cifar10数据集下载位置:http://www.cs.toronto.edu/~kriz/cifar.html
首先下载数据:


Cifar10数据打包和数据读取:
目录结构:

convert_cifar10_image.py
#对数据进行处理
import urllib
import os
import sys
import tarfile
import glob
import pickle
import numpy as np
import cv2
#下载数据集
def download_and_uncompress_tarball(tarball_url, dataset_dir):
"""Downloads the `tarball_url` and uncompresses it locally.
Args:
tarball_url: The URL of a tarball file.#数据下载的url
dataset_dir: The directory where the temporary files are stored.#存储数据的路径
"""
filename = tarball_url.split('/')[-1]
filepath = os.path.join(dataset_dir, filename)
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (
filename, float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(tarball_url, filepath, _progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dataset_dir)
classification = ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
#解析文件
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
DATA_DIR = 'data'#将下载好的数据存放到data文件夹中。
#download_and_uncompress_tarball(DATA_URL, DATA_DIR)
#指定文件夹的路径
folders = 'data/cifar-10-batches-py'
#获取训练集所有的文件
trfiles = glob.glob(folders + "/data_batch*")
#每一个数据有data和标签label
data = []
labels = []
for file in trfiles:
dt = unpickle(file)
data += list(dt[b"data"])
labels += list(dt[b"labels"])
print(labels)
imgs = np.reshape(data, [-1, 3, 32, 32])
for i in range(imgs.shape[0]):
im_data = imgs[i, ...]
im_data = np.transpose(im_data, [1, 2, 0])
#数据通道按照RGB
im_data = cv2.cvtColor(im_data, cv2.COLOR_RGB2BGR)
f = "{}/{}".format("data/image/train", classification[labels[i]])
#判断文件夹是否存在
if not os.path.exists(f):
os.mkdir(f)
#相应类别下写入文件
cv2.imwrite("{}/{}.jpg".format(f, str(i)), im_data)
writer_cifar10.py#写入到TFRecord
import tensorflow as tf
import cv2
import numpy as np
classification = ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
import glob
idx = 0#指向当前遍历到第几个类别
im_data = []#图片的数据
im_labels = []#图片的labels
#遍历10个类别
for path in classification:
path = "data/image/train/" + path
im_list = glob.glob(path + "/*")
im_label = [idx for i in range(im_list.__len__())]
idx += 1
im_data += im_list
im_labels += im_label
print(im_labels)
print(im_data)
tfrecord_file = "data/train.tfrecord"
writer = tf.python_io.TFRecordWriter(tfrecord_file)
#洗牌,将数据打乱
index = [i for i in range(im_data.__len__())]
np.random.shuffle(index)
for i in range(im_data.__len__()):
im_d = im_data[index[i]]
im_l = im_labels[index[i]]
#对图片进行数据的读取
data = cv2.imread(im_d)
#data = tf.gfile.FastGFile(im_d, "rb").read()
ex = tf.train.Example(
features = tf.train.Features(
feature = {
"image":tf.train.Feature(
bytes_list=tf.train.BytesList(
value=[data.tobytes()])),
"label": tf.train.Feature(
int64_list=tf.train.Int64List(
value=[im_l])),
}
)
)
writer.write(ex.SerializeToString())
writer.close()
将上述代码中,data/image/train 改为data/image/test
data/train.tfrecord改为data/test.tfrecord
在执行一次,将测试数据集进行处理,转化成tfrecord。
读取cifar10文件(三个小例子:)
reader_cifar10-1.py
#从列表中读取数据:
import tensorflow as tf
images = ['image1.jpg', 'image2.jpg', 'image3.jpg', 'image4.jpg']
labels = [1, 2, 3, 4]
[images, labels] = tf.train.slice_input_producer([images, labels],
num_epochs=None,
shuffle=True)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(8):
print(sess.run([images, labels]))

reader_cifar10-2.py#从csv文件中读取:
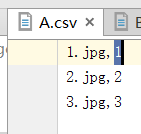

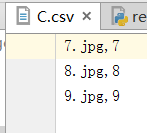
import tensorflow as tf
filename = ['data/A.csv', 'data/B.csv', 'data/C.csv']
file_queue = tf.train.string_input_producer(filename,
shuffle=True,
num_epochs=2)
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(6):
print(sess.run([key, value]))
reader_cifar10.py#对打包成TFRecord的数据进行读取
import tensorflow as tf
filelist = ['data/train.tfrecord']
file_queue = tf.train.string_input_producer(filelist,
num_epochs=None,
shuffle=True)
reader = tf.TFRecordReader()
_, ex = reader.read(file_queue)
#对序列化后的数据进行解码
feature = {
'image':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64)
}
batchsize = 2
batch = tf.train.shuffle_batch([ex], batchsize, capacity=batchsize*10,
min_after_dequeue=batchsize*5)
example = tf.parse_example(batch, features=feature)
image = example['image']
label = example['label']
image = tf.decode_raw(image, tf.uint8)
image = tf.reshape(image, [-1, 32, 32, 3])
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(1):
image_bth, _ = sess.run([image,label])
import cv2
cv2.imshow("image", image_bth[0,...])
cv2.waitKey(0)
运行结果:

Cifar10图片分类任务
目录结构:
将上面处理好的TFRecord文件放入data中。
model文件夹用来存放训练的模型。

readcifar10.py#读取TFRecord文件:
import tensorflow as tf
def read(batchsize=64, type=1, no_aug_data=1):
reader = tf.TFRecordReader()
if type == 0: #train从训练集中读取
file_list = ["data/train.tfrecord"]
if type == 1: #test从测试数据集中读取
file_list = ["data/test.tfrecord"]
#读取文件数据
filename_queue = tf.train.string_input_producer(
file_list, num_epochs=None, shuffle=True
)
_, serialized_example = reader.read(filename_queue)
batch = tf.train.shuffle_batch([serialized_example], batchsize, capacity=batchsize * 10,
min_after_dequeue= batchsize * 5)
feature = {'image': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)}
features = tf.parse_example(batch, features = feature)
images = features["image"]
img_batch = tf.decode_raw(images, tf.uint8)
img_batch = tf.cast(img_batch, tf.float32)
img_batch = tf.reshape(img_batch, [batchsize, 32, 32, 3])
#通过数据增强,使样本量丰富,提高模型泛化能力
if type == 0 and no_aug_data == 1:
#随机裁剪
distorted_image = tf.random_crop(img_batch,
[batchsize, 28, 28, 3])
#随机对比度
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.8,
upper=1.2)
distorted_image = tf.image.random_hue(distorted_image,
max_delta=0.2)
distorted_image = tf.image.random_saturation(distorted_image,
lower=0.8,
upper=1.2)
#对处理过的图像进行取值范围的约束
img_batch = tf.clip_by_value(distorted_image, 0, 255)
img_batch = tf.image.resize_images(img_batch, [32, 32])
label_batch = tf.cast(features['label'], tf.int64)
#-1,1
img_batch = tf.cast(img_batch, tf.float32) / 128.0 - 1.0
#
return img_batch, label_batch
train.py
#构建网络并训练
import tensorflow as tf
import readcifar10
import os
import resnet
slim = tf.contrib.slim
#定义模型
def model(image, keep_prob=0.8, is_training=True):
#参数
batch_norm_params = {
"is_training": is_training,
"epsilon":1e-5,#防止归一化除0
"decay":0.997,#衰减系数
'scale':True,
'updates_collections':tf.GraphKeys.UPDATE_OPS
}
with slim.arg_scope(
[slim.conv2d],
weights_initializer = slim.variance_scaling_initializer(),
activation_fn = tf.nn.relu,#激活函数
weights_regularizer = slim.l2_regularizer(0.0001),#采用l2正则
normalizer_fn = slim.batch_norm,
normalizer_params = batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding="SAME"):
#定义卷积层
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
#第二个卷积为第一个卷积的输出
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
#池化层
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
net = tf.reduce_mean(net, axis=[1, 2]) #nhwc--n11c
net = slim.flatten(net)
#全连接层
net = slim.fully_connected(net, 1024)
#dropout层,对神经元正则化
slim.dropout(net, keep_prob)
net = slim.fully_connected(net, 10)
return net #10维向量
#交叉熵损失函数
def loss(logits, label):
#对label进行one hot编码
one_hot_label = slim.one_hot_encoding(label, 10)
slim.losses.softmax_cross_entropy(logits, one_hot_label)
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
l2_loss = tf.add_n(reg_set)
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
return totalloss, l2_loss
#定义优化器
def func_optimal(batchsize, loss_val):
global_step = tf.Variable(0, trainable=False)
lr = tf.train.exponential_decay(0.01,
global_step,
decay_steps= 50000// batchsize,#衰减步长
decay_rate= 0.95,
staircase=False)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
op = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
return global_step, op, lr
#训练
def train():
batchsize = 64
#日志存放目录
floder_log = 'logdirs-resnet'
#model存放路径
floder_model = 'model-resnet'
if not os.path.exists(floder_log):
os.mkdir(floder_log)
if not os.path.exists(floder_model):
os.mkdir(floder_model)
tr_summary = set()
te_summary = set()
##data
tr_im, tr_label = readcifar10.read(batchsize, 0, 1)#训练样本,数据增强
te_im, te_label = readcifar10.read(batchsize, 1, 0)
##net
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3],
name='input_data')
input_label = tf.placeholder(tf.int64, shape=[None],
name='input_label')
keep_prob = tf.placeholder(tf.float32, shape=None,
name='keep_prob')
is_training = tf.placeholder(tf.bool, shape=None,
name='is_training')
logits = resnet.model_resnet(input_data, keep_prob=keep_prob, is_training=is_training)
#logits = model(input_data, keep_prob=keep_prob, is_training=is_training)
##loss
total_loss, l2_loss = loss(logits, input_label)
tr_summary.add(tf.summary.scalar('train total loss', total_loss))
tr_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
te_summary.add(tf.summary.scalar('train total loss', total_loss))
te_summary.add(tf.summary.scalar('test l2_loss', l2_loss))
##accurancy
pred_max = tf.argmax(logits, 1)
correct = tf.equal(pred_max, input_label)
accurancy = tf.reduce_mean(tf.cast(correct, tf.float32))
tr_summary.add(tf.summary.scalar('train accurancy', accurancy))
te_summary.add(tf.summary.scalar('test accurancy', accurancy))
##op
global_step, op, lr = func_optimal(batchsize, total_loss)
tr_summary.add(tf.summary.scalar('train lr', lr))
te_summary.add(tf.summary.scalar('test lr', lr))
tr_summary.add(tf.summary.image('train image', input_data * 128 + 128))
te_summary.add(tf.summary.image('test image', input_data * 128 + 128))
with tf.Session() as sess:
sess.run(tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer()))
tf.train.start_queue_runners(sess=sess,
coord=tf.train.Coordinator())
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
ckpt = tf.train.latest_checkpoint(floder_model)
if ckpt:
saver.restore(sess, ckpt)
epoch_val = 100
tr_summary_op = tf.summary.merge(list(tr_summary))
te_summary_op = tf.summary.merge(list(te_summary))
summary_writer = tf.summary.FileWriter(floder_log, sess.graph)
for i in range(50000 * epoch_val):
train_im_batch, train_label_batch = \
sess.run([tr_im, tr_label])
feed_dict = {
input_data:train_im_batch,
input_label:train_label_batch,
keep_prob:0.8,
is_training:True
}
_, global_step_val, \
lr_val, \
total_loss_val, \
accurancy_val, tr_summary_str = sess.run([op,
global_step,
lr,
total_loss,
accurancy, tr_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(tr_summary_str, global_step_val)
if i % 100 == 0:
print("{},{},{},{}".format(global_step_val,
lr_val, total_loss_val,
accurancy_val))
if i % (50000 // batchsize) == 0:
test_loss = 0
test_acc = 0
for ii in range(10000//batchsize):
test_im_batch, test_label_batch = \
sess.run([te_im, te_label])
feed_dict = {
input_data: test_im_batch,
input_label: test_label_batch,
keep_prob: 1.0,
is_training: False
}
total_loss_val, global_step_val, \
accurancy_val, te_summary_str = sess.run([total_loss,global_step,
accurancy, te_summary_op],
feed_dict=feed_dict)
summary_writer.add_summary(te_summary_str, global_step_val)
test_loss += total_loss_val
test_acc += accurancy_val
print('test:', test_loss * batchsize / 10000,
test_acc* batchsize / 10000)
if i % 1000 == 0:
saver.save(sess, "{}/model.ckpt{}".format(floder_model, str(global_step_val)))
return
if __name__ == '__main__':
train()这个位置可以更改用于训练的模型。

resnet.py
import tensorflow as tf
slim = tf.contrib.slim
def resnet_blockneck(net, numout, down, stride, is_training):
batch_norm_params = {
'is_training': is_training,
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(0.0001),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
shortcut = net
if numout != net.get_shape().as_list()[-1]:
shortcut = slim.conv2d(net, numout, [1, 1])
if stride != 1:
shortcut = slim.max_pool2d(shortcut, [3, 3],
stride=stride)
net = slim.conv2d(net, numout // down, [1, 1])
net = slim.conv2d(net, numout // down, [3, 3])
net = slim.conv2d(net, numout, [1, 1])
if stride != 1:
net = slim.max_pool2d(net, [3, 3], stride=stride)
net = net + shortcut
return net
def model_resnet(net, keep_prob=0.5, is_training = True):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
net = resnet_blockneck(net, 128, 4, 2, is_training)
net = resnet_blockneck(net, 128, 4, 1, is_training)
net = resnet_blockneck(net, 256, 4, 2, is_training)
net = resnet_blockneck(net, 256, 4, 1, is_training)
net = resnet_blockneck(net, 512, 4, 2, is_training)
net = resnet_blockneck(net, 512, 4, 1, is_training)
net = tf.reduce_mean(net, [1, 2])
net = slim.flatten(net)
net = slim.fully_connected(net, 1024, activation_fn=tf.nn.relu, scope='fc1')
net = slim.dropout(net, keep_prob, scope='dropout1')
net = slim.fully_connected(net, 10, activation_fn=None, scope='fc2')
return net
test.py
import tensorflow as tf
slim = tf.contrib.slim
import readcifar10
import os
def model_fn_v1(net,keep_prob=0.5, is_training = True):
batch_norm_params = {
'is_training': is_training,
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
endpoints = {}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(0.0001),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
net = slim.conv2d(net, 32, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv1')
net = slim.conv2d(net, 32, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv2')
endpoints["conv2"] = net
net = slim.max_pool2d(net, [3, 3], stride=2, scope="pool1")
net = slim.conv2d(net, 64, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv3')
net = slim.conv2d(net, 64, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv4')
endpoints["conv4"] = net
net = slim.max_pool2d(net, [3, 3], stride=2, scope="pool2")
net = slim.conv2d(net, 128, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv5')
net = slim.conv2d(net, 128, [3, 3], activation_fn=None, normalizer_fn=None, scope='conv6')
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
net = slim.flatten(net)
net = slim.dropout(net, keep_prob, scope='dropout1')
net = slim.fully_connected(net, 10, activation_fn=None, scope='fc2')
endpoints["fc"] = net
return net
def resnet_blockneck(net, kernel_size, down, stride, is_training):
batch_norm_params = {
'is_training': is_training,
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
shortcut = net
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(0.0001),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
if kernel_size != net.get_shape().as_list()[-1]:
shortcut = slim.conv2d(net, kernel_size, [1, 1])
if stride != 1:
shortcut = slim.max_pool2d(shortcut, [3, 3], stride=stride, scope="pool1")
net = slim.conv2d(net, kernel_size // down, [1, 1])
net = slim.conv2d(net, kernel_size // down, [3, 3])
if stride != 1:
net = slim.max_pool2d(net, [3, 3], stride=stride, scope="pool1")
net = slim.conv2d(net, kernel_size, [1, 1])
net = net + shortcut
return net
def model_fn_resnet(net, keep_prob=0.5, is_training = True):
with slim.arg_scope([slim.conv2d, slim.max_pool2d], padding='SAME') as arg_sc:
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
net = slim.conv2d(net, 64, [3, 3], activation_fn=tf.nn.relu)
net = resnet_blockneck(net, 128, 4, 2, is_training)
net = resnet_blockneck(net, 128, 4, 1, is_training)
net = resnet_blockneck(net, 256, 4, 2, is_training)
net = resnet_blockneck(net, 256, 4, 1, is_training)
net = resnet_blockneck(net, 512, 4, 2, is_training)
net = resnet_blockneck(net, 512, 4, 1, is_training)
#net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
net = slim.flatten(net)
net = slim.fully_connected(net, 1024, activation_fn=tf.nn.relu, scope='fc1')
net = slim.dropout(net, keep_prob, scope='dropout1')
net = slim.fully_connected(net, 10, activation_fn=None, scope='fc2')
return net
def model(image, keep_prob=0.5, is_training=True):
batch_norm_params = {
"is_training": is_training,
"epsilon": 1e-5,
"decay": 0.997,
'scale': True,
'updates_collections': tf.GraphKeys.UPDATE_OPS
}
with slim.arg_scope(
[slim.conv2d],
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=tf.nn.relu,
weights_regularizer=slim.l2_regularizer(0.0001),
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
net = slim.conv2d(image, 32, [3, 3], scope='conv1')
net = slim.conv2d(net, 32, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
net = slim.conv2d(net, 64, [3, 3], scope='conv3')
net = slim.conv2d(net, 64, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool2')
net = slim.conv2d(net, 128, [3, 3], scope='conv5')
net = slim.conv2d(net, 128, [3, 3], scope='conv6')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool3')
net = slim.conv2d(net, 256, [3, 3], scope='conv7')
net = tf.reduce_mean(net, axis=[1, 2]) # nhwc--n11c
net = slim.flatten(net)
net = slim.fully_connected(net, 1024)
net = slim.dropout(net, keep_prob)
net = slim.fully_connected(net, 10)
return net # 10 dim vec
def func_optimal(loss_val):
with tf.variable_scope("optimizer"):
global_step = tf.Variable(0, trainable=False)
lr = tf.train.exponential_decay(0.0001, global_step,
decay_steps=10000,
decay_rate=0.99,
staircase=True)
# ##更新 BN
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss_val, global_step)
return optimizer, global_step, lr
def loss(logist, label):
one_hot_label = slim.one_hot_encoding(label, 10)
slim.losses.softmax_cross_entropy(logist, one_hot_label)
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
l2_loss = tf.add_n(reg_set)
slim.losses.add_loss(l2_loss)
totalloss = slim.losses.get_total_loss()
return totalloss, l2_loss
def train_net():
batchsize = 128
floder_name = "logdirs"
no_data = 1
if not os.path.exists(floder_name):
os.mkdir(floder_name)
images_train, labels_train = readcifar10.read_from_tfrecord_v1(batchsize, 0, no_data)
images_test, labels_test = readcifar10.read_from_tfrecord_v1(batchsize, 1)
input_data = tf.placeholder(tf.float32, shape=[None, 32, 32, 3], name="input_224")
input_label = tf.placeholder(tf.int64, shape=[None], name="input_label")
is_training = tf.placeholder(tf.bool, shape=None, name = "is_training")
keep_prob = tf.placeholder(tf.float32, shape=None, name= "keep_prob")
logits = model(input_data, keep_prob=keep_prob)
softmax = tf.nn.softmax(logits)
pred_max = tf.argmax(softmax, 1)
correct_pred = tf.equal(input_label, pred_max)
accurancy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
total_loss, l2_loss = loss(logits, input_label)
# one_hot_labels = slim.one_hot_encoding(input_label, 10)
# slim.losses.softmax_cross_entropy(logits, one_hot_labels)
#
# reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# l2_loss = tf.add_n(reg_set)
# slim.losses.add_loss(l2_loss)
# total_loss = slim.losses.get_total_loss()
#如果使用了自己定义的loss,而又想使用slim的loss管理机制,可以使用:
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
update_op, global_step, learning_rate = func_optimal(total_loss)
summaries_train = set()
summaries_test = set()
# summaries.add(tf.summary.image("train image", tf.cast(images_train, tf.uint8)))
summaries_train.add(tf.summary.scalar('train_total_loss', total_loss))
summaries_train.add(tf.summary.scalar('train_l2_loss', l2_loss))
summaries_test.add(tf.summary.scalar('test_total_loss', total_loss))
summaries_train.add(tf.summary.scalar('learning rate', learning_rate))
summaries_train.add(tf.summary.image("image_train", images_train *128 + 128))
summaries_test.add(tf.summary.image("image_test", images_test * 128 + 128))
sess_config = tf.ConfigProto()
sess_config.gpu_options.allow_growth = True
with tf.Session(config=sess_config) as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
tf.train.start_queue_runners(sess=sess, coord=coord)
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
ckpt = tf.train.latest_checkpoint(floder_name)
summary_writer = tf.summary.FileWriter(floder_name, sess.graph)
summary_train_op = tf.summary.merge(list(summaries_train))
summary_test_op = tf.summary.merge(list(summaries_test))
#
#
if ckpt:
print("Model restored...",ckpt)
saver.restore(sess, ckpt)
for itr in range(1000000):
train_images, train_label = sess.run([images_train, labels_train])
train_feed_dict = {input_data: train_images,
input_label: train_label,
is_training: True, keep_prob: 1.0}
_, global_step_val ,accurancy_val, learning_rate_val, loss_val, pred_max_val, summary_str = \
sess.run([update_op, global_step, accurancy, learning_rate, total_loss, pred_max, summary_train_op], feed_dict=train_feed_dict)
summary_writer.add_summary(summary_str, global_step_val)
if itr % 100 == 0:
print("itr:{}, train acc: {},total_loss: {}, lr: {}".format(itr, accurancy_val,loss_val, learning_rate_val))
test_images, test_label = sess.run([images_test, labels_test])
test_feed_dict = {input_data: test_images,
input_label: test_label,
is_training: False,
keep_prob: 1.0}
accurancy_val, pred_max_val, summary_str = \
sess.run([accurancy, pred_max, summary_test_op],
feed_dict=test_feed_dict)
summary_writer.add_summary(summary_str, global_step_val)
print("itr:{}, test acc: {}, lr: {}".format(itr,accurancy_val,
learning_rate_val))
print(test_label)
print(pred_max_val)
if itr % 100 == 0:
saver.save(sess, "{}/model.ckpt".format(floder_name) + str(global_step_val), global_step=1)
if __name__ == '__main__':
print("begin..")
train_net()