文章目录
第一节:transformer的架构介绍 + 输入部分的实现
链接:https://editor.csdn.net/md/?articleId=124648718
第二节 编码器部分实现(一)
链接:https://editor.csdn.net/md/?articleId=124648718
第三节 编码器部分实现(二)
链接:https://editor.csdn.net/md/?articleId=124724264
第四节 编码器部分实现(三)
链接:https://editor.csdn.net/md/?articleId=124746022
第五节 解码器部分实现
链接:https://editor.csdn.net/md/?articleId=124750632
第六节 输出部分实现
链接:https://editor.csdn.net/md/?articleId=124757450
1 子层连接结构
- 什么是子层连接结构?
输入到每个子层以及规范化层的过程中,还使用了残差连接(跳跃连接),因此就把这一部分的结构真题叫做子层连接,在每个编码器中都有两个子层连接结构。
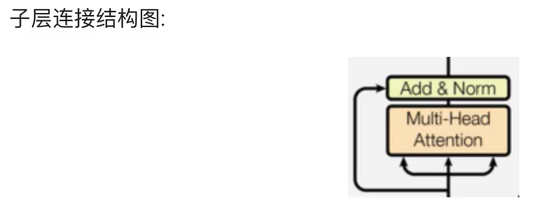
1.1 子层连接结构的代码
- 最重要的是,什么是子层函数
- sublayer:多头注意力机制,具体见下面的完整代码
# 构建子层连接结构的类
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
# size 是词嵌入的维度
super(SublayerConnection, self).__init__()
# 实例化一个规范化层的对象
self.norm = LayerNorm(size)\
# 实例化一个dropout对象
self.dropout = nn.Dropout(p=dropout)
self.size = size
def forward(self, x, sublayer):
# : x代表上一层传入的张量
# sublayer : 代表子层连接中 子层函数
# 首先将x进行规范化,送入子层函数,然后dropout, 最后残差连接
return x + self.dropout(sublayer(self.norm(x)))
1.2 完整的代码就不放了,放在下一节
- 喂给模型的数据是。
pe_result,也就是位置编码的输出 - 子层函数用的是多头注意力机制函数。
size = d_model = 512
head = 8
dropout = 0.2
x = pe_result
mask = Variable(torch.zeros(2, 4, 4))
# 子层函数采用的是多头注意力机制
self_attn = MultiHeadAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
- 这个是输出
tensor([[[-11.8095, 16.2499, -4.4547, ..., -18.9615, -28.6784, 42.2164],
[ 21.3151, 37.4979, 20.6000, ..., -0.0000, -15.7454, -6.0957],
[-20.1809, 0.1571, 10.0544, ..., 2.0665, 15.7801, -11.7174],
[ -8.3691, -15.2004, 31.4296, ..., -17.3159, -6.9389, -20.9567]],
[[-47.2065, -4.5067, -24.1064, ..., -14.0232, -25.3686, 16.3622],
[ 24.7072, -6.9208, 22.1510, ..., -0.0000, 5.9684, -1.2543],
[ 6.0378, 25.0684, 8.7416, ..., -4.0226, -13.8548, 42.6715],
[ 18.6369, 13.2774, 0.2161, ..., 8.5272, 26.5316, -0.2550]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
2 编码器层
2.1 编码器层的作用
- 作为编码器的组成单元,每个编码器层完成一次对输入的特征提取过程,即编码过程。
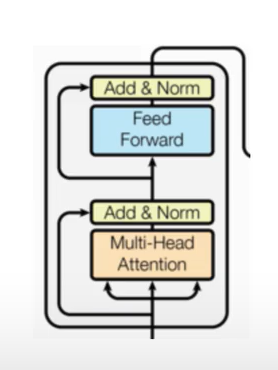
- 如图所示,整个编码器层的各个小的模块我们都已经在前面的章节中学习过了,“编码器层” 的任务就变成了把之前的代码都整合起来,并且编码器层需要 ×N
2.2 代码分析
在编码器层的初始化函数中,需要传入的有 多头自注意力机制的函数、前馈全连接层的函数。
2.3 编码器层的代码
- 下面是一部分代码,需要放在之前的代码下面
# 构建编码器层的类
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
# size : 代表词嵌入的维度
# self_attn : 代表传入的多头自注意力子层的实例化对象
# feed_forward : 代表前馈全连接层实例化对象
# dropout : 进行dropout置零比率
super(EncoderLayer, self).__init__()
# 将两个实例化对象和参数传入类中
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
# 编码器层中,有两个子层连接结构,需要clones函数进行操作
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
# x: 代表上一层传入的张量(位置编码
# mask : 代表掩码张量
# 首先让 x 经过第一个子层连接结构,内部包含多头自注意力机制子层
# 再让张量经过第二个子层连接结构,其中包含前馈全连接网络
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
size = d_model = 512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(2, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)
print(el_result)
print(el_result.shape)
- 输出情况:
tensor([[[-26.1014, -22.9220, -33.9913, ..., -9.1052, 1.4644, 3.0280],
[-22.0214, -6.5128, -20.4052, ..., 16.6487, -0.2000, -17.8196],
[-21.0369, -64.1589, 12.9999, ..., 0.1210, -24.6961, -78.7335],
[ 6.0372, -0.1803, -0.2548, ..., 0.4231, -9.8212, 34.5338]],
[[ 38.2226, -3.0611, 19.6143, ..., 23.5827, 17.5759, 33.1515],
[ 47.7601, 0.1067, 30.1620, ..., 0.3308, 18.6974, 14.6836],
[ 38.4095, 3.7291, -13.6393, ..., -40.4690, -1.1397, -38.9611],
[ 20.4703, -22.7415, -6.3404, ..., -12.3592, 21.6022, -23.2711]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
3 编码器
- 编码器,就是把编码器层 × N
- 用于对输入进行制定的特征提取
3.1 代码实现
# 构建编码器类 Encoder
class Encoder(nn.Module):
def __init__(self, layer, N):
# layer : 代表上一节编写的 编码器层
# N : 代表 编码器中需要 几个编码器层(layer)
super(Encoder, self).__init__()
# 首先使用 clones 函数 克隆 N 个编码器层 防止在self.layer中
self.layers = clones(layer, N)
# 初始化一个规范化层,作用在编码器后面
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# 代表上一层输出的张量
# mask 是掩码张量
# 让x 依次经过N个编码器层的处理;最后再经过规范化层就可以输出了
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
3.2 编码器的输出
- 编码器类 的输出,就是Transformer中编码器的特征提取表示,它将成为解码器的输入。
3 到目前为止的完整的代码
import math
from torch.autograd import Variable
from torch import nn
import torch
import copy
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
# main作用:集成了整个Transformer代码
########################################################################################################################
########################################################################################################################
# 构建 Embedding 类来实现文本嵌入层
# vocab : 词表的长度, d_model : 词嵌入的维度
class Embedding(nn.Module):
def __init__(self, vocab, d_model):
super(Embedding, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
# 词表: 1000*512, 共是1000个词,每一行是一个词,每个词是一个512d的向量表示
vocab = 1000
d_model = 512
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
########################################################################################################################
# 构建位置编码器的类
# d_model : 代表词嵌入的维度
# dropout : 代表Dropout层的置零比率
# max_len : 代表每个句子的最大长度
# 初始化一个位置编码矩阵pe,大小是 max_len * d_model
# 初始化一个绝对位置矩阵position, 大小是max_len * 1
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
# 定义一个变化矩阵,div_term, 跳跃式的初始化
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 将前面定义的变化矩阵 进行技术,偶数分别赋值
pe[:, 0::2] = torch.sin(position * div_term) # 用正弦波给偶数部分赋值
pe[:, 1::2] = torch.cos(position * div_term) # 用余弦波给奇数部分赋值
# 将二维张量,扩充为三维张量
pe = pe.unsqueeze(0) # 1 * max_len * d_model
# 将位置编码矩阵,注册成模型的buffer,这个buffer不是模型中的参数,不跟随优化器同步更新
# 注册成buffer后,就可以在模型保存后 重新加载的时候,将这个位置编码器和模型参数
self.register_buffer('pe', pe)
def forward(self, x):
# x : 代表文本序列的词嵌入表示
# 首先明确pe的编码太长了,将第二个维度,就是max_len对应的维度,缩小成x的句子的同等的长度
x = x + Variable(self.pe[:, : x.size(1)], requires_grad=False) # 表示位置编码是不参与更新的
return self.dropout(x)
d_model = 512
dropout = 0.1
max_len = 60
vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
x = embr # shape: [2, 4, 512]
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
# print(pe_result)
def attention(query, key, value, mask=None, dropout=None):
# query, key, value : 代表注意力的三个输入张量
# mask : 掩码张量
# dropout : 传入Dropout实例化对象
# 首先,将query的最后一个维度提取出来,代表的是词嵌入的维度
d_k = query.size(-1)
# 按照注意力计算公式,将query和key 的转置进行矩阵乘法,然后除以缩放系数
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# print("..", scores.shape)
# 判断是否使用掩码张量
if mask is not None:
# 利用masked_fill 方法,将掩码张量和0进行位置的意义比较,如果等于0,就替换成 -1e9
scores = scores.masked_fill(mask == 0, -1e9)
# scores的最后一个维度上进行 softmax
p_attn = F.softmax(scores, dim=-1)
# 判断是否使用dropout
if dropout is not None:
p_attn = dropout(p_attn)
# 最后一步完成p_attm 和 value 的乘法,并返回query的注意力表示
return torch.matmul(p_attn, value), p_attn
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print('attn', attn)
# print('attn.shape', attn.shape)
# print("p_attn", p_attn)
# print(p_attn.shape)
# 实现克隆函数,因为在多头注意力机制下,要用到多个结果相同的线性层
# 需要使用clone 函数u,将他们统一 初始化到一个网络层列表对象中
def clones(module, N):
# module : 代表要克隆的目标网络层
# N : 将module几个
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# 实现多头注意力机制的类
class MultiHeadAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
# head : 代表几个头的函数
# embedding_dim : 代表词嵌入的维度
# dropout
super(MultiHeadAttention, self).__init__()
# 强调:多头的数量head 需要整除 词嵌入的维度 embedding_dim
assert embedding_dim % head == 0
# 得到每个头,所获得 的词向量的维度
self.d_k = embedding_dim // head
self.head = head
self.embedding_dim = embedding_dim
# 获得线性层,需要获得4个,分别是Q K V 以及最终输出的线性层
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# 初始化注意力张量
self.attn = None
# 初始化dropout对象
self.drop = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# query,key,value 是注意力机制的三个输入张量,mask代表掩码张量
# 首先判断是否使用掩码张量
if mask is not None:
# 使用squeeze将掩码张量进行围堵扩充,代表多头的第n个头
mask = mask.unsqueeze(1)
# 得到batch_size
batch_size = query.size(0)
# 首先使用 zip 将网络能和输入数据连接在一起,模型的输出 利用 view 和 transpose 进行维度和形状的
query, key, value = \
[model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))]
# 将每个头的输出 传入到注意力层
x, self.attn = attention(query, key, value, mask=mask, dropout=self.drop)
# 得到每个头的计算结果,每个output都是4维的张量,需要进行维度转换
# 前面已经将transpose(1, 2)
# 注意,先transpose 然后 contiguous,否则无法使用view
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head*self.d_k)
# 最后将x输入到线性层的最后一个线性层中进行处理,得到最终的多头注意力结构输出
return self.linears[-1](x)
# 实例化若干个参数
head = 8
embedding_dim = 512
dropout = 0.2
# 若干输入参数的初始化
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
mha = MultiHeadAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)
# print(mha_result.shape)
import math
from torch.autograd import Variable
from torch import nn
import torch
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
# d_model : 代表词嵌入的维度,同时也是两个线性层的输入维度和输出维度
# d_ff : 代表第一个线性层的输出维度,和第二个线性层的输入维度
# dropout : 经过Dropout层处理时,随机置零
super(PositionwiseFeedForward, self).__init__()
# 定义两层全连接的线性层
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
# x: 来自上一层的输出
# 首先将x送入第一个线性网络,然后relu 然后dropout
# 然后送入第二个线性层
return self.w2(self.dropout(F.relu((self.w1(x)))))
d_model = 512
d_ff = 64
dropout = 0.2
# 这个是上一层的输出,作为前馈连接的输入
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)
# print(ff_result)
# print(ff_result.shape)
# 构架规范化层的类
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
# features : 代表词嵌入的维度
# eps :一个很小的数,防止在规范化公式 除以0
super(LayerNorm, self).__init__()
# 初始化两个参数张量 a2 b 2 用于对结果作规范化 操作计算
# 用nn.Parameter 封装,代表他们也是模型中的参数,也要随着模型计算而计算
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps # 传入到模型中去
def forward(self, x):
# x : 是上一层网络的输出 (两层的前馈全连接层)
# 首先对x进行 最后一个维度上的求均值操作,同时要求保持输出维度和输入维度一致
mean = x.mean(-1, keepdim=True)
# 接着对x最后一个维度上求标准差的操作,同时要求保持输出维度和输入维度一制
std = x.std(-1, keepdim=True)
# 按照规范化公式进行计算并返回
return self.a2 * (x-mean) / (std + self.eps) + self.b2
features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)
# print(ln_result)
# print(ln_result.shape)
# 构建子层连接结构的类
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
# size 是词嵌入的维度
super(SublayerConnection, self).__init__()
# 实例化一个规范化层的对象
self.norm = LayerNorm(size)\
# 实例化一个dropout对象
self.dropout = nn.Dropout(p=dropout)
self.size = size
def forward(self, x, sublayer):
# : x代表上一层传入的张量
# sublayer : 代表子层连接中 子层函数
# 首先将x进行规范化,送入子层函数,然后dropout, 最后残差连接
return x + self.dropout(sublayer(self.norm(x)))
size = d_model = 512
head = 8
dropout = 0.2
x = pe_result
mask = Variable(torch.zeros(2, 4, 4))
# 子层函数采用的是多头注意力机制
self_attn = MultiHeadAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
# print(sc_result)
# print(sc_result.shape)
# 构建编码器层的类
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
# size : 代表词嵌入的维度
# self_attn : 代表传入的多头自注意力子层的实例化对象
# feed_forward : 代表前馈全连接层实例化对象
# dropout : 进行dropout置零比率
super(EncoderLayer, self).__init__()
# 将两个实例化对象和参数传入类中
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
# 编码器层中,有两个子层连接结构,需要clones函数进行操作
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
# x: 代表上一层传入的张量(位置编码
# mask : 代表掩码张量
# 首先让 x 经过第一个子层连接结构,内部包含多头自注意力机制子层
# 再让张量经过第二个子层连接结构,其中包含前馈全连接网络
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
size = d_model = 512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(2, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)
# print(el_result)
# print(el_result.shape)
# 构建编码器类 Encoder
class Encoder(nn.Module):
def __init__(self, layer, N):
# layer : 代表上一节编写的 编码器层
# N : 代表 编码器中需要 几个编码器层(layer)
super(Encoder, self).__init__()
# 首先使用 clones 函数 克隆 N 个编码器层 防止在self.layer中
self.layers = clones(layer, N)
# 初始化一个规范化层,作用在编码器后面
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# 代表上一层输出的张量
# mask 是掩码张量
# 让x 依次经过N个编码器层的处理;最后再经过规范化层就可以输出了
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
size = d_model = 512
head = 8
d_ff = 64
c = copy.deepcopy
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(2, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
print(en_result)
print(en_result.shape)
3.1 输出
- 这里的输出是表示,经过输入部分,编码器部分,对语言的特征提取的输出!
tensor([[[-0.2378, -2.0161, 0.0674, ..., -0.8542, 0.8881, -0.5505],
[-0.7443, -0.7985, -2.9319, ..., 0.5551, -1.5336, 1.1550],
[-1.5567, 1.0068, 0.7381, ..., 1.3993, 1.2237, -0.0844],
[ 0.3637, 1.5046, -0.2582, ..., 0.9360, -0.6234, 0.4847]],
[[ 0.4946, 0.3589, -0.8313, ..., 0.4581, 0.9530, -0.0552],
[ 0.1014, -2.7886, 1.4743, ..., -1.4032, -0.4451, -0.6466],
[-0.0989, -0.4314, 2.2626, ..., 1.4934, 0.4423, -1.7249],
[-0.5528, -1.1313, -0.0549, ..., 0.1883, 0.0160, 0.5280]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])```