【本系列博文是学习 Keras 的笔记,Keras 版本为2.1.5,主要的参考资料为:Keras中文文档】
上一节中,我们对 CIFAR-10 的 CNN 分类进行试验,识别率在 75% 左右,效果不是很好。这一节,我们将 BatchNormalization 加入到我们的网络中。识别率 提升了 10% 左右。
BatchNormalization层
BatchNormalization(axis=-1, momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer='zeros',
gamma_initializer='ones',
moving_mean_initializer='zeros',
moving_variance_initializer='ones',
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None)该层在每个batch上将前一层的激活值重新规范化,即使得其输出数据的均值接近0,其标准差接近1。
参数:
- axis: 整数,指定要规范化的轴,通常为特征轴。例如在进 data_format = “channels_first” 的 2D 卷积后,一般会设axis=1,默认为 -1,”channels_last”
- momentum: 动态均值的动量
- epsilon:大于 0 的小浮点数,用于防止除0错误
- center: 若设为 True,将会将 beta 作为偏置加上去,否则忽略参数 beta
- scale: 若设为 True,则会乘以 gamma,否则不使用 gamma。当下一层是线性的时,可以设 False,因为 scaling 的操作将被下一层执行。
- beta_initializer:beta 权重的初始方法
- gamma_initializer: gamma 的初始化方法
- moving_mean_initializer: 动态均值的初始化方法
- moving_variance_initializer: 动态方差的初始化方法
- beta_regularizer: 可选的 beta 正则
- gamma_regularizer: 可选的 gamma 正则
- beta_constraint: 可选的 beta 约束
- gamma_constraint: 可选的 gamma 约束
BN层的作用
- 加速收敛 ,允许使用较大的学习率
- 控制过拟合,可以少用或不用Dropout和正则
- 降低网络对初始化权重不敏感
测试
原则上 BatchNormalization() 可以放在任意层,我们这里将 BatchNormalization() 紧挨卷积层的后面。
... ...
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
... ...
model.add(Dense(512))
model.add(BatchNormalization())测试发现, 当使用 Dropout 层时,BatchNormalization 几乎不起任何作用,当去掉 Dropout 层后,识别率大幅上升。但是 BatchNormalization 层防止过拟合的能力是不行的。如下图所示,随着训练次数的增加,误差在训练集上逐步减小,但是在测试集上精度不再提高,出现了过拟合。
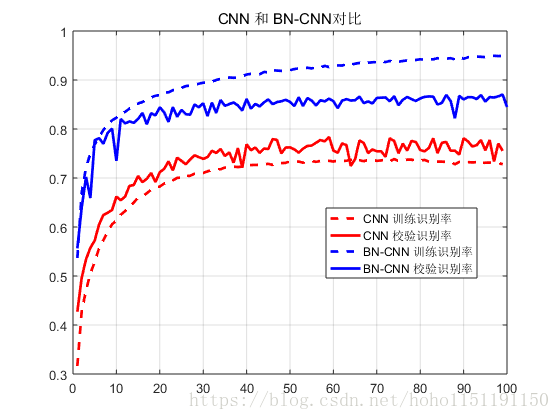
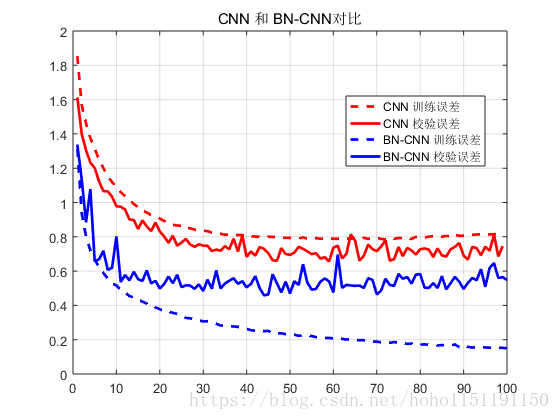
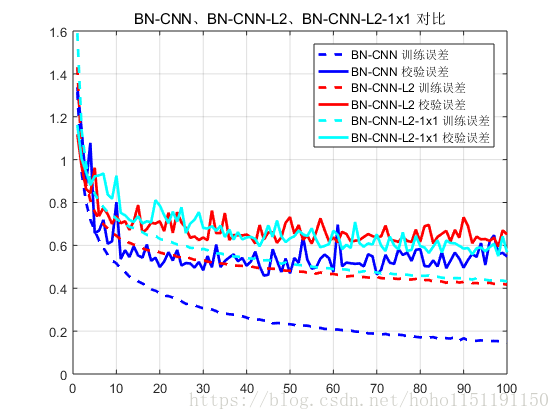
为了防止过拟合,又尝试将 L2 正则化加上(BN-CNN-L2曲线),过拟合得到抑制,然后添加在pooling 层又加上了个 1 1 的卷积层(BN-CNN-L2-1x1曲线),下面是对比

加上 BatchNormalization 层后的识别率能达到 86% 左右,可以采用小权值的L2正则化防止过拟合。
本节代码可在这里下载到。(没有积分的同学可私信我)
2018/4/12 更新:加深了一下网络,网络结构调整为
——————-conv3 32——————
——————-conv3 64——————
———– ——maxpooling—————-
——————conv3 128—————–
——————conv3 256—————–
——————conv3 512—————–
—————–maxpooling—————-
分类精度和误差见下图:
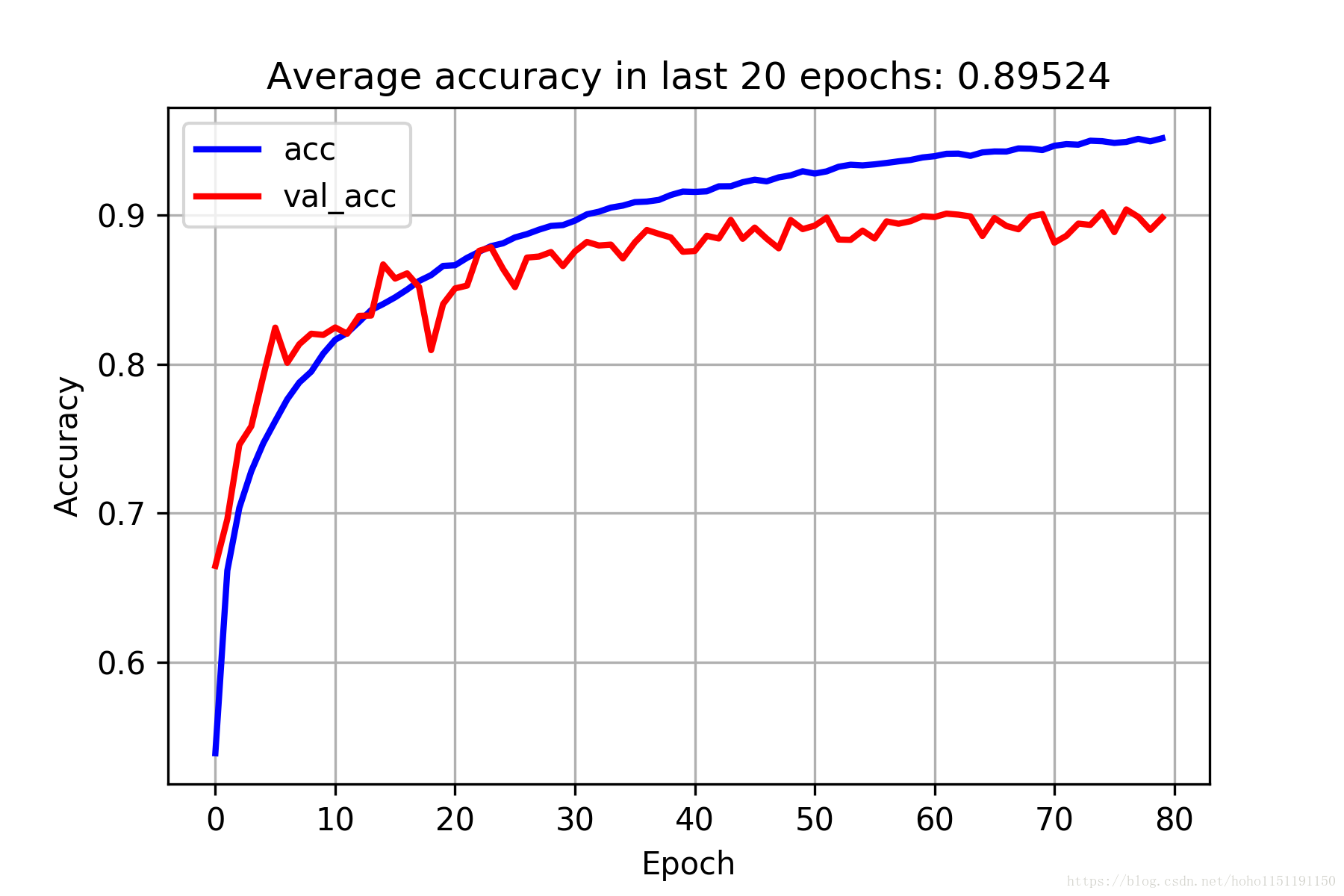
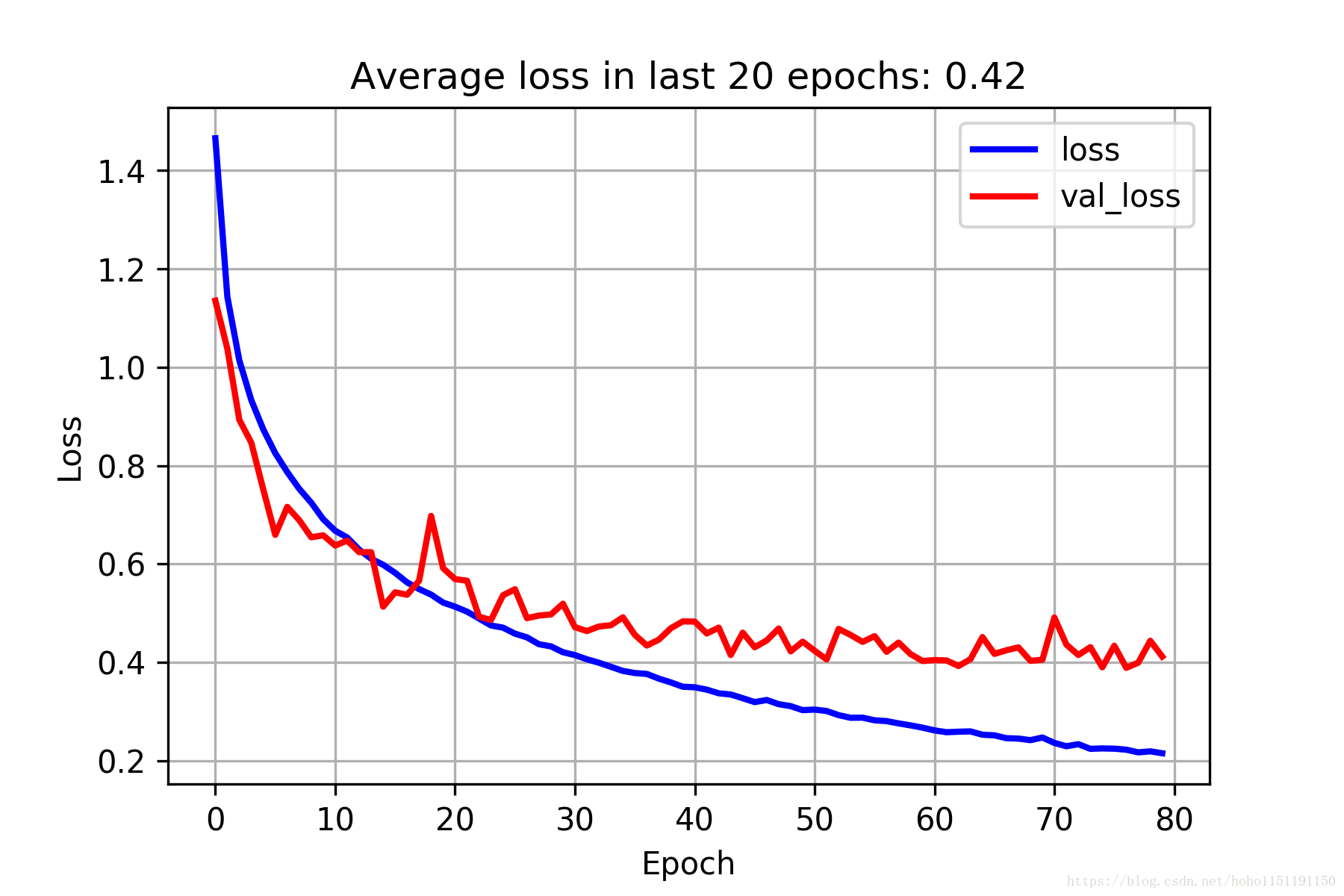
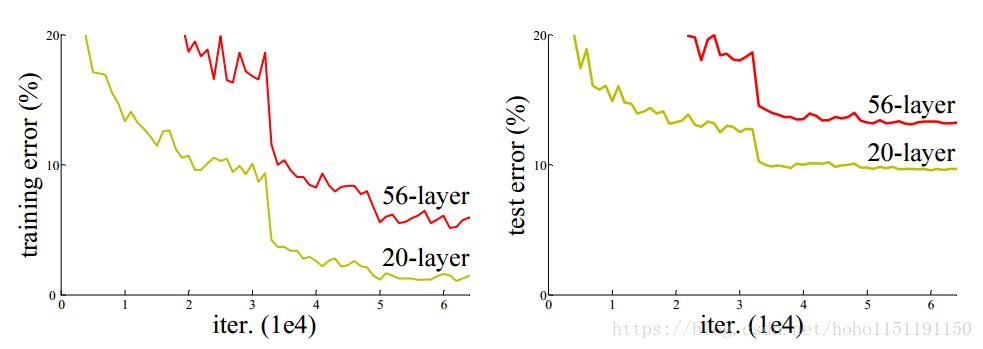
2018/4/16 更新:即使我们简单地继续增加卷积层的层数,其准确率基本不会提高了,下面是《Deep Residual Learning for Image Recognition》论文中关于CIFAR-10的20层和56层CNN测试,左侧是训练误差,右边是测试误差,精度基本在90%左右,很难再有提升了。