文章目录
第一节:transformer的架构介绍 + 输入部分的实现
链接:https://editor.csdn.net/md/?articleId=124648718
第二节 编码器部分实现(一)
链接:https://editor.csdn.net/md/?articleId=124648718
第三节 编码器部分实现(二)
链接:https://editor.csdn.net/md/?articleId=124724264
第四节 编码器部分实现(三)
链接:https://editor.csdn.net/md/?articleId=124746022
第五节 解码器部分实现
链接:https://editor.csdn.net/md/?articleId=124750632
第六节 输出部分实现+ 完整模型搭建
链接:https://editor.csdn.net/md/?articleId=124757450
第七节 模型的基本运行
1 模型基本测试运行——copy任务
- 了解 Transformer 模型基本测试的copy任务
- copy任务的四部曲:
(1)构建数据生成器
(2)获得Transformer模型 及其优化器和损失函数
(3)运行模型,进行训练和评估train+val
(4)使用模型进行 贪婪解码
# 构建数据生成器
def data_generator(V, batch_size, num_batch):
# 随机生成数据的最大值=1, 假设V=101, 生成的数据是 1-100
# batch_size : 每次喂给模型的样本数量
# num_batch ;一共喂模型 多少轮
for i in range(num_batch):
# 使用numpy中的random.randint()来随机生产 [1, V)
# 分布的形状是 (batch, 10)
data = torch.from_numpy(np.random.randint(1, V, size=(batch_size, 10)))
# 将数据的一列全部设置为1, 作为起始标志
data[:, 0] = 1
# 因为是copy任务,所以源数据和目标数据完全一致
# 设置参数 requires_grad=False,样本的参数不需要参与梯度的计算
source = Variable(data, requires_grad=False)
target = Variable(data, requires_grad=False)
yield Batch(source, target)
2 介绍优化器和损失函数
-
导入优化器工具包
get_std_opt, 是标准针对transformer模型的优化器;
该优化器基于Adam优化器,对序列的任务更有效 -
导入标签平滑工具包
LabelSmoothing就是小幅度的改变原有便签的值域;
防止过拟合 -
导入损失计算工具包,
SimpleLossCompute
2.1 优化器和损失函数的代码
- 注意:需要
pip install pyitcast在命令行里面执行这句代码就好了。
from pyitcast.transformer_utils import Batch
from pyitcast.transformer_utils import get_std_opt
from pyitcast.transformer_utils import LabelSmoothing
from pyitcast.transformer_utils import SimpleLossCompute
from pyitcast.transformer_utils import run_epoch
from pyitcast.transformer_utils import greedy_decode
V = 11
batch_size = 20
num_batch = 30
# 首先使用make_model()函数 生成模型的实例化对象
model = make_model(V, V, N=2)
# 使用工具包 get_std-opt 获得模型的优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing 获得标签平滑对象
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用工具包 SimpleLossCompute 获得利用标签平滑的结果,得到损失计算方法
loss = SimpleLossCompute(model.generator, criterion, model_optimizer)
2.2 介绍 标签平滑函数
2.2.1 理论知识
- 在多分类任务中,神经网络会输出一个当前数据 对应于 哥哥类别的置信度分数,将这些分数通过 softmax进行归一化处理,最终会得到当前数据属于每个类别的概率。
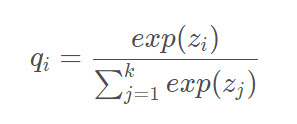
然后计算交叉熵损失函数:
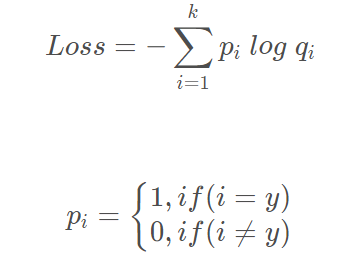
训练神经网络时,Min( 预测概率和标签真实概率之间的交叉熵 ) ,从而得到最优的预测概率分布。
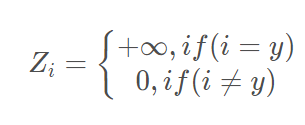
神经网络会促使自身往正确的标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。
labelsmoothing 是一种正则化策略,通过加入噪声,减少真是样本标签的类别在计算损失函数时的权重,最终起到过拟合的效果。 使得网络有更强的泛化能力!
2.2.2 具体的参数以及代码展示
- 一般设置
padding_idx=0, 这表示不需要将tensor中的数字转化成0,这也是最常用的方法; smothing=x: 假如原来标签的表示值为1,那么经过平滑之后,它的值域就变成[1-smothing, 1+smothing]
from pyitcast.transformer_utils import LabelSmoothing
import matplotlib.pyplot as plt
from torch.autograd import Variable
import torch
crit = LabelSmoothing(size=5, padding_idx=0, smoothing=0.5)
predict = Variable(torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]]))
target = Variable(torch.LongTensor([2, 1, 0]))
crit(predict, target)
print(crit.true_dist)
plt.imshow(crit.true_dist)
plt.show()
- 输出:
tensor([[0.0000, 0.1667, 0.5000, 0.1667, 0.1667],
[0.0000, 0.5000, 0.1667, 0.1667, 0.1667],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
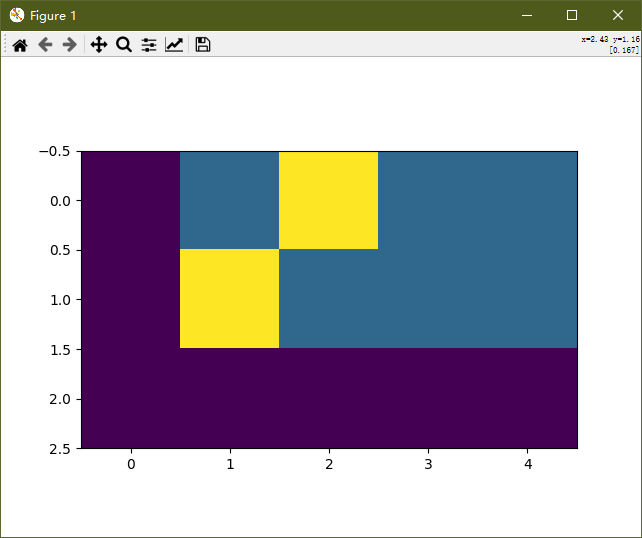
- 图像分析:
重点关注黄色区域,它的横坐标横跨的值域就是标签平滑后的正向平滑值域,[0.5, 2.5]
他的纵坐标横跨的值域就是标签平滑后的负向平滑值域,[-0.5, 1.5]
总的值域空间,由原来的[0, 2] 变成了 [-0.5, 2.5], 也就是因为我们的 smooth=0.5
2.3 训练和预测
# 首先使用make_model()函数 生成模型的实例化对象
model = make_model(V, V, N=2)
# 使用工具包 get_std-opt 获得模型的优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing 获得标签平滑对象
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用工具包 SimpleLossCompute 获得利用标签平滑的结果,得到损失计算方法
loss = SimpleLossCompute(model.generator, criterion, model_optimizer)
def run(model, loss, epochs=10):
# model : 代表将要训练的模型
# loss : 代表使用的损失计算方法
# epochs : 代表模型训练的轮次数
for epoch in range(epochs):
# 先训练,所有的参数都会被更新、
model.train()
run_epoch(data_generator(V, 8, 20), model, loss)
print("在跑哪")
# 再评估, 参数不会更新
model.eval()
# 评估时,batch_size=5
run_epoch(data_generator(V, 8, 5), model, loss)
# 进行 10 轮训练
epochs = 10
# model和loss都是来自上一步的结果
if __name__ == '__main__':
run(model, loss)