题目清单
背包问题
背包这四种模型有点像,做个简单概括方便区分
//01背包优化版
for (int i = 1; i <= n; i++)
for (int j = V; j >= v[i]; j--)
f[j] = max(f[j], f[j - v[i]] + w[i]);
//完全背包优化版
for (int i = 1; i <= n; i++)
for (int j = v[i]; j <= V; j++)
f[j] = max(f[j], f[j - v[i]] + w[i]);*/
//多重背包朴素版->优化版二进制往下翻
//二维->一维
for (int i = 1; i <= n; i++)
for (int j = V; j >= 0; j--)
//(得V->0,如过反着就错了),是写洛谷那道卖东西的题发现的
//完全背包那边为啥不会这样是因为完全背包一定能被填满,多重背包不一定被填满
for (int k = 0; k <= s[i] && k * v[i] <= j; k++)
f[j] = max(f[j], f[j - k * v[i]] + k * w[i]);
//完全朴素
for (int i = 1; i <= n; i++)
for (int j = 0; j <= V; j++)
for (int k = 0; k <= s[i] && k * v[i] <= j; k++)
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
//分组背包优化版
for(int i=1;i<=n;i++)
for (int j = V; j >= 1; j--) {
for (int k = 1; k <= s[i]; k++)
if(j>=v[i][k])
f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
}
总结一下背包优化二维变成一维需要从大体积开始枚举的有
01背包,分组背包,多重背包
前两个是因为处理到第i个物品是在处理完第i-1个物品的基础上进行的。
最后一种是因为会出现背包装不满的情况,从小体积开始会产生明明所有物品已经被装入背包又再次进行装入。
第二种情况是写这题时发现的-卖东西
01背包
01背包问题的模型:有规定的空间和若干物体,每个物体给出体积和权重,每个物体最多取一次,要求在规定空间大小内取得权重和最大或者最小
讲一下代码中那个双重循环:
for (int i = 1; i <= N; i++)
for (int j = 0; j <= V; j++) {
f[i][j] = f[i - 1][j];
if (j >= v[i]) f[i][j] = max(f[i-1][j - v[i]] + w[i], f[i][j]);
}
f[i][j]表示处理到第i个物品,当背包最大容量 j 情况下的最优解(本题表示最大价值)
当前的状态是从之前的状态变化来的,从f[ 0 ][ 0 ]=0开始,有N件物品,需要N次决策,每次决策都决定第i件物品是否放入背包,如果不放入背包,f[ i ][ j ]=f[ i-1 ][ j ],直接将判断完前i-1个物品所得到的最优解赋给判断完前i件物品的最优解,如果要放入背包,先判断第i件物品的体积是否小于等于最大容量,然后还要判断放入和不放入哪个价值更大,所以f[ i ][ j ]=max(f[ i-1][ j ],f[ i-1 ][ j-v[i] ]+w[ i ])(状态转移方程),在剩余容量为j-v[i]的背包的最优解基础上加上w[i]就是剩余容量为j的最优解
理清楚整个工作过程中背包的变化还是有点绕的,自己代码调试一下可能就明白了
朴素版
#include<iostream>
using namespace std;
const int M = 1005;
int v[M], w[M];
int f[M][M];
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++)
cin >> v[i] >> w[i];
for (int i = 1; i <= N; i++)
for (int j = 0; j <= V; j++) {
f[i][j] = f[i - 1][j];
if (j >= v[i])
f[i][j] = max(f[i-1][j - v[i]] + w[i], f[i][j]);
}
cout << f[N][V];//这个表示判断完N个物体,一开始剩余背包容量为V的最大价值、
return 0;
}
优化版
分析写在代码内了
for (int i = 1; i <= N; i++)
for (int j = V; j >= v[i]; j--) {
//for (int j = v[i]; j <= V; j++) {
//f[i][j] = f[i - 1][j];
//这一块,因为i是由i-1的状态变化来的,i-2,i-3等等再往前的状态都不用
//管,只用看前一步,所以变成f[j] = f[j],这个就可以直接去掉了
//if (j >= v[i]) 这个判断也可以直接去掉,把j开始改成v[i]就能保证j>=v[i]恒成立
// f[i][j] = max(f[i-1][j - v[i]] + w[i], f[i][j]);
f[j] = max(f[j - v[i]] + w[i], f[j]);
//当循环是for (int j = v[i]; j <= V; j++),这样是不对的,因为j前-v[i]<=j后-v[i],小值在在大值前面更新,
//那么此时f[j-v[i]]的结果是属于i层,那就相当于 f[i][j] = max(f[i][j - v[i]] + w[i], f[i][j]);
//但是按照之前的式子f[j]是在i-1层的基础上跟新的,所以我们将循环的顺序倒一下,
//j从V开始计算一直到v[i],这样大值在小值前面更新,大值在小值基础上更新,此时的小值是i-1层的结果
}
果然隔一阵子再看很多东西就理解了:
之前说把二维变成一维采用滑动数组的思想,其实就是处理第i个物品是在第i-1个物品上进行处理的,i-2,i-3什么的不用管,在每次执行完for (int j = V; j >= v[i]; j--)后f[j]从V到v[i]都被更新过了,所以下一次的更新就是在这一次更新的基础上进行的,为什么从V->v[i]就是保证下一次的更新是在这一次更新上进行,如果倒过来会产生下一次更新是在下一次更新产生的新结果上进行的。
#include<iostream>
using namespace std;
const int M = 1005;
int v[M], w[M], f[M];
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++)
cin >> v[i] >> w[i];
for (int i = 1; i <= N; i++)
for (int j = V; j >= v[i]; j--)
f[j] = max(f[j],f[j - v[i]] + w[i]);
cout << f[V];
return 0;
}
完全背包
模型基本与01背包相同,不同的是对于每一件物体可以无穷取
思路也和01背包差不多,思考方式是一样的,不同点在于实行操作后的状态划分更多,01背包只有拿一件或者不拿,完全背包则是可以拿0件,1件,2件…k件
所以朴素写法就加一个循环,用来实现对i种物品拿k件后的状态。

从y总的课上面截下来的嘻嘻
题目链接–完全背包问题
朴素写法
#include<iostream>
const int M = 1005;
int v[M], w[M], f[M][M];
using namespace std;
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++)
cin >> v[i] >> w[i];
for(int i=1;i<=N;i++)
for(int j=1;j<=V;j++)
for (int k = 0; k * v[i] <= j; k++) {
//f[i][j] = f[i - 1][j];这一步不需要是因为k从0开始,f[i][j] = f[i - 1][j]就是k=0
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
}
cout << f[N][V];
return 0;
}
对这一块进行优化,首先想想看k这一段的循环可不可以去掉
f[i , j ] = max( f[i-1,j] , f[i-1,j-v]+w , f[i-1,j-2v]+2w , f[i-1,j-3v]+3w , …)
f[i , j-v]= max( f[i-1,j-v] , f[i-1,j-2v] + w , f[i-1,j-2v]+2*w , …)
由上两式,可得出如下递推关系:
f[i][j]=max(f[i,j-v]+w , f[i-1][j])
for(int i=1;i<=N;i++)
for(int j=1;j<=V;j++)
for (int k = 0; k * v[i] <= j; k++) {
//f[i][j] = f[i - 1][j];这一步不需要是因为k从0开始,f[i][j] = f[i - 1][j]就是k=0
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
}
进行第一步优化,上面那种写法过不了,超时,这种简单优化就可以了
for(int i=1;i<=N;i++)
for (int j = 1; j <= V; j++) {
f[i][j] = f[i - 1][j];//这个别忘了!!
if(v[i]<=j) f[i][j] = max(f[i][j], f[i][j - v[i]] + w[i]);
//和01背包不一样,01是:if(v[i]<=j) f[i][j] = max(f[i][j], f[i-1][j - v[i]] + w[i]);
//因为完全背包优化后就是可以在同一次更新的基础上进行的
}
简单优化后和01背包非常像,尤其是这两句:
f[i][j] = max(f[i][j],f[i-1][j-v[i]]+w[i]);//01背包
f[i][j] = max(f[i][j],f[i][j-v[i]]+w[i]);//完全背包问题
联想到01背包二维到一维的优化,再进一步优化,变成一维数组
就变成这样了酱
#include<iostream>
const int M = 1005;
int v[M], w[M], f[M];
using namespace std;
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++)
cin >> v[i] >> w[i];
for (int i = 1; i <= N; i++)
for (int j = v[i]; j <= V; j++) {
//这里和 01背包不一样,01是从V->v[i]
//本质是不一样的,01背包朴素版f[i][j] = max(f[i][j],f[i-1][j-v[i]]+w[i]),
//f[j] = f[j - v[i]] + w[i]这里要求分f[j - v[i]] + w[i]是要i-1层的结果,第i层是在i-1层基础上更新的
//完全背包朴素版f[i][j] = max(f[i][j],f[i][j-v[i]]+w[i]),f[j] = f[j - v[i]] + w[i]表示的是k的改变不要求从i-1层变化
f[j] = max(f[j], f[j - v[i]] + w[i]);
}
cout << f[V];
return 0;
}
01背包和完全背包写法有点像,注意区分
多重背包
与完全背包很像,不同在于没件物品拿取得个数是有限个
朴素版
#include<iostream>
using namespace std;
const int M = 105;
int v[M], w[M], s[M], f[M][M];
int N, V;
int main()
{
cin >> N >> V;
for (int i = 1; i <= N; i++)
cin >> v[i] >> w[i] >> s[i];
for (int i = 1; i <= N; i++)
for (int j = 0; j <= V; j++)
for (int k = 0; k <= s[i] && v[i] * k <= j; k++)
f[i][j] = max(f[i][j], f[i-1][j - k * v[i]] + k * w[i]);
cout << f[N][V];
return 0;
}
为什么不能像完全背包那样优化呢?
详细现y总视频讲解4:10开始
//f[i][j]=max(f[i-1][j],f[i-1][j-v]+w,f[i-1][j-2v]+2w…+f[i-1][j-sv]+sw)
//f[i][j-v]=max(___,f[i-1][j-v],f[i-1][j-2v]+w…f[i-1][j-(s+1)v]+sw)
黄色标记的不一定出现,如果j-sv<=0就不出现,
k <= s[i] && v[i] * k <= j
但是可能出现一旦出现就不能转换f[i][j]=max(f[i][j],f[i][j-v]+w),所以不能像完全背包那样子优化—>换一种优化方式
优化版
简单说一下优化的思路–二进制优化+01背包
题目给出第i种物品最多有s件,那么试试能不能将s件划分成k部分,能够通过这k组物品合成0–s件物品。
举个例子:
s=1023,物品可以取1,2,3…1023件,
将若干个物品打包,1,2,4,8,…,512
前一组数组可以凑出0–1,前两组数据可以凑出0–3,前三组可以凑出0–7…可以凑出0–1023,打包以后的物品就可以看出01背包问题,因为每个组件只能选一次。
本来要枚举1024次,现在只要枚举十次,达到了节省大量时间的目的!!
O(N)->O(logN)
再举个例子:
s=200
分组:1,2,4,8,16,32,64,128 (128不能要,否则前八组和大于200,前七组和为127,所以再补上一个73)
分组:1,2,4,8,16,32,64,73 这样恰好凑出0–200的任意一个数
给任意一个数s,
我们采用的方式是将s划分成1件,2件,4件,8件…2k件,c件(c待定是否存在)
始终满足1+2+4+8+2k=2k+1-1<=s;如果2k+1-1<s,再补上c=s-2k+1+1,显然c<2k+1,如果c>=2k+1就至少还存在2k+1这个划分情况。
0-2k+1-1中间不会缺可以通过二进制发现,我们拆分出来的每一个因子都是二进制上每一位的1,每一位是放1还是0就通过拿因子来决定,能够实现0-2k+1-1中间不会缺。
k+1个因子(0,1,2…2k,为什么0也算一个因子参考上面的二进制,可以说这种证明是上面那个推出来的)可以拼成C(k+1,0)+C(k+1,1)+C(k+1,2)+…+C(k+1,k+1)=2k+1种情况(0-2k+1-1中间不会缺也可以这样证明),并且任意拼法都不会重复,因为每个划分之间都差2倍,0~2k能够凑出0–2k+1-1,补上c后能凑出c–s,那就看一下2k+1-1–c是否有空隙,因为c<2k+1->c<=2k+1-1,所以无间隔。每个数都能拼出来。
s件拆成log s件,然后再对差分后的物品组进行01背包
朴素做法时间复杂度是NVS->转化后的时间复杂度是NVlogs
题目链接–多重背包问题
这题数据范围较小100100100=1e6,用朴素做法就行
题目链接–多重背包问题II
这题数据范围较大,如果用朴素做法100020002000=41e9,超时,c++1m能处理一亿时间复杂度,优化后10002000log 2000=1000200011大概在21e7,能过。
1000log 2000=100011数组大概开1.1*1e4大小数组就欧克了。
#include<iostream>
using namespace std;
const int M = 25000;
int s[M], v[M], w[M], f[M];
int main()
{
int N, V;
cin >> N >> V;
int pos = 0;
for (int i = 1; i <= N; i++) {
int tv, tw, ts, k = 1;
cin >> tv >> tw >> ts;
while (ts >= k) {
pos++;
v[pos] = k * tv;
w[pos] = k * tw;
ts -= k;
k *= 2;
}
if (ts) {
pos++;
v[pos] = ts * tv;
w[pos] = ts * tw;
}
}
N = pos;
//转化成01背包问题
for (int i = 1; i <= N; i++)
for (int j = V; j >= v[i]; j--)
f[j] = max(f[j], f[j - v[i]] + w[i]);
cout << f[V];
return 0;
}
分组背包
分组背包和完全背包类似,完全背包是同一件物品能取多少个,分组背包是一组物品能取哪一个
直接上优化代码了,思路都差不多
关于循环那边其实可以总结一下:
如果当前状态是在上一层状态基础上改变的体积要从大到小枚举,如果不是从上一层状态开始,就从小到大枚举,本篇博客整理的只有01背包和分组背包是从上一层状态改变的。
题目链接–分组背包
#include<iostream>
using namespace std;
const int M = 105;
int s[M], v[M][M], w[M][M], f[M];
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++) {
cin >> s[i];
for (int j = 0; j < s[i]; j++)
cin >> v[i][j] >> w[i][j];
}
for (int i = 1; i <= N; i++)
for (int j = V; j >= 0; j--)
for (int k = 0; k < s[i]; k++)
if (j >= v[i][k])
f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
cout << f[V];
return 0;
}
写的时候发现一点问题,所以还是补上朴素版代码
#include<iostream>
using namespace std;
const int M = 105;
int s[M], v[M][M], w[M][M], f[M][M];
int main()
{
int N, V;
cin >> N >> V;
for (int i = 1; i <= N; i++) {
cin >> s[i];
for (int j = 0; j < s[i]; j++)
cin >> v[i][j] >> w[i][j];
}
for (int i = 1; i <= N; i++)
for (int j = 0; j <= V; j++) {
f[i][j] = f[i - 1][j];//本组任何一件物品都不选
//这个在k循环前!如果不放在k前放在k循环内部,f[i]本来是在f[i-1]基础上更新的,
//如果f[i][j]之前已经更新过了,f[i][j]>f[i-1][j],同样j(k不同),再来一遍f[i][j] = f[i - 1][j];,之前更新过的f[i][j]就作废了,再次比较的是未更新的f[i-1][j];
for (int k = 0; k < s[i]; k++) {
if (j >= v[i][k])
f[i][j] = max(f[i][j], f[i - 1][j - v[i][k]] + w[i][k]);
}
}
cout << f[N][V];
return 0;
}
线性DP
后面展示几个配套的习题
数字三角形
题目链接–数字三角形
又是从y总那边白嫖的分析图,不想自己画了hh
分析:题目求的是从顶点到底部路径上节点之和的最大值,因为只能走左下和右下,所以对当前节点的分析只要看左上方节点和右上方节点就行,因为是上层产生下层,所以下层的最大值就是上层的最大值加上当前节点
构造成一个二维的图像,将各节点存入二维数组进行状态的转移计算
注意的地方是!,因为分析要看左上方节点和右上方节点,对于边界节点例如f[2][1],可以从f[1][0]或者f[1][1]走到,所以这两个节点都要初始化,总结就是不能只初始化三角形上的节点,还有周围一圈的节点都要初始化。

代码
#include<iostream>
using namespace std;
const int N = 505, INF = 1e9;
int main()
{
int a[N][N], f[N][N];
int n;
cin >> n;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= i; j++)
cin >> a[i][j];
for (int i = 1; i <= n; i++)
for (int j = 0; j <= i + 1; j++)
f[i][j] = -INF;
f[1][1] = a[1][1];
for (int i = 2; i <= n; i++)
for (int j = 1; j <= i; j++)
f[i][j] = max(f[i - 1][j - 1] + a[i][j], f[i - 1][j] + a[i][j]);
int Max = -INF;
for (int i = 1; i <= n; i++)
Max = max(Max, f[n][i]);
cout << Max;
return 0;
}
最长上升子序列
注意!求得是子序列而不是字串,子序列可以间隔的
题目链接–最长上升子序列
朴素版代码—时间复杂度O(n2)
思想:i作为最长子串终点的位置,通过a[i],a[j]进行比较(j<i),如果a[i]>a[j],也说以i为结尾的最长子序列可以在以j为结尾的最长子序列上进行修改(前一个小于自己的数结尾的最大上升子序列加上自己,即+1)可能需要更新可能不更新,所以f[i] = max(f[i], f[j] + 1)
注意! i一定是最长上升子串的终点位置,a[i]一定包含在子串内,我一开始没有写这Max = max(Max, f[i])一步,而是直接输出f[n-1],然后就WA了,芜湖。最长上升子序列不一定有a[n-1]啊,傻了吧…
又是白嫖y总的思维导图
那个椭圆表示f[i]可能来自f[0],f[1]…f[i-1](倒数第二个数的位置,倒数第一个数是f[i])

#include<iostream>
using namespace std;
const int N = 1005;
int a[N], f[N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
f[i] = 1;
}
int Max = 1;
for (int i = 0; i < n; i++)//i作为子序列的终点,找以i为终点的最长子序列
for (int j = 0; j < i; j++) {
if (a[j] < a[i]) f[i] = max(f[i], f[j] + 1);
Max = max(Max, f[i]);
}
cout << Max;
return 0;
}
扩展一下:如果要存储最长子序列,可以设一个数字p来标记每次更新时上一个最长子序列的位置
#include<iostream>
using namespace std;
const int N = 1005;
int a[N], f[N], p[N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
f[i] = 1;
}
memset(p, -1, sizeof p);
for (int i = 0; i < n; i++)//i作为子序列的终点,找以i为终点的最长子序列
for (int j = 0; j < i; j++) {
if (a[j] < a[i] && f[j] + 1>f[i]) {
f[i] = f[j] + 1;
p[i] = j;
}
}
int maxp = 0;
for (int i = 1; i < n; i++)
if (f[i] > f[maxp]) maxp = i;
for (int i = maxp; i != -1; i = p[i])
cout << a[i] << " ";
return 0;
}
优化版–O(nlogn)
<这样写法不太像dp,只是基于dp进行优化,本质应该是二分+贪心>
我们观察朴素版的写法,发现子序列的加长是因为当前数字比子序列末尾的数字要大,如果我们子序列的末尾数字越小,那么子序列延长的可能性就越大
也就是说我们对于任意长度的子序列只要保存该长度下子序列结尾数字的最小值,比最小值大的都可以忽略
比如说子序列为1 2 5和1 2 3,一个数字6要插在子序列后面,如果能插在1 2 5后面那一定能插在1 2 3后面。
接着我们又发现,在同一组数据中,不同长度的自序列按照上面数据存储,每个长度的子序列的结尾数字是递增的
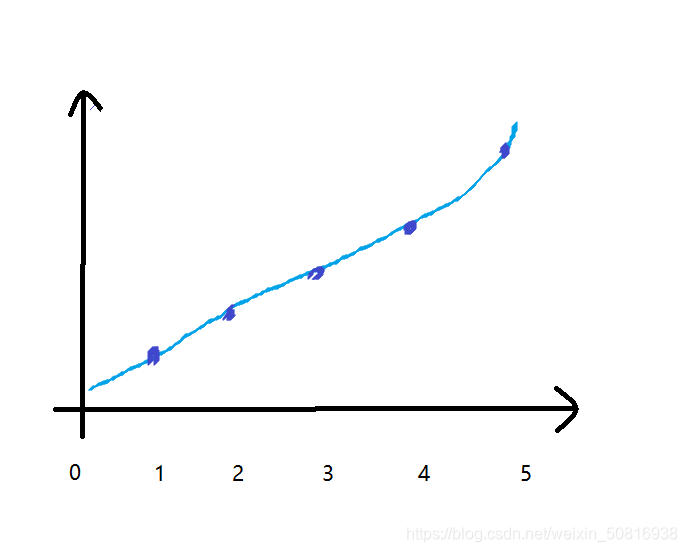
因为这个性质,我们在判断当前数据应该加在哪个长度的子串后面的时候可以用二分查找,设q数组存储当前长度结尾数字的最小值,比如q[i]表示长度为i的子序列的最小结尾数据,如果a[i]>q[4]&&a[i]<q[5],那么a[i]就可以作为长度为5的子序列的最小结尾数字q[l + 1] = a[i];。并且如果当前子序列的延长比之前的最长子序列还要长,跟新最长子序列的长度len = max(len, l + 1);。
为什么不同长度的结尾最小值是递增的,这个挺好理解的,插入一个数,在已有的子序列中找该数应放的位置,那么找到的满足要求的最长子序列(设长度为k)的结尾数字一定小于当前数,那么该数就插在k长度后面,那么该数就延长了k长度的子序列,如果k+1长度的子序列不存在,该数就产生了k+1长度的子序列,该数自然而然成为k+1长度子序列结尾最小数组,如果k+1长度的子序列已经产生,该数一定小于原k+1长度子序列结尾的最小值,那么该数就覆盖掉原来k+1长度子序列结尾的最小值,变成新的k+1长度子序列结尾的最小值。
#include<iostream>
using namespace std;
const int N = 1e5 + 5;
int a[N], q[N];//a用来存序列,q用来存每个长度结尾最小值
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++) cin >> a[i];
q[0] = -2e9;//哨兵
int len=0;
for (int i = 0; i < n; i++) {
int l = 0, r = len, mid;
while (l < r) {
mid = l + r + 1 >> 1;
if (q[mid] < a[i]) l = mid;
else r = mid - 1;
}
len = max(len, l + 1);
q[l + 1] = a[i];
}
cout << len << endl;
}
不想手写二分可以试试这个:
#include<iostream>
#include<algorithm>
#include<vector>
#include<cstring>
using namespace std;
typedef long long ll;
ll arr[1000000], q[1000000];
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> arr[i];
}
int len = 1, top = 0;
q[++top] = arr[1];
//如果比长度最大的子序列结尾还大就接在结尾,否则就找替换子序列中第一个大于等于它的数
for (int i = 2; i <= n; i++) {
if (arr[i] > q[top]) q[++top] = arr[i];
else {
int pos = lower_bound(q + 1, q + top + 1, arr[i]) - q;
q[pos] = arr[i];
}
}
cout << top;
return 0;
}
最长公共子序列—O(n2)
题目链接–最长公共子序列
同样,是子序列,不是子串,不然就可以用kmp了
这题的思路我感觉还挺难想,又是白嫖y总的思路图
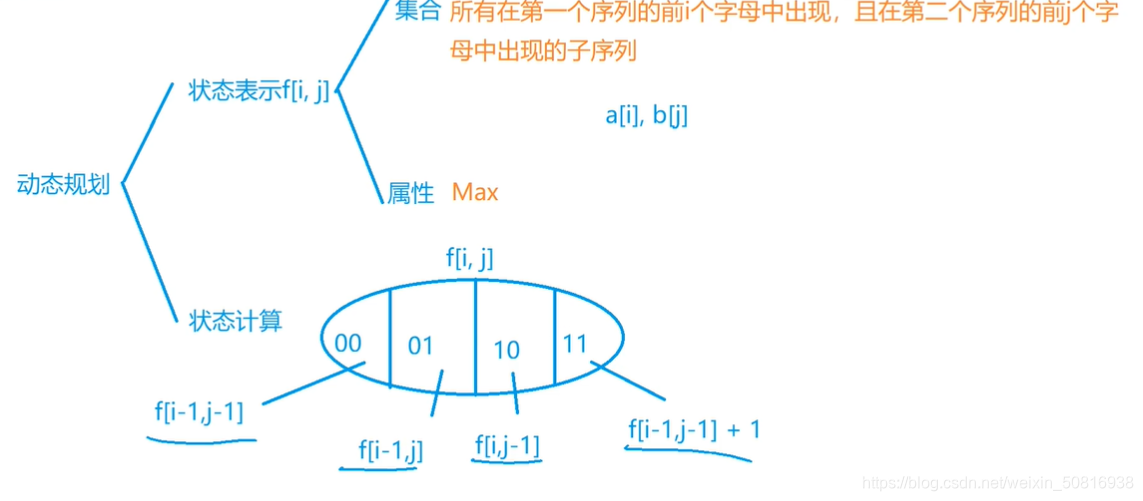
简单的理一下吧:(一般两个字符串的问题都可以用前i个字符,前j个字符解决)
先注意f[i][j]表示a中前i个字母构成的子序列和b中前j个字母构成的子序列的最长公共子序列,至于这个最长公共子序列到底包不包含a[i]和b[j]不一定。
本题的难点在于集合的划分:
以a[i],b[j]是否包含在子序列中作为划分依据,有四种可以,a,b不选,选b不选a,选a不选b,a,b都选,我们用00,01,10 ,11表示。
如果a,b都不选,子序列就是在a的前i-1中出现并且在b中前j-1中出现的最长子序列,f[i][j]=f[i-1][j-1];a,b都选就是在f[i-1][j-1]表示的子序列的基础上加一,f[i][j]=f[i-1][j-1]+1;
麻烦的在于中间两种的分析:我们理所应当认为选a不选b就是f[i][j-1],但其实这是不相等的,因为f[i][j-1]只是表示在a中前i个字符中出现和在b中前j-1个字符中出现的最长子序列,但是a[i]到底包不包含在这个最长子序列中其实我们是没法知道的,但是我们认为的f[i][j-1]是a出现在子序列中b不出现在子序列中,两者不等价。
f[i][j-1]不一定包含a[i],所以f[i][j-1]可能就是f[i-1][j-1],f[i][j-1]集合不是我们想的。
但幸运的是,f[i][j-1]一定包含10这种情况,f[i][j]是包含f[i][j-1]的,所以用f[i][j]=f[i][j-1]也是可以的,没有问题。
这样求得话可能f[i-1][j-1],f[i][j-1]重复了,但不碍事,因为求的是最大值,如果是求数就不行了。
比如求A,B,C的最大值,可以求A,B最大值,然后求B,C最大值,接着对两个最大值再求一个最大值就行,求最大值可以重复,只要不漏掉就行。求数量就不能重复。
因为f[i-1][j],f[i][j-1]都是包含f[i-1][j-1],所以f[i-1][j-1]就不用单独拿出来考虑了,所以考虑的只有
f[i][j] = max(f[i - 1][j], f[i][j - 1]);
if (a[i] == b[j]) f[i][j] = f[i - 1][j - 1] + 1;
拓展:y总在写代码的时候出现了一个小失误,a,b数组没有定义成char类型,结果出错了,说一下数据存储的原理
int是四个字节,char是八个字节,如果a,b数组是int类型,我们用scanf("%s",a)来输入,那么四个char就会堆在一个int上面,结果就出问题了
10 10
noun jucf gh
irsf ovvo ah
十个位置
noun jucf gh(变成数字)后面全都是0
irsf ovvo ah (变成数字)后面全都是0,那么最长公共子字符串就是7,答案本来应该是2
字节(Byte):字节是通过网络传输信息(或在硬盘或内存中存储信息)的单位。字节是计算机信息技术用于计量存储容量和传输容量的一种计量单位,1个字节等于8位二进制,它是一个8位的二进制数,是一个很具体的存储空间。
数据存储是以“字节”(Byte)为单位,数据传输大多是以“位”(bit,又名“比特”)为单位,一个位就代表一个0或1(即二进制),每8个位(bit,简写为b)组成一个字节(Byte,简写为B),是最小一级的信息单位。
完整代码
#include<iostream>
using namespace std;
const int N = 1005;
char a[N], b[N];
int f[N][N];
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int j = 1; j <= m; j++) cin >> b[j];
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++) {
f[i][j] = max(f[i - 1][j], f[i][j - 1]);
if (a[i] == b[j]) f[i][j] = f[i - 1][j - 1] + 1;
}
cout << f[n][m];
return 0;
}
最短编辑距离
首先说明f[i][j]表示a数组的前i个字符和b数组的前j个字符通过一定操作后匹配(i不一定等于j,而是通过三种操作后实现匹配)
初始化是荧光绿标记的那两行:
上面那一行表示当a数组为空时,通过增加操作,实现a数组的前0个字符和b数字前j个相匹配;左边那一列表示当b数组为空时,通过删除操作,实现a数组的前i个字符和b数字前0个相匹配
找个点简单演示一下操作,对于f[1][1]
如果f[1][1]是从f[0][0]走的,f[0][0]没有操作,a数组只有o,b数组只有a,a[i]!=b[j], 通过修改任意一个字符就可达到f[1][1]状态,f[i][j] = min(f[i - 1][j - 1], f[i][j]), 要是a[i]==b[j]就是 f[i][j]=f[i-1][j-1];
如果f[1][1]是从f[0][1]走的,f[0][1]通过a数组增加一个’a’字符达成f[0][1],当到f[1][1]是,a数组又多了一个‘o’字符,想要满足就删除’o’,f[1][1]从f[1][0]走同理
f[i][j] = min(f[i - 1][j - 1], f[i][j]);
我觉得这个视频讲的很好
又是白嫖思路图的一天
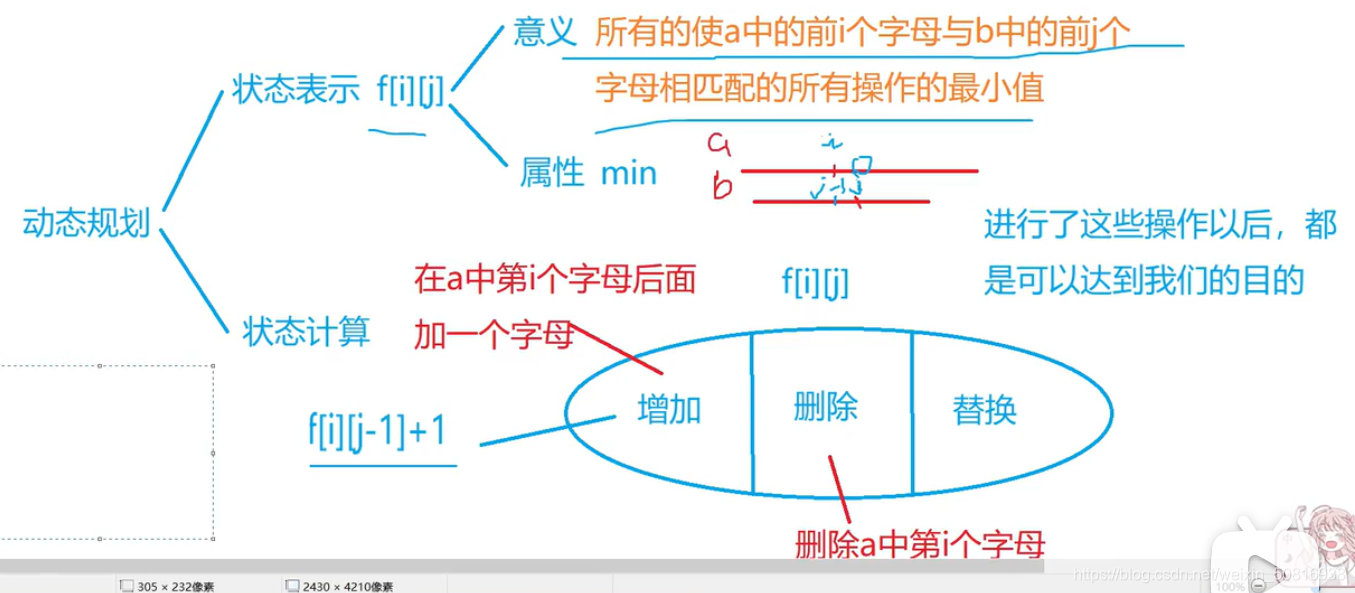
简单概括:
就是f[i][j]满足a数组的前i个字符和b数组的前j个字符通过一定操作后匹配,只有三种操作,删除,增加,修改,而f[i][j]都是通过上一步来的,
- 如果是修改,那么说明a数组前i个字符和b数组前j个字符经过一系列操作是满足要求到,达到f[i-1][j-1],但是a[i]!=b[j],所以f[i][j]=f[i-1][j-1]+1,延展开f[i][j]=f[i-1][j-1]就是a[i]=b[j],不需要修改;
- 如果是删除的话,也就是说a数组的前i-1个字符与b的前j个字符经过操作后是匹配的f[i][j]=f[i-1][j]+1,a数组删除一个a[i];
- 如果执行增加,那么就是a数组的前i个字符和b数组的前j-1字符通过操作相匹配,f[i][j]=f[i][j-1]+1,a数组加一个b[j]。
#include<iostream>
using namespace std;
const int N = 1e3 + 5;
char a[N], b[N];
int f[N][N];
int main()
{
int n, m;
cin >> n >> a + 1;
cin >> m >> b + 1;
//Inti
for (int i = 0; i <= n; i++) f[i][0] = i;//a[1]--a[i]==b[0],删掉a
for (int j = 0; j <= m; j++) f[0][j] = j;//a[0]==b[0]--b[j],增加a
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++) {
f[i][j] = min(f[i - 1][j] + 1, f[i][j - 1] + 1);
if (a[i] == b[j]) f[i][j] = min(f[i - 1][j - 1], f[i][j]);
else f[i][j] = min(f[i][j], f[i - 1][j - 1] + 1);
}
cout << f[n][m];
return 0;
}
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int edit_distance(char a[],char b[])//a转换b
{
int f[15][15];
int la = strlen(a + 1), lb = strlen(b + 1);
for (int i = 0; i <= la; i++) f[i][0] = i;
for (int i = 0; i <= lb; i++) f[0][i] = i;
for (int i = 1; i <= la; i++)
for (int j = 1; j <= lb; j++){
f[i][j] = min(f[i - 1][j] + 1, f[i][j - 1] + 1);
f[i][j] = min(f[i][j], f[i - 1][j - 1] + (a[i] != b[j]));
}
return f[la][lb];
}
int main()
{
char a[1010][15], b[15];
int n, m;
cin >> n >> m;
for (int i = 0; i < n; i++)
scanf("%s", a[i] + 1);
while (m--) {
int limit, cnt = 0;
cin >> b + 1 >> limit;
for (int i = 0; i < n; i++)
if (edit_distance(a[i], b) <= limit) cnt++;
cout << cnt << endl;
}
return 0;
}
区间DP—O(n3)
合并石子
再次白嫖y总的思维导图
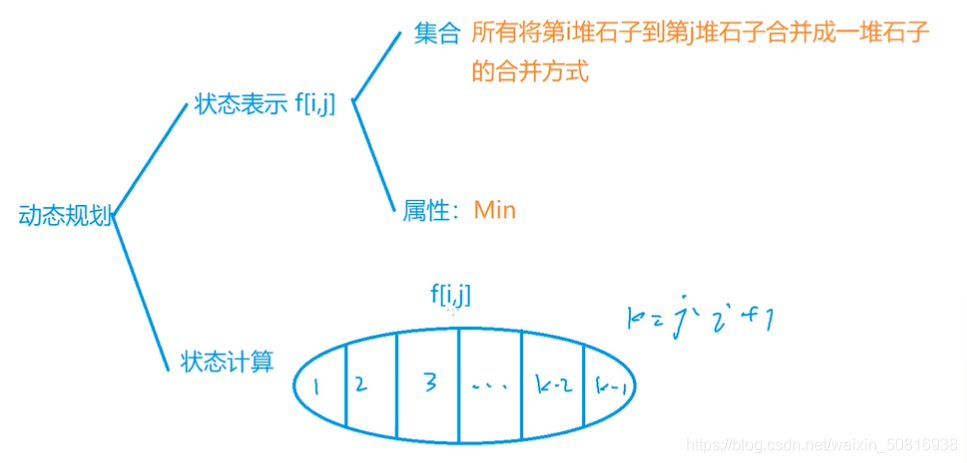
因为要从i–j分,去中间任意一个位置k,分成左边[i,k],右边[k+1,j],椭圆里面的1,2,3…k,表示左部分是从1–k。
分成两半f[i,k],f[k+1,r],f[i,j]=f[i,k]+f[k+1,r]+(i~j石子质量总和),这块怎么处理呢,对于每次两堆石子的合并,都先把最后一次合并先搁着,没有完成最后两堆合之前合并过程的代价就是f[i,k]+f[k+1,r],接着再对两堆进行合并+s[r]-s[l-1],前缀和。
经过调试以后我大概明白了本题是怎么运行的,之前一直担心在计算f[i,k]+f[k+1,r]右边还没更新,全都是最小值。
运行第一步是确定区间长度,因为区间长度为1的时候自身合并自身,代价为0,无效运算,所以长度len从2开始。接着起点的范围是从 1 到 n-len+1,注意这个只是起点。
因为长度是从小到大,所以先是更新所有小区间的合并代价,从两堆石子开始一直到n堆石子,所以可以放心在计算f[i,k]+f[k+1,r]右边已经更新了,因为右边区间长度无论如何小于等于当前总区间长度,小区间的合并在大区间的合并之前完成,所以确保在后来的合并过程中,当前区间的子区间是已经更新到最小的。
思路我觉得有点难,尤其是循环那个在哪这件事上。
!!孰能生巧
#include<iostream>
using namespace std;
const int N = 105;
int s[N], f[N][N];
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i++)
cin >> s[i];
for (int i = 1; i <= n; i++)
s[i] += s[i - 1];//前缀和
for (int len = 2; len <= n; len++)
for (int i = 1; i <= n - len + 1; i++) {
int l = i, r = i + len - 1;
f[l][r] = 1e9;//初始化注意不要忘了
for (int k = l; k < r; k++)
f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r] + s[r] - s[l - 1]);
}
cout << f[1][n];
return 0;
}
计数类DP
整数划分
算法一–转化成完全背包来操作
题目要求输入一个数字n,然后计算该数有多少种划分的方法
例如: n=3 n=3=2+1=1+1+1
题目要求:
n=n1+n2+…+nk,其中 n1≥n2≥…≥nk,k≥1。看样子是递减的,其实只要找到n的分配方案,按递减的顺序排就好,那么问题就转化成了从1–n n个数中任意取k个数,使这k个数总和为n,求有几种取法。
这样就可以转化成完全背包问题。
f[i][j] 表示处理前i个数,使得选出的数的总和为j。k表示每次取k个第i个数。
最最朴素版做法
就因为j没有从0开始我浪费了一个多小时,我这只超级大菜狗呜呜呜~~
#include<iostream>
using namespace std;
const int N = 1010, mod = 1e9 + 7;
int f[N][N];
int main()
{
int n;
cin >> n;
f[0][0] = 1;//初始化
//i表示处理完i个元素,j表示当前背包体积,k表示选第i元素的个数
for (int i = 1; i <= n; i++)
for (int j = 0; j <= n; j++)//j从0开始
for (int k = 0; k * i <= j; k++)
f[i][j] = (f[i][j] + f[i - 1][j - k * i]) % mod;
cout << f[n][n];
return 0;
}
或者:
#include<iostream>
using namespace std;
const int N = 1e3 + 5, mod = 1e9 + 7;
int f[N][N];
int main()
{
int n;
cin >> n;
for (int i = 0; i <= n; i++)
f[i][0] = 1;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)//j从1开始
for (int k = 0; k * i <= j; k++)
f[i][j] = (f[i][j] + f[i - 1][j - k * i]) % mod;
cout << f[n][n];
return 0;
}
f[i][j]=f[i-1][j]+f[i-1][j-i]+f[i-1][j-2i]+f[i-1][j-3i]...
f[i][j-i]= ______ f[i-1][j-i]+f[i-1][j-2i]+f[i-1][j-3i]...
整理一下,化简
for (int k = 0; k * i <= j; k++)
f[i][j] = (f[i][j] + f[i - 1][j - k * i]) % mod;
为
f[i][j]=f[i-1][j]+f[i][j-i]
但要判断一下j是否大于等于i
优化版
#include<iostream>
using namespace std;
const int N = 1010, mod = 1e9 + 7;
int f[N][N];
int main()
{
int n;
cin >> n;
f[0][0] = 1;
for (int i = 1; i <= n; i++)
for (int j = 0; j <= n; j++){
f[i][j]=f[i-1][j];
if(j>=i) f[i][j] = (f[i][j] + f[i][j - i]) % mod;
}
cout << f[n][n];
return 0;
}
再化简->终极版
#include<iostream>
using namespace std;
const int N = 1010, mod = 1e9 + 7;
int f[N];
int main()
{
int n;
cin >> n;
f[0] = 1;
for (int i = 1; i <= n; i++)
for (int j = i; j <= n; j++){
f[j] = (f[j] + f[j - i]) % mod;
}
cout << f[n];
return 0;
}
换一个状态表达,不一样的公式,这个状态表达真的太难想了Orz
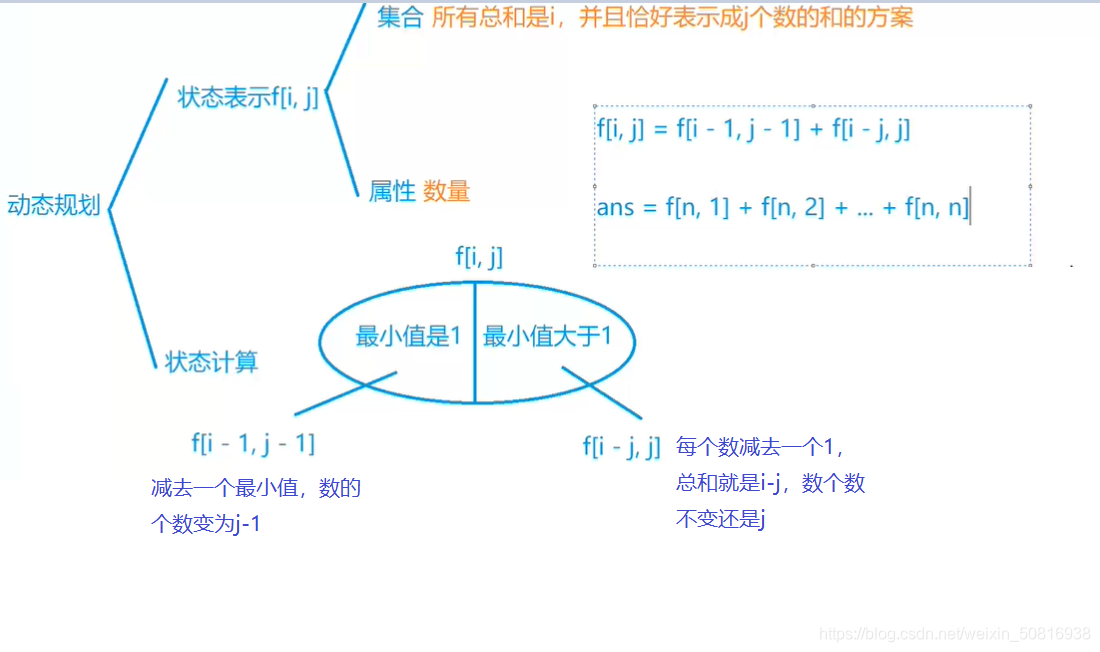
朴素版
#include<iostream>
using namespace std;
const int N = 1010, mod = 1e9 + 7;
int f[N][N];
int main()
{
int n;
cin >> n;
f[0][0] = 1;//总和为0用0个正整数表示方案数为1
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++) {
f[i][j] = f[i - 1][j - 1];
if (i >= j) f[i][j] = (f[i][j] + f[i - j][j]) % mod;
}
int res = 0;
for (int i = 1; i <= n; i++) res = (res + f[n][i]) % mod;
cout << res;
return 0;
}
数位DP
题目链接–计数问题
如何求1-n,n个数中,0-9九个数字每个数字的出现频率:比如11,1出现的频率为2
我们可以固定一个数中的第i位(任意一位)为x,改变其他位数的数,那么搭配方案的个数就是在第i位上该数的出现频率,那么该数总出现频率就是该数在每一位上的出现频率的累计和。
分析一下思路:

补充一下图片上关于边界值的描述:
当x为0时,x无法作为第一位数,所以直接从第二位开始计算,
也就是循环里的int i = len - 1 -!x
#include<iostream>
#include<vector>
#include<math.h>
using namespace std;
typedef long long ll;
ll Sue(vector<int>v, int l, int r) {
ll sum = 0;
for (int i = l; i >= r; i--)
sum = sum * 10 + v[i];
return sum;
}
ll countx(int n, int x) {
//计算1~n中x出现的次数
vector<int>v;
while (n) {
//低位先入
v.push_back(n % 10);
n /= 10;
}
ll sum = 0;
int len = v.size();
for (int i = len - 1 -!x; i >= 0; i--) {
//任意一位固定为x,x如果为0,那么首位就不用考虑
int t = pow(10, i);
if (i < len - 1) {
//固定第一位,第二种情况不用考虑(这个if判断可以去掉的,这样写比较看得出分类,因为如果是第一位(最高位)Sue返回位0,然后如果x==0又不会从第一位开始计算,所以不影响)
sum += Sue(v, len-1, i + 1) * t;
if (x == 0) sum -= t;//x为0时范围为001-abc-1.
}
if (v[i] == x) sum += Sue(v, i - 1, 0) + 1;
else if (v[i] > x) sum += t;
}
return sum;
}
int main()
{
int a, b;
while (cin >> a >> b && (a | b)) {
if (a > b) swap(a, b);
for (int i = 0; i < 10; i++)
cout << countx(b, i) - countx(a - 1, i) << " ";//前缀和
cout << endl;
}
return 0;
}
状态压缩DP
蒙德里安的梦想
这题思路挺奇妙的,一些细节地方还是挺难想的,所以我打算细细说一下:
题目本意是划分,但我们可以转换成如何用1x2和2x1的小方块恰好填满整个NxM的方格。当我们把所有横向1x2的长方形块放满,剩下只能放2x1的长方形块。所以我们要做的就是求出放1x2的长方形块后剩余空格用2x1的长方形块恰好能放慢的方案数。
这道题最奇妙的思路在于,dp的状态表达,f[i][j]表示当前处理到第i列,(强调,是从0开始算的)前i-1列已经全部处理完(不能再动前i-1列的方块了)j是第i列的状态,如果为1说明第i列有来在i-1列的1x2的长方形块的伸出,如果为0就表示没有伸出,记住,前i-1列的长方形块的位置已经固定了。
我们最后输出f[m][0]表示0–m-1共m列已经完全处理完毕,第m列状态为0(前m-1列完完整整,第m-1列没有伸出到第m列的)。所以要求第m-1列要合法。
因为是dp,所以一般来说f[i]肯定和f[i-1]有关,是从f[i-1]延展过来的。
根据上面的分析,我们得出f[i-1]的长方形块的排放要合法,但输出是通过第i列,所以我们设第i-1列的状态为k(第i-1列捅出多少个小方块),第i列状态为j(第i-1列捅出多少小方块),且要满足第i-1列的方块排放方式合法:不存在奇数个连续方块&&第i-1的状态与第i的状态不冲突
关于合法细说一些:
- 如何判断第i-1列不存在奇数个连续空格,第i列的状态为j,如果为1表示从i-1列捅出来的,既然是从i-1列捅出来的,那么2x1还有半截留在了第i-1列,第i-1列的状态为k,是从i-2列捅出来的,那么上面属于不同列产生的两个状态组合在一起就是j|k,所以我们只要判断组合后的j|k是否存在奇数个连续空格就行。
2.(这个其实先判断比较好) 而如何判断第i-1的状态与第i的状态不冲突,和上面同样的道理第i列的状态为j,如果为1表示从i-1列捅出来的,既然是从i-1列捅出来的,那么2x1还有半截留在了第i-1列,如何恰好此时第i-2列捅出来的地方和这半截重叠了就冲突了,也就是说当j=1是,k不能等于1,其余都满足。取反,那么合法的情况就是k&j==0。
这里j,k一个为0,一个为1好想,那如果都是0不就重叠了吗?实际不是的:
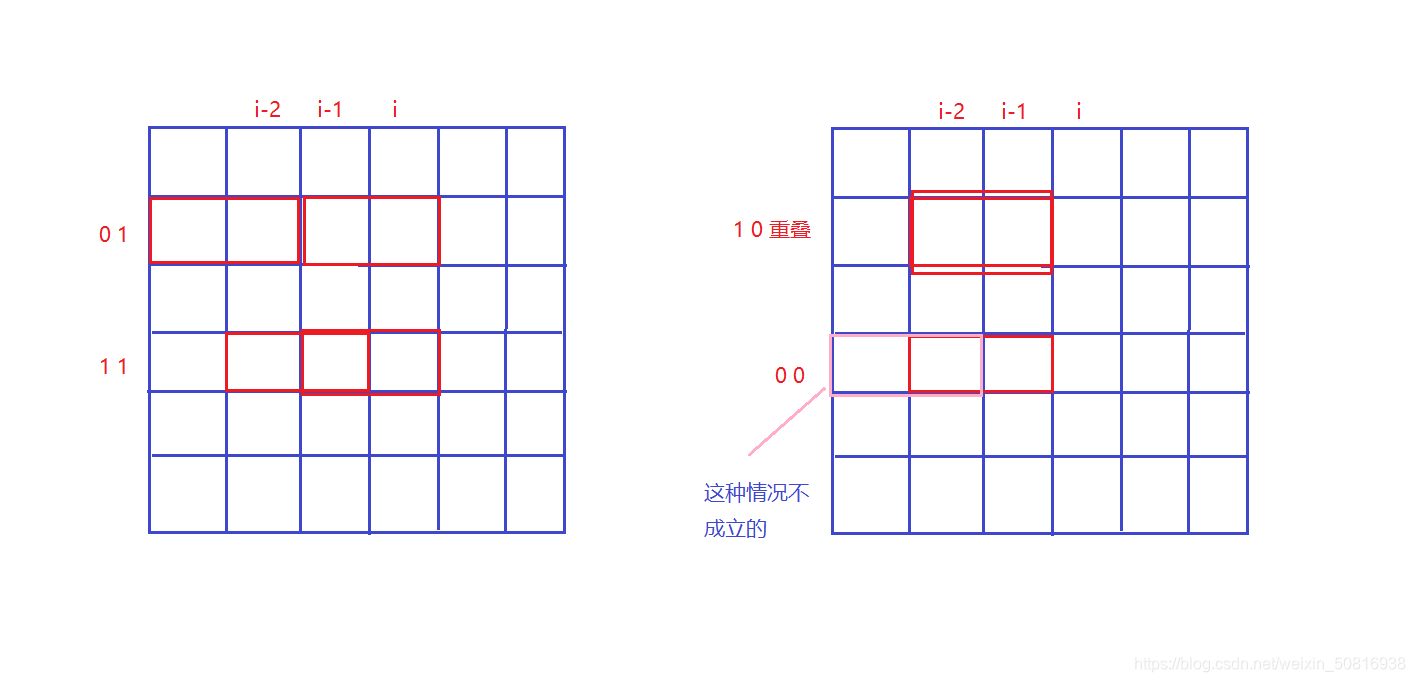
我为啥觉得这种情况是不成立的:个人理解,f[i]从f[i-1]来,f[i-1]从f[i-2],那么在f[i-1]从f[i-2]来的过程中,其实和f[i]从f[i-1]来的合法性判断一样,0 0这种情况就是合法性判断的第2个,所以这种情况在之前就已经被舍弃掉了,自然不会出现,所以之间j&k= =0就行。
为了节省时间,我们先对当前状态满足不存在奇数个连续空格进行初始化,然后再对合法条件下的j,k状态进行配对,最后再进行计算。
详细的一些注释我在代码中提现吧。
关于f[0][0]=1我查到的解释是说f[0][0]表示第0列状态为0,f[0][0]就是-1列满足题意的方案数,但是-1列是不存在的,所以没法放,整个也算一种方案,但我感觉也挺离谱。
所以初始化定义真的很神奇。
实在找不到什么实际意义来对他进行说明了,暂时给的解释就是dp的运作时通过对上一层状态进行叠加实现的,所以初始要给一个状态,就变成了f[0][0]=1。
感觉说了和没说没什么区别,等我以后相通了再来补充把。
白嫖的状态图:
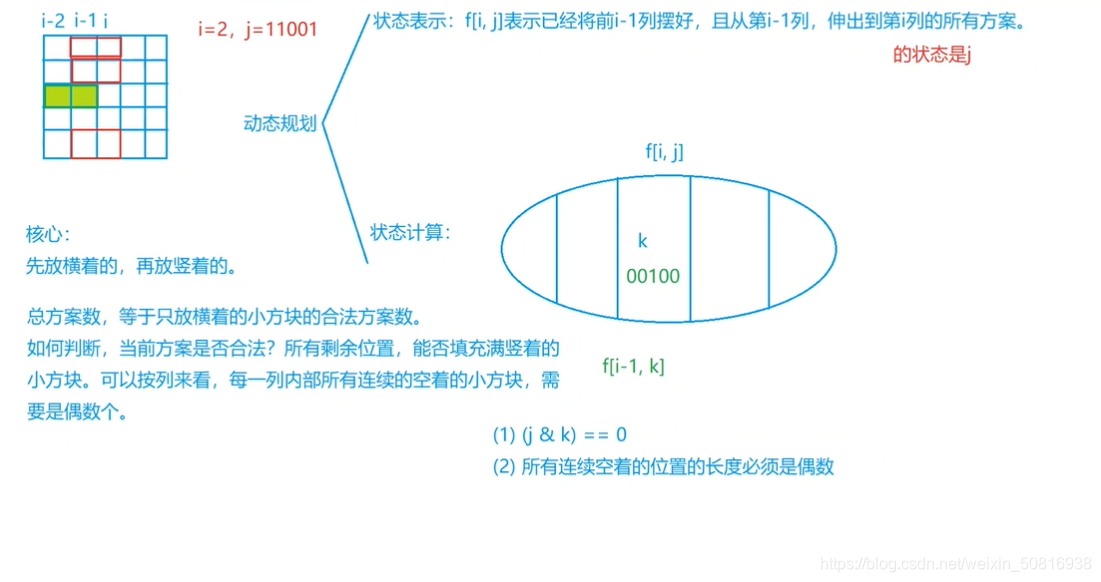
对于细节进行一些解释:
- 1 << n,有n行,n行有2n种状态,每个小方格都有两种选法,1或者0、
- j & k) == 0 && noteven[j | k],第i-1列合法性的判断,这个往上翻有说。
#include<iostream>
#include<vector>
#include<cstring>
using namespace std;
const int N = 2500;//2^11=2084
long long f[12][N];//如果m==11,那就是处理到第12列,每一列最多有2^11种状态
bool noteven[N];//判断当前状态是否不存在奇数个连续空格
int main()
{
int n, m;
while (cin >> n >> m && n | m) {
//n为行,m为列
//初始化1:状态是否不存在奇数个连续空格
for (int i = 0; i < 1 << n; i++) {
int cnt = 0;
bool isvaild = true;
for (int j = 0; j < n; j++) {
if (i >> j & 1) {
if (cnt & 1) {
isvaild = false;
break;
}
else cnt = 0;//发现非空格,cnt置为0,继续参与后面空格个数的计算
}
else cnt++;
}
if (cnt & 1) isvaild = false;
//这一步不能缺,因为最后可能连续几个都是空格,没出现非空格无法参与上面对isvaild的修改
noteven[i] = isvaild;
}
//初始化2:
vector<int>v[N];
for (int j = 0; j < 1 << n; j++)
for (int k = 0; k < 1 << n; k++)//满足题意的j,k的匹配
if ((j & k) == 0 && noteven[j | k])//第一个是第i列和i-1列不冲突,第二个是第i-1列为奇数,因为是从0开始计数的,0--i-1就是前i列,所以第i-1列满足就行
v[j].push_back(k);
//计算
memset(f, 0, sizeof f);
f[0][0] = 1;//初始化
for (int i = 1; i <= m; i++)
for (int j = 0; j < 1 << n; j++)
for (auto x : v[j]) f[i][j] += f[i - 1][x];
cout << f[m][0] << endl;//第m列状态为0,第m-1列没有捅出来的,也就是说前m列(0--m-1)恰好放满。
}
return 0;
}
有啥细节没涉及的可以翻翻这份题解,说不定有帮助。
最短Hamilton路径
题目链接–最短Hamilton路径 这题思路比之前那题好理解多了,但也不好想,尤其是如何保证每条路径每个节点只经过一次。
白嫖y总的状态图
简单说一下好了:
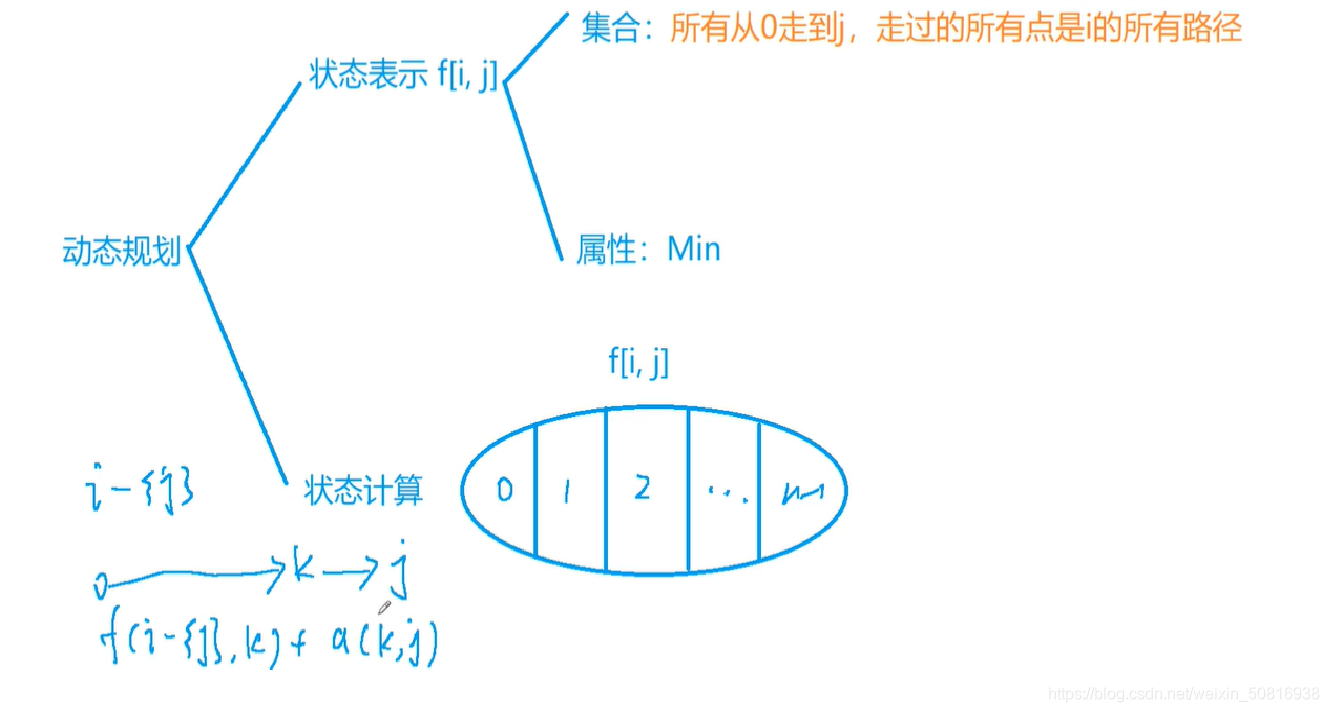
f[i][j]表示从0到j点,且路径为i的二进制表示的最短路径
比如f[2][3], 2(10)=10(2),也就说明f[2][3]存储的是从0节点到3节点的,路径为2的最短距离,路径2表示该条路线只1节点(i的二进制表示中,1表示经过该节点,0表示不经过,00101,就是经过0,2节点)。
最后输出f[(1<<n)-1][n-1]就是经过所有节点,0–n-1节点的最短距离。
状态转移:对于f[i][j],我们肯定是通过该路径的部分路径转移过来的,因为已经告诉你任意两点之间的距离(任意两点都有路径!!),所有我们想到的是把我们要求的这条路径距离中的终点剔除。剔除终点的路径所代表的十进制数坑定比当前路径代表的十进制数小,所有是已经被更新的。然后保证当前路径是从剔除终点(j)后形成的路径中的任意一个点(k)走到终点的。
f[i][j]=min(f[i][j],f[i-(1<<j)][k]+w[j][k]);
#include<iostream>
#include<cstring>
using namespace std;
const int N = 20, M = 1 << N;
int dist[N][N], f[M][N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
cin >> dist[i][j];
memset(f, 0x3f, sizeof f);
f[1][0] = 0;//只经过0节点,0-0的距离是0,初始化
for (int i = 1; i < 1 << n; i++)//f[i][j]表示从0走到j,经过节点(路径)是i的二进制
for (int j = 0; j < n; j++)
if (i >> j & 1)//判断该点是否出现在路径上
for (int k = 0; k < n; k++)//k是路径i-(1<<j)上的任意一点,通过这点可以之间到j
if ((i - (1 << j)) >> k & 1)
f[i][j] = min(f[i][j], f[i - (1 << j)][k] + dist[j][k]);
cout << f[(1 << n) - 1][n - 1];
return 0;
}
两道状态压缩得题目总结看来状态压缩最常用得方法就是通过数得二进制来表达状态。
树形DP
没有上司的舞会
f[i][j]表示当前树的根节点为i,j表示当前选法的状态,如果j为0表示当前方案不选根节点i,如果为1表示选当前方案选根节点,因为题目要求每一个参会成员的直系上司都不参加宴会,所有如果当前根节被选,状态为1,那么他的直系下属都不能参加,也就是直系下属的状态为0f[x][1] += f[e[i]][0];,如果当前根节点不选,状态为0,那么他的直系下属可参加可不参加,那就选择一个最大的情况加上就好f[x][0] += max(f[e[i]][0], f[e[i]][1]);
先递归再叠加,因为计算顺序要从底层到顶层,只有底层没有孩子节点。

#include<iostream>
#include<cstring>
using namespace std;
const int N = 6005;
int h[N], e[N], ne[N], idx;
int f[N][2];//两种状态,0,1;
bool has_father[N];//找根节点
void add(int x, int y)
{
e[idx] = x;
ne[idx] = h[y];
h[y] = idx++;
}
void dfs(int x)
{
for (int i = h[x]; i != -1; i = ne[i]) {
dfs(e[i]);
f[x][1] += f[e[i]][0];
f[x][0] += max(f[e[i]][0], f[e[i]][1]);
}
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i++)
cin >>f[i][1];
memset(h, -1, sizeof h);
for (int i = 0; i < n - 1; i++) {
int L, K;
cin >> L >> K;
add(L, K);
has_father[L] = true;
}
int root = 1;
while (has_father[root]) root++;
dfs(root);
cout << max(f[root][0], f[root][1]);
return 0;
}
记忆化搜搜
没太感受到记忆化搜索是啥,感觉这题更像dfs
状态表示:当前位置设为(x,y),滑雪者可以上下左右四个方向走,对应下一步的位置为(nx,ny),直接深搜,一直搜索直到上下左右四个方向都走不了(非降低或者到边界了)说明这条路径走到尽头的,返回1。从(1,1)到(n,m)以每个节点为起点搜索,res存储从任意点出发的最长路径。
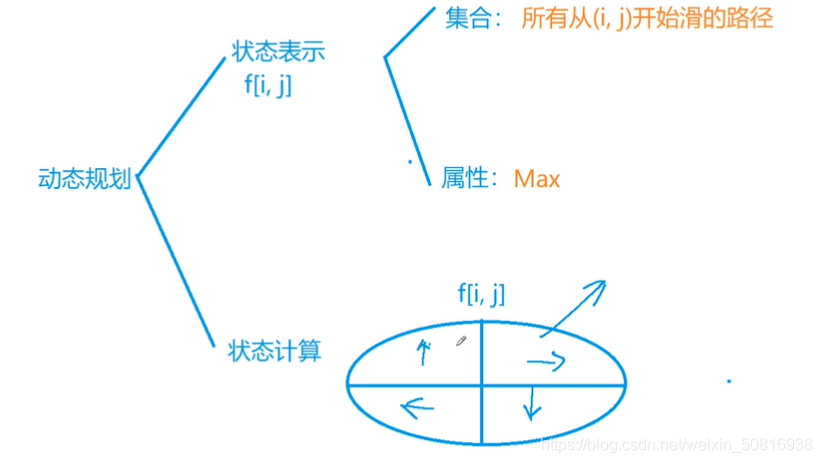
滑雪
#include<iostream>
#include<cstring>
using namespace std;
const int N = 310;
int f[N][N], h[N][N], n, m;
int ax[4] = {
-1,1,0,0 }, ay[4] = {
0,0,-1,1 };
int dfs(int x, int y)
{
if (f[x][y] != -1) return f[x][y];
//说明在之前的搜索过程中已经通过这个节点往下搜索了,
//此时f[x][y]储存的就是以当前点为起点的最远距离,不用重复搜索了
f[x][y] = 1;
for (int i = 0; i < 4; i++) {
int nx = x + ax[i], ny = y + ay[i];
if (nx >= 1 && nx <= n && ny >= 1 && ny <= m && h[nx][ny] < h[x][y])
f[x][y] = max(f[x][y], dfs(nx, ny)+1);
}
return f[x][y];
//这一段解释一下,刚开始有个地方没绕出来一直理解不了,之前在想每次f[x][y]=1,
//那么f[x][y] = max(f[x][y], dfs(nx, ny)+1);在比较的时候f[x][y]不是每次都变成1了吗,有什么意义,我真傻真的。
//其实f[x][y]开始置为1,但通过上下左右四次循环,每一次把返回值赋给f[x][y],然后继续下一个方向的搜索,这时候f[x][y]不为1了
//f[x][y]=1是放在方向循环外面的,所以f[x][y]最后就是以当前节点为起点出发的最长距离。
//每当到尽头的时候,四个循环都循环不了,跳出循环,然后就可以返回f[x][y],节点尽头f[x][y]=1;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> h[i][j];
memset(f, -1, sizeof f);
int res = 0;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
res = max(res, dfs(i, j));
cout << res;
return 0;
}
六天总算把基础课动态规划这一讲搞定。。。其实之前的有点忘了hh,等贪心结束就来复习,冲啊!!