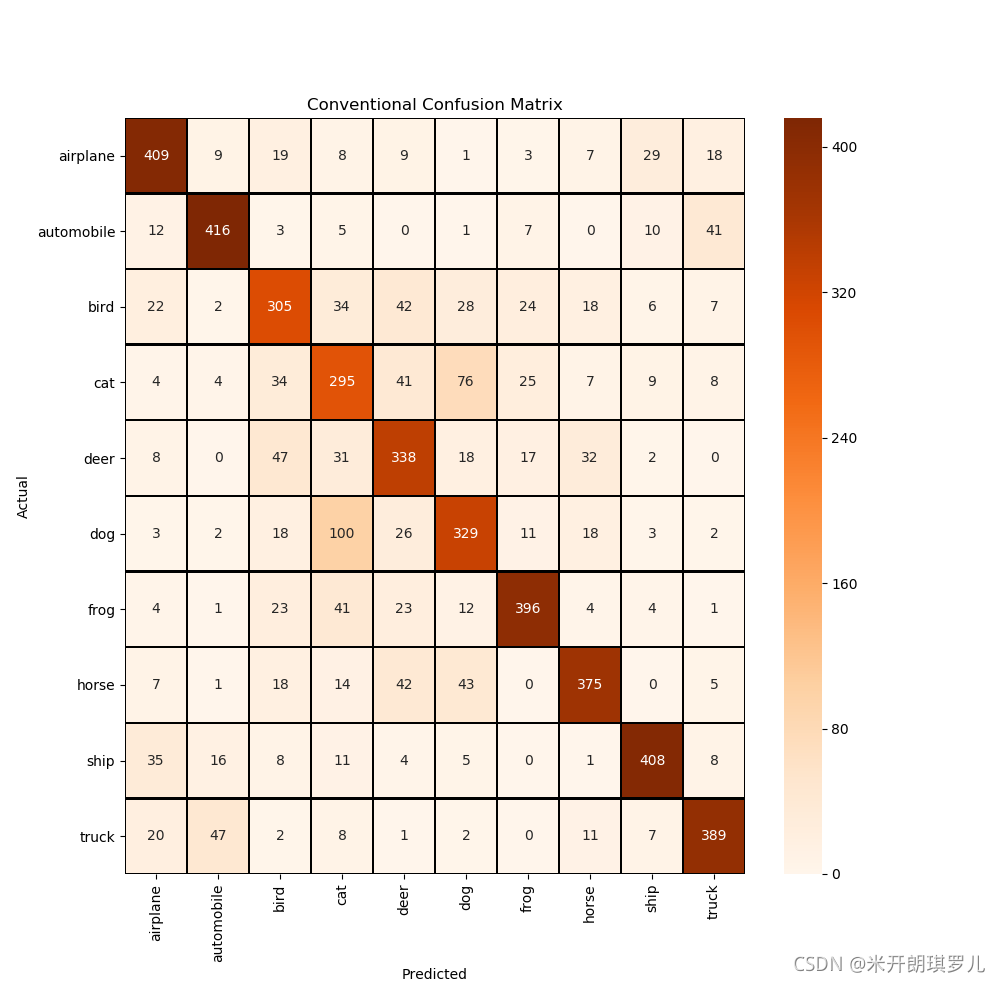
def confusion_matrix_visual(y_test_original, predictions):
cm = confusion_matrix(y_test_original, predictions)
cm = pd.DataFrame(cm)
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10, 10))
sns.heatmap(cm, cmap='Oranges', linecolor='black', linewidth=1, annot=True, fmt='', xticklabels=class_names,
yticklabels=class_names)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Conventional Confusion Matrix")
plt.show()
if __name__ == '__main__':
# 调用上面定义的各个函数
predictions = model_predict(conventional_model)
mnist_visualize_multiple_predict(conventional_model, start=0, end=9, length=3, width=3)
confusion_matrix_visual(y_test_original, predictions)
对常规CNN预测结果如下:
157/157 [==============================] - 3s 16ms/step - loss: 1.0221 - accuracy: 0.7410
Test loss: 1.0220750570297241
Test accuracy: 0.7409999966621399
前20张图片预测结果: [7 6 8 7 4 5 2 3 4 2 7 4 6 0 7 2 6 9 4 1]

对带有残差结构的CNN预测结果如下:
157/157 [==============================] - 3s 16ms/step - loss: 1.0507 - accuracy: 0.7320
Test loss: 1.050661563873291
Test accuracy: 0.7319999933242798
前20张图片预测结果: [7 6 8 4 4 5 3 3 4 2 7 4 6 2 7 2 6 7 4 1]

七、思考与分析
我们知道何凯明在2015年提出残差网络以来,极大的促进了深层神经网络的发展,这是因为残差结构可以防止网络过深引发的梯度弥散或梯度爆炸问题,那么为什么本实验加了一个跳跃连接,精度反而不如不加呢???
这是因为残差网络适用于深层网络的情况,而本文的网络仅有三层卷积,且卷积核数量不多,达不到 深 这一条件。此外,从网络训练过程图来看,网络在第 8 批次的时候,其实已经饱和了,这时候降低学习率,减少训练步长的操作也无法进一步优化神经网络了,此外增加的这一条跳跃连接会增大训练量,这反而会对网络起到消极效果!
综上,我们在设置网络时,不仅要考虑超参数的设置还要考虑网络在数据集上的承载力,跳跃连接一定要加在合理的地方!!!
那么我们如何进一步优化网络呢???
我们可以使用多尺度多分支网络,在网络浅层采用并联结构提取图像不同感受野的信息,可使用3×3、5×5卷积层,此外可以添加注意力机制,例如Se_Block或CBAM,但这里要注意,添加注意力时,要观察特征图焦点区域是否被注意力模块激活,如果没有被激活,说明注意力添加是无效的。
最后,cifar10的SOTA希望可以被你们打破!!!