1、任务介绍
- CIFAR-10和CIFAR-100是由Alex Krizhevsky, Vinod Nair和Geoffrey Hinton收集的图像分类数据集,其中CIFAR-10数据集包含60000张32x32彩色图像,分为10个类,每类有50000张训练图片和10000张测试图片,如下图。

- CIFAR-10常用来作为一个网络性能的指标,方便不同的分类网络之间进行对比。其官网下载链接如下,下载速度可能较慢,可能需要科学工具:
CIFAR-10官网
我们下载python版本的数据:

2、解析数据
-
我们下载下来的CIFAR-10数据是单个的batch文件,如下图:
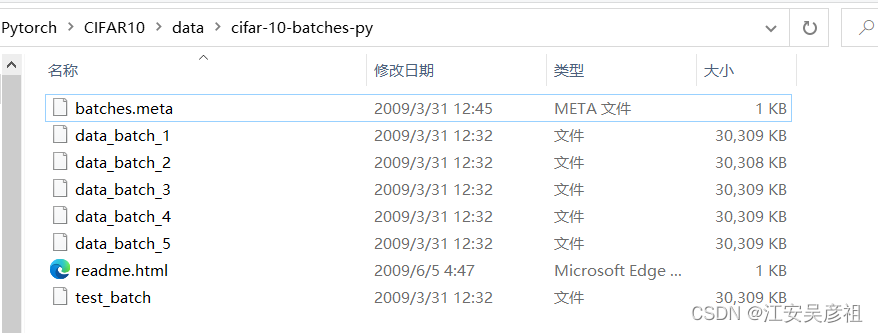
每个batch文件中包含10000张图片。其中data_batch_1这些是训练数据,其中包含了10个类,每个类1000张,而test_batch则是测试数据,包含10个类,每个类1000张图片。
-
这些图片我们无法直接通过电脑进行浏览,因此我们首先需要将其解析成方便电脑浏览的JPG格式数据。当测试训练好的网络时,一定要看原始图片,找其中的原因,所以必须有能够直接浏览的图片数据。
-
官网上给了解析数据的API如下,其解析后得到的类型是python的dict类型:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
- 我们在文件夹下新建一个CIFAR10.py文件,并将整个文件夹通过vscode打开,输入快捷键:
ctrl + shift + p
再输入
python:select
选择python的解释器如下:

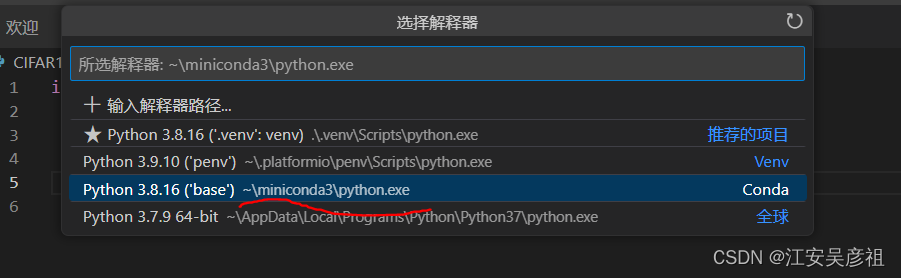
选择好minicoda下面的解释器后,就可以引入torch库了,不报错,如下:

由于在解析图片数据时需要用到opencv库,因此我们使用conda安装opencv,执行命令:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
如下图:

此时在vscode中执行
import cv2
不报错,说明opencv安装成功。 - 接下来我们写以下代码,打印出原始文件中的信息:
import torch
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i, in file_list,file_list:
print(file_i)
mydict = unpickle(file_i)
print(mydict)
可运行得以下结果,此时我们已经获得了CIFAR-10的训练文件的文件名,并通过解码函数将训练文件解码到了一个字典数据中,通过将字典数据打印出来,发现每个batch文件中都包含了很多个图片数据:
通过追加下面两条命令,可以看到解码得到的字典中都包含什么:
print(mydict.keys())
print(len(mydict))
运行得:

由以上信息可得每个batch文件中将图片作为字典存储,每个字典的键值key包含图片的标签类别、数据、文件名、batch标签共4个信息类别,而字典的值是列表,包含了图片中各个类别的信息。
通过以下命令可打印出字典中labels包含哪些信息
print(mydict[b'labels'])
print(type(mydict[b'labels']))
print(len(mydict[b'labels']))
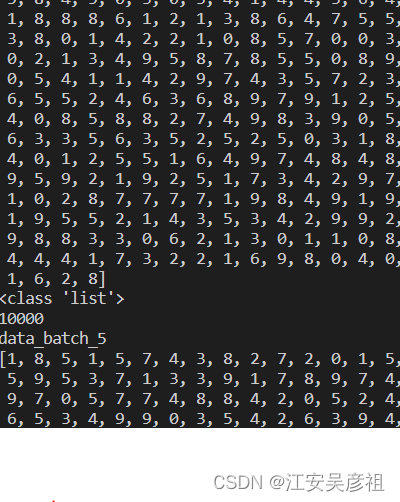
可见labels键值下存储的是列表数据,列表长度是1000,列表中包含了图片的类别编号0-9,0-9编号就是下图中的10个类:
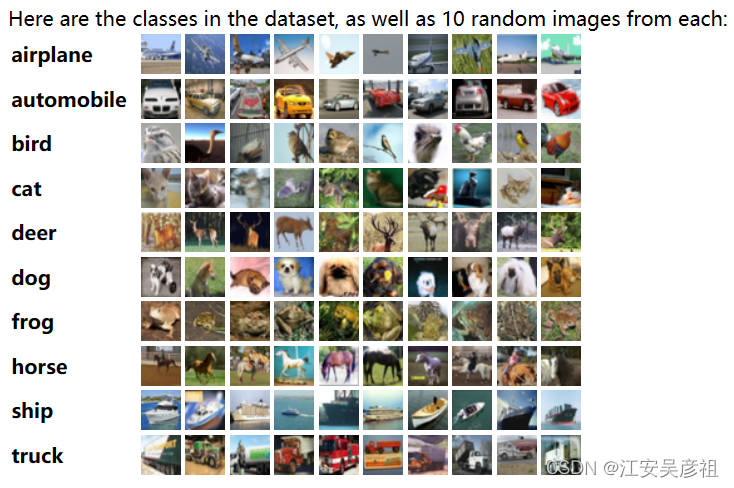
因此我们可以将每个batch文件解码得到的很多个字典数据,按照字典的labels,分类的放在各个文件夹下面,并通过cv2的show将图片显示出来,我们追加以下代码。
mydict = unpickle(file_i)
for index_i in range(1000):
print(label_name[mydict[b'labels'][index_i]])
print(mydict[b'data'][index_i])
print(mydict[b'filenames'][index_i])
上述代码可以打印出字典中列表对应的图片信息如下,
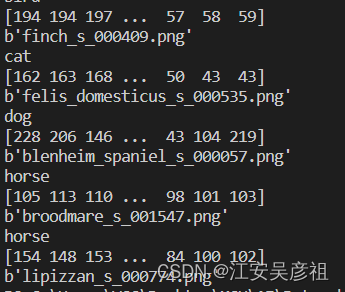
由信息可见图片信息被保存为了数组,我们打印数组信息:
print(type(mydict[b'data'][0]))

可见图片信息被保存为了n维数组,我们引入numpy,通过以下代码观察数组信息:
mydict = unpickle(file_i)
print(mydict[b'data'][0].shape)

可见数组被保存为了30721的数组,3072刚好是32323数据长度,其中3232是图片的大小,3是每个像素点的RGB信息长度,因此我们可以通过numpy的reshape将数组恢复为图片的数据。
mydict = unpickle(file_i)
img_a = mydict[b'data'][0].reshape(32,32,3)
print(img_a)
得:
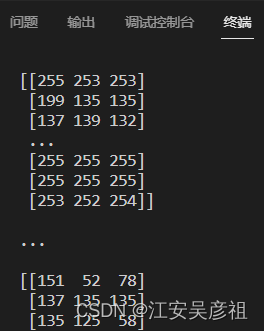
我们先以一个图像为例,将图像显示出来:
import torch
import cv2
import numpy as np
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i in file_list:
print(file_i)
mydict = unpickle(file_i)
print(mydict[b'data'][0])
img_a = mydict[b'data'][0].reshape(3,32,32) / 255 # CIFAR10数据集在将32*32*3图像拉伸为一维数组时,
# 依次存放1024个R,1024个G,1014个B数据,将其reshape为(3,32,32),则一共有3层,第一层全是R,第二层全是G,第三层全是B
img_a = np.transpose(img_a,(1,2,0)) # 翻转数据,将三层的RGB作为图像的深度
print(img_a)
cv2.imshow("wcc",img_a)
userkey = cv2.waitKey()
运行以上代码后,效果如下:
按一下按键打印一张图片,并显示图片数据。我们这里就完成了单个图片数据的解析,下面我们只需要修改代码,将其按标签保存在不同的文件夹里即可,完整代码如下:
import torch
import cv2
import numpy as np
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
import os
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i in file_list:
print(file_i)
mydict = unpickle(file_i)
for index_i in range(10000):
img_a = mydict[b'data'][index_i].reshape(3,32,32)# CIFAR10数据集在将32*32*3图像拉伸为一维数组时,
# # 依次存放1024个R,1024个G,1014个B数据,将其reshape为(3,32,32),则一共有3层,第一层全是R,第二层全是G,第三层全是B
#由于imwrite时会自动做一次归一化/255,因此这里不除以255进行归一化
img_a = np.transpose(img_a,(1,2,0)) # 翻转数据,将三层的RGB作为图像的深度
label_a = label_name[mydict[b'labels'][index_i]]
a_name = mydict[b'filenames'][index_i]
a_name = a_name.decode("utf8")
# print("IMG_Train/{}/{}".format(label_a,a_name))
if not os.path.exists("IMG_Train/{}".format(label_a)):
os.mkdir("IMG_Train/{}".format(label_a))
cv2.imwrite("IMG_Train/{}/{}".format(label_a,a_name),img_a)
如下:
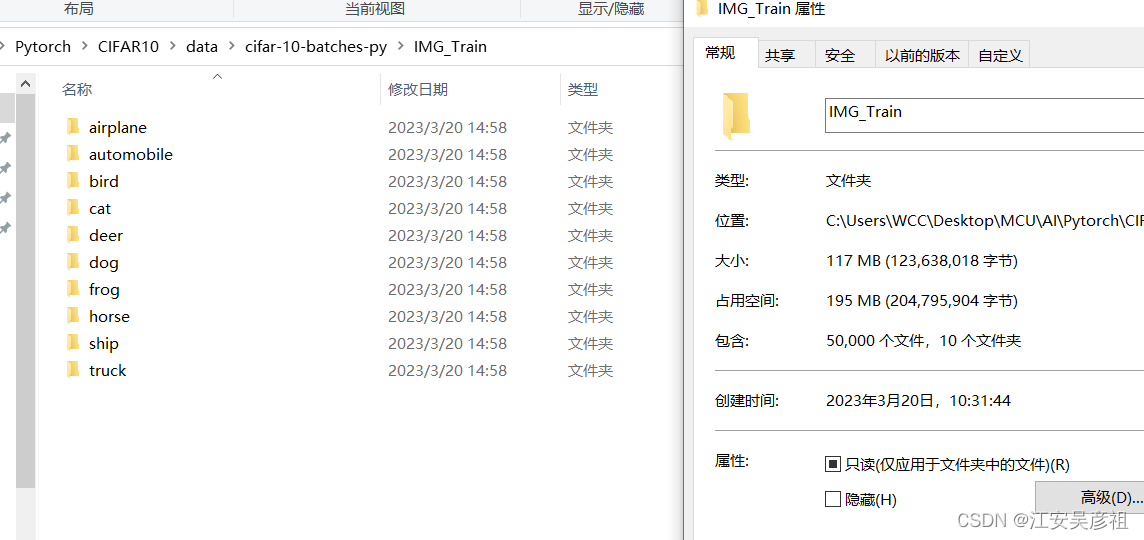
共解析出了50000个数据。
同理,可将10000个测试数据解析出来。