[深度学习论文研读] Inter-slice Context Residual Learning for 3D Medical Image Segmentation
基于层间上下文残差学习的三维医学图像分割
论文:https://arxiv.org/abs/2011.14155v1
代码: https://github.com/jianpengz/ConResNet
发表时间:2020 IEEE-TMI
一、基本介绍
1.1问题动机
自动化和精确的三维医学图像分割在帮助医学专业人员评估疾病进展和制定快速治疗计划方面起着至关重要的作用。虽然深度卷积神经网络(deep convolutional neural networks,DCNNs)已被广泛应用于这一领域,但这些模型的精度仍有待进一步提高,主要是由于其对三维环境感知的能力有限。这篇文章提出了三维上下文残差网络(ConResNet)用于三维医学图像的精确分割。该模型由编码器、分段解码器和上下文剩余解码器组成。作者设计了上下文剩余模块,并用它在每个尺度上桥接两个解码器。每个上下文残差模块包含上下文残差映射和上下文注意映射,形式化的目标是明确地学习片间上下文信息,而片间上下文作为一种注意来提高分割精度。作者在MICCAI 2018脑肿瘤分割(BraTS)数据集和NIH胰腺分割(胰腺CT)数据集上评估了该模型。结果不仅证明了所提出的3D上下文剩余学习方案的有效性,而且表明所提出的ConResNet在脑肿瘤分割方面比6种顶级方法和7种胰腺分割方法更准确。
1.2医学图像分割:
医学图像提供了活体解剖或功能的视觉表征,这对于临床分析和医学干预是必不可少的。三维医学图像分割的目的是预测每个体素的语义类别(即特定的器官或损伤),是计算机辅助诊断(CAD)的基础和关键任务。因为准确的器官或肿瘤的分割不仅有助于诊断,而且在评估疾病的严重程度和预后方面都有价值。然而,由于软组织对比度低以及器官和肿瘤在形状、大小和位置上的异质性,这一分割任务极具挑战性。此外,由于医学数据的获取和标注成本较高,通常缺乏足够的标注数据来训练分割模型,这使得三维医学图像的分割任务更加具有挑战性。
近年来,深度卷积神经网络(DCNNs)在图像分割方面取得了惊人的成功。为了增强(DCNNs)对医学图像分割的能力,人们做了很多尝试。例如,编码器-解码器体系结构通过多种方式进行了改进,以保持底层的详细信息,并获得清晰的对象边界(Unet),利用空间金字塔池化的方法来挖掘多尺度信息,在分割模型中引入了Atrous 卷积,有效地扩展了感受野,并且一些注意力学习机制已经被引入到分割模型中,使它们能够更多地关注特定的位置或通道。在3D医学图像分割任务中,3D DCNNs比2D DCNNs有显著的改进,因为它们能够探索包含在切片上的上下文信息,这对更好的分割性能有显著贡献。因此,作者认为,通过更有效地捕捉和利用层间的上下文信息,可以进一步提高三维医学图像分割的准确性。
(atrous卷积)
二、网络结构
2.1 解决思路
提出了三维上下文残差网络(ConResNet)来精确分割三维医学图像。ConResNet具有一个编码器-解码器架构,分别包含一个用于特征提取的编码器和两个用于生成分割掩码和片间上下文残差的解码器。上下文残差(ConRes)解码器将分割解码器产生的相邻切片的残差特征映射作为输入,同时反馈给分割解码器作为一种注意力引导,旨在提高分割模型有效感知和使用层间上下文信息的能力。ConRes解码器的设计在概念上具有通用性,兼容任何现有的基于DCNNs的3D医学图像分割模型。
2.2文章的主要贡献总结如下:
建议将ConRes解码器添加到一个encoder decoder结构中,明确提高模型的3D上下文感知能力,从而提高分割精度。
设计了上下文残差模块,在各个尺度上用于分割解码器和ConRes解码器之间,同时进行上下文残差映射和上下文注意映射。
提出了一种精确的3D医学图像分割模型,称为ConResNet,该模型在脑肿瘤分割任务和胰腺分割任务上的性能均优于最先进的方法。
2.3主要方法
上下文学习:
目标上下文提供了其周围环境的信息,因此是语义分割的必要条件。上下文学习的策略有很多,大致可分为三类。首先,为了探索多尺度的上下文信息,就有人采用了不同尺度的金字塔空间池化策略来聚集多尺度的全局信息。将不同扩张速率的atrous金字塔池化引入并行分支,进行多尺度表征聚合。其次,为了扩大感受野,用扩张率可调的atrous 卷积代替了传统的卷积,在许多计算机视觉任务中,如分割、检测和超分,都表现出了优越的性能。利用大型卷积核捕捉丰富的全局上下文信息,这有利于密集的逐像素预测任务。第三,提出了许多基于注意的方法来过滤外部信息。通过显式建模卷积特征的通道相关性,自适应地重新校准通道特征响应。设计了一个具有自底向上和自顶向下前馈结构的注意模块来学习软注意权重。通过使用高级特征来生成低级层次的注意图,来开发深层网络的内在自我注意能力。
残差学习:
残差学习可以追溯到“Deep residual learning for image recognition”的开创性工作,从那时起,它已成功应用于许多计算机视觉任务,包括分类、分割、检测和跟踪。残差学习的思想是使用直接从输入跳转到输出的跳跃连接来学习输入和输出特征映射之间的残差。通过跳跃连接,残差学习可以消除退化问题,从而可以训练多达数百、甚至数千层的深度网络。本文提出的ConRes解码器的目标是感知相邻切片之间的特征残差,从而增强了模型利用3D上下文信息进行分割的能力。
2.3结构详解

(a)提议的ConResNet模型的图表,它有一个编码器-解码器架构,包括一个共享编码器(橙色),一个分割解码器(蓝色),和一个ConRes解码器(绿色)。
(b)上下文残差模块。
①共享的编码器(Shared Encoder)
在提议的ConResNet中,共享编码器由9个剩余块组成,每个块由两个3 × 3 × 3卷积层和一个从输入到输出的跳跃连接组成。由于GPU内存有限,必须用非常小的批处理大小来训练网络。因此,为了加快训练过程,使用组数为8的组归一化,它对批大小的规模不敏感,对每一层的激活进行调整和缩放。此外,使用权值标准化算法,通过对卷积层的权值进行归一化来加速微批处理训练。如图所示,编码过程可分为五个阶段。在第一阶段,输入由一个包含32个核的卷积层和一个残差块处理。在接下来的三个阶段中的每一个阶段,数据都由一个步幅为2具有双重核的卷积层和两个剩余块处理。因此,逐步将特征映射下采样到输入大小的1/8,同时将通道数从32个增加到256个,从而扩大了感受域,减少了计算量。在最后阶段,使用了两个剩余块,它们使用了扩张率为2的atrous卷积,以进一步扩大感受野,同时保持特征分辨率的形状和边缘的更多细节。
②双重解码器(Dual Decoders)
ConResNet包含两个解码器,一个分割解码器和一个ConRes解码器。由分割解码器生成分割掩码或由ConRes解码器生成剩余掩码包括三个阶段。在每一阶段,提出了一个上下文残差模块来连接分割解码器和ConRes解码器。具体来说,分割解码器首先使用三线性插值对之前的特征图进行上采样,然后使用元素求和将它们与从编码器传递过来的低级特征融合。融合特征的上下文残差传输到ConRes解码器。ConRes解码器将分割解码器传递的上下文残留特征与前一层传递的特征进行融合,并对其进行细化以预测残留掩码。此外,ConRes解码器生成的片间上下文残差信息被传输回分割解码器作为注意引导,以提高分割解码器感知3D上下文的能力。为了匹配编码器中的通道数量,我们在每次上采样操作后都将通道减半。因此,得到了一个分割掩码和对应的片间上下文残留掩码的每个输入量。
③上下文残差模块(Context Residual Module)
它由两个主要路径组成,即分割路径(顶部)和上下文残差路径(下方)。在分割路径中,输入是编码器中来自上一层的分割特征和来自同尺度层的低级特征的按元素相加,输出是分割特征。在上下文残差路径中,输入是来自上一层的上下文残差特征,输出是上下文残差特征。设计了上下文残差映射和上下文注意映射两种策略来连接两条路径,以更好地进行上下文感知和语义分割。
三、网络模型主要应用及结果
4.1 实验中使用的分割数据集
两个数据集:
Brats2018
胰腺数据集
4.2主要结果
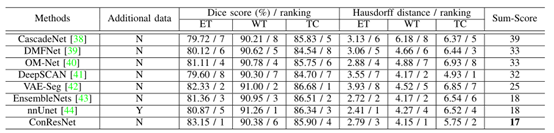
Brats2018上,与最先进的分割方法的性能比较:

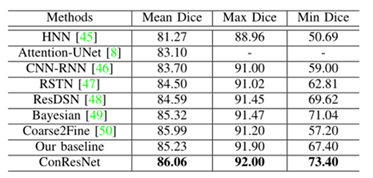
在胰腺数据集上和最先进方法的比较:

4.4 消融实验:
为了验证该设计的有效性,在BraTS数据集上进行了消融实验。为了便于定量评价,从训练集中随机抽取35例,形成局部验证集。因此,在验证集上评估时,有250个训练案例(35个案例),在测试集上评估时,有285个案例(66个案例)。下表列出了ConResNet在本地验证集上有/没有上下文残差映射和上下文注意映射的性能。
(保持其他设置,如网络宽度、深度和训练策略相同,以确保公平的比较。)

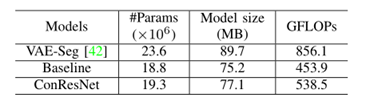
不同模型的参数个数、模型大小和GFLOPS(每秒执行多少次浮点运算)
六、总结
这篇文章中,作者提出了带有显式三维上下文学习的ConResNet,以提高DCNNs感知层间上下文的能力,以准确分割体积医学图像。在BraTS数据集和胰腺- ct数据集上评估了该模型。结果表明,所提出的ConResNet在脑肿瘤分割和胰腺分割任务上都优于最先进的方法。消融研究也证明了所提出的上下文学习的有效性,包括上下文剩余映射和上下文注意映射。在未来的工作中,作者计划将预测的残差掩模作为突出易出错区域的先验,并将其与输入图像连接起来作为另一个分割网络的输入,以获得细化的结果。此外,作何将研究如何将提出的3D上下文学习与自监督学习相结合,从而将这项工作扩展到半监督分割问题。