1 Motivation
Machine learning often break down when forced to make predictions about data for which little supervised information is available.
One-shot learning: we may only observe a single example of each possible class before making a prediction about a test instance.
2 Innovation
This paper uses siamese neural networks to deal with the problem of one-shot learning.
3 Adavantages
- Once a siamese neural network has been tuned, we can then capitalize on powerful discriminative features to generalize the predictive power of the network not just to new data, but to entirely new classes from unknown distributions.
- Using a convolutional architecture, we are able to achieve strong results which exceed those of other deep learning models with near state-of-the-art performance on one-shot classification tasks.
4 Related Work
- Li Fei-Fei et al. developed a variational Bayesian framework for one-shot image classification. (变贝叶斯框架)
- Lake et al. addressed one-shot learning for character recognition with a method called Hierarchical Bayesian Program Learning(HBPL). (分层贝叶斯程序学习)
5 Model
Siamese Neural Network with L fully-connected layers
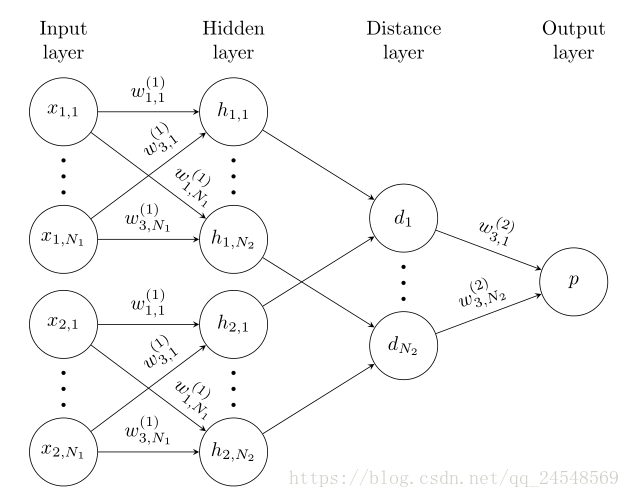
This paper tries 2-layer, 3-layer or 4-layer network.
: the hidden vector in layer l for the first twin.
: the hidden vector in layer l for the second twin.
for the first L-1 layers:
for the last layer:
where is the sigmoidal activation function.
Siamese Neural Network with CNN
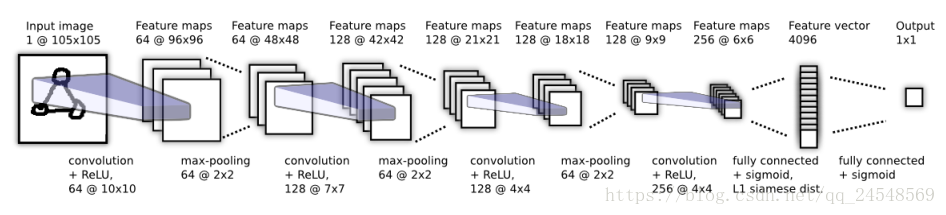
first twin: (conv
ReLU
max-pooling)*3
conv
FC
sigmoid
second twin: (conv
ReLU
max-pooling)*3
conv
FC
sigmoid
where k is the k-th filter map, is the convolutional operation.
for the last fully connected layer:
6 Learning
Loss function
M: minibatch size
: the labels for the minibatch, if
and
are from the same classs,
, otherwise
loss function: regularized cross-entropy
Optimizaiton
: learning rate for j layer
: momentum for j layer
:
regularization weights for j layer
update rule at epoch T is as follows:
where is the partial derivative with respect to the weight between the j-th neuron in some layer and the k-th neuron in the successive layer.
Weight initialization
Siamese Neural Network with L fully-connected layers
W of fully-connected layers: normal distribution, zero-mean, standard deviation
(fan-in =
)
b of fully-connected layers: normal distribution, mean 0.5, standard deviation 0.01
Siamese Neural Network with CNN
W of fully-connected layers: normal distribution, zero-mean, standard deviation 0.2
b of fully-connected layers: normal distribution, mean 0.5, standard deviation 0.01
w of convolution layers: normal distribution, zero-mean, standard deviation 0.01
b of convolution layers: normal distribution, mean 0.5, standard deviation 0.01
Learning schedule
Learning reates are decayed by
.
Momentum starts at 0.5 in every layer, increasing linearly each epoch until reaching the value
.
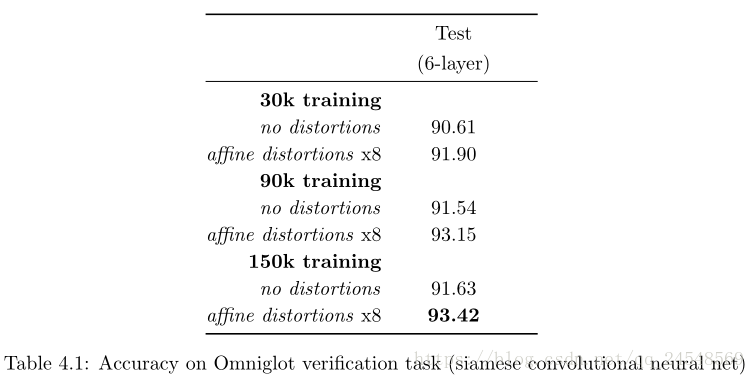
This paper trained siamese neural network with L fully-connected layer for 300 epochs, and siamese neural network with CNN for 200 epochs.
This paper monitored one-shot validatioin error on a set of 320 one-shot learning tasks. When the validation error did not decrease for 20 epochs, This paper stopped and used the parameters of the model at the best epoch according to the one-shot validation error.
Omniglot dataset
The Omniglot data set contains examples from 50 alphabets, and from about 15 to upwards of 40 characters in each alphabet. All characters across these alphabets are produced a single time by each of 20 drawers.


Affine distortions
This paper augmented the training set with small affine distortions. For each image pair , the paper generate a pair of affine transformations to yield , , and .
A sample of random affine distortions generated for a single character in the Omniglot data set.

Train
The size of mini-batch is 32. The samples of mini-batch is:

7 Experiment
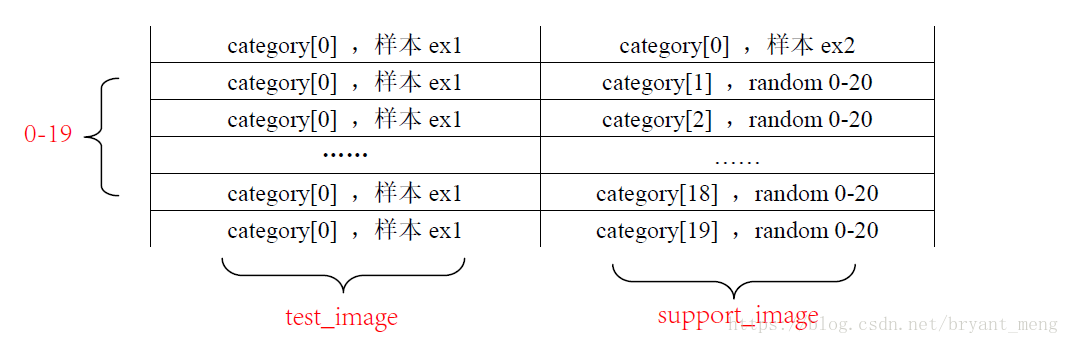
Test
The samples of test, N-way, the follow image shows 20-way.
Results
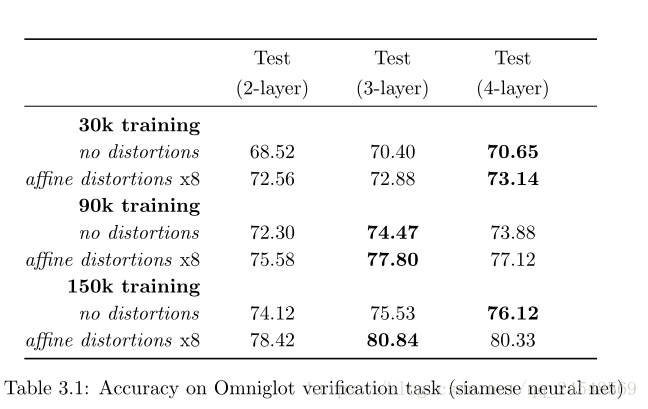
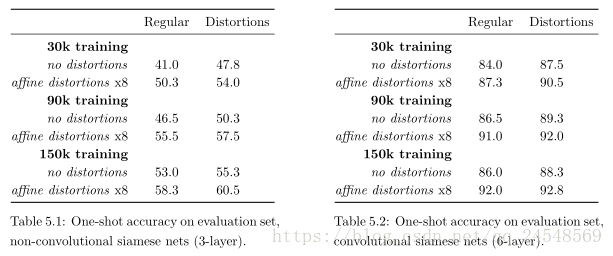
Siamese Neural Network with L fully-connected layers
Siamese Neural Network with CNN
One-shot Image Recognition
Example of the model’s top-5 classification performance on 1-versus-20 one-shot classification task.

One-shot accuracy on evaluation set:
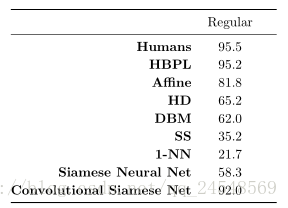
Comparing best one-shot accuracy from each type of network against baselines:
参考:https://blog.csdn.net/bryant_meng/article/details/80087079
code address: https://github.com/sorenbouma/keras-oneshot