本节数据重构内容有两部分,因为误解了学习安排,数据重构1的内容我已写入任务2中
数据重构是一项非常重要的数据分析步骤,当我们把手头上的数据清洗完成后,通过数据重构的方法对现有的数据特征进行组合,可视化化显示,可以分析出许多深层次的数据信息。pandas中数据重构的方法主要有groupby为主,通过与apply、agg、transform等方法组合,可以实现很多中数据重构应用,其中apply方法没有agg和transform方法快。
参考:Pandas教程 | 超好用的Groupby用法详解
pandas.DataFrame.groupby
pandas.DataFrame.groupby操作涉及拆分对象、应用函数和组合结果的某种组合。这可以用于对大量数据进行分组,并对这些分组进行计算操作。
它返回的是一个DataFramegroupby对象,而groupby的过程就是将原有的DataFrame按照groupby的字段划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的操作(如agg、apply等),均是基于子DataFrame的操作。

# 导入基本库
import numpy as np
import pandas as pd
df = pd.read_csv('result.csv')
del df['Unnamed: 0']
df.head()

一、计算泰坦尼克号男性与女性的平均票价
# 代码一
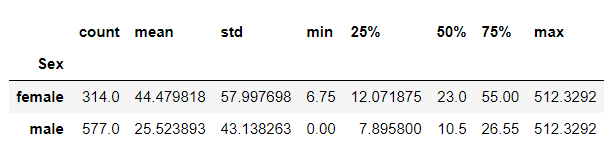
result = df.groupby('Sex')['Fare'].describe()
result
# 代码二
result = df.groupby('Sex')['Fare'].mean()
result
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
# 代码三
sex_fare_ave = df['Fare'].groupby(df['Sex']).mean()
sex_fare_ave
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
二、统计泰坦尼克号中男女的存活人数
# 代码一
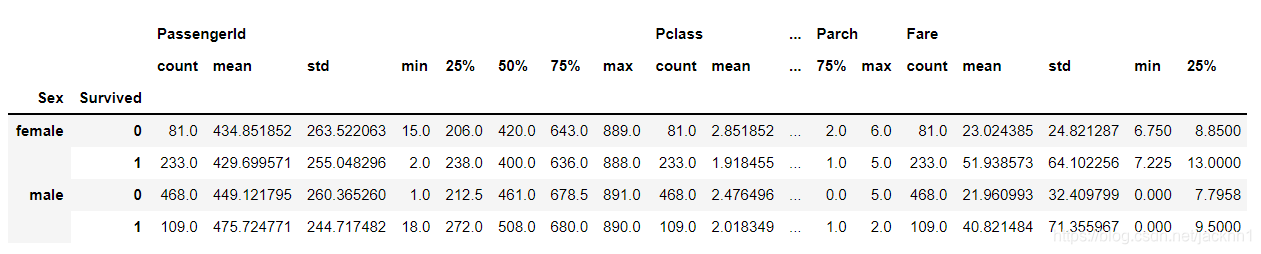
result2 = df.groupby(['Sex', 'Survived']).describe()
result2
# 代码二
result3 = df.groupby('Sex')['Survived'].sum()
result3
Sex
female 233
male 109
Name: Survived, dtype: int64
# 代码三
result3 = df['Survived'].groupby(df['Sex']).sum()
result3
Sex
female 233
male 109
Name: Survived, dtype: int64
三、计算客舱不同等级的存活人数
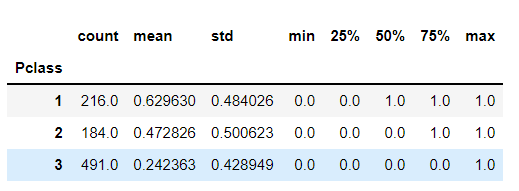
result3 = df.groupby('Pclass')['Survived'].describe()
result3.head()
# 代码一
result3 = df.groupby('Pclass')['Survived'].sum()
result3
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
# 代码二
result3 = df['Survived'].groupby(df['Pclass']).sum()
result3
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
思考:从任务一到三中,通过组合数据的方法,我们可以看到女性的存活率比男性高,并且头等舱的存活率超过了50%,平民舱的存活率最低不到25%
四、使用agg函数完成任务一任务二
男女平均票价
result = df.groupby('Sex')
result = result.agg({
'Fare' : 'mean'})
result

男女存活人数
result = df.groupby('Sex').agg({
'Survived' : 'sum'})
result
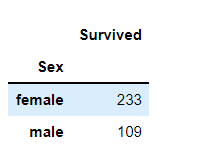
官方指南:pandas.core.groupby.DataFrameGroupBy.aggregate

agg是一个聚合函数,聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,不同于 numpy聚合函数(np.sum() //求和;np.prod() //所有元素相乘;np.mean() //平均值;np.std() //标准差;np.var() //方差;np.median() //中数;np.power() //幂运算;np.sqrt() //开方;np.min() //最小值;np.max() //最大值;np.argmin() //最小值的下标;np.argmax() //最大值的下标;np.inf //无穷大;np.exp(10) //以e为底的指数;np.log(10) //对数)
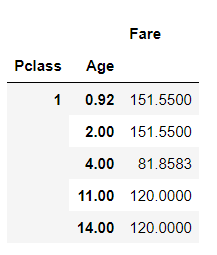
五、统计在不同等级的票中的不同年龄的船票花费的平均值
result5 = df.groupby(['Pclass', 'Age']).agg({
'Fare' : 'mean'})
result5.head()
六、将任务二和任务三的数据合并,并保存到sex_fare_survived.csv

七、得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数)
# 代码一
result7 = df.groupby(['Age',]).agg({
'Survived' : 'sum'})
result7.sort_values('Survived', ascending=False.iloc[0,:]
Survived 15
Name: 24.0, dtype: int64
# 代码二
survived_age = df['Survived'].groupby(df['Age']).sum()
survived_age[survived_age.values==survived_age.max()]
Age
24.0 15
Name: Survived, dtype: int64
# 总人数
surv_sum = df['Survived'].count()
print("sum of person:" +str(surv_sum))
precent = survived_age.max()/surv_sum
print("最大存活率:"+str(precent))
sum of person:891
最大存活率:0.016835016835016835